Introduction
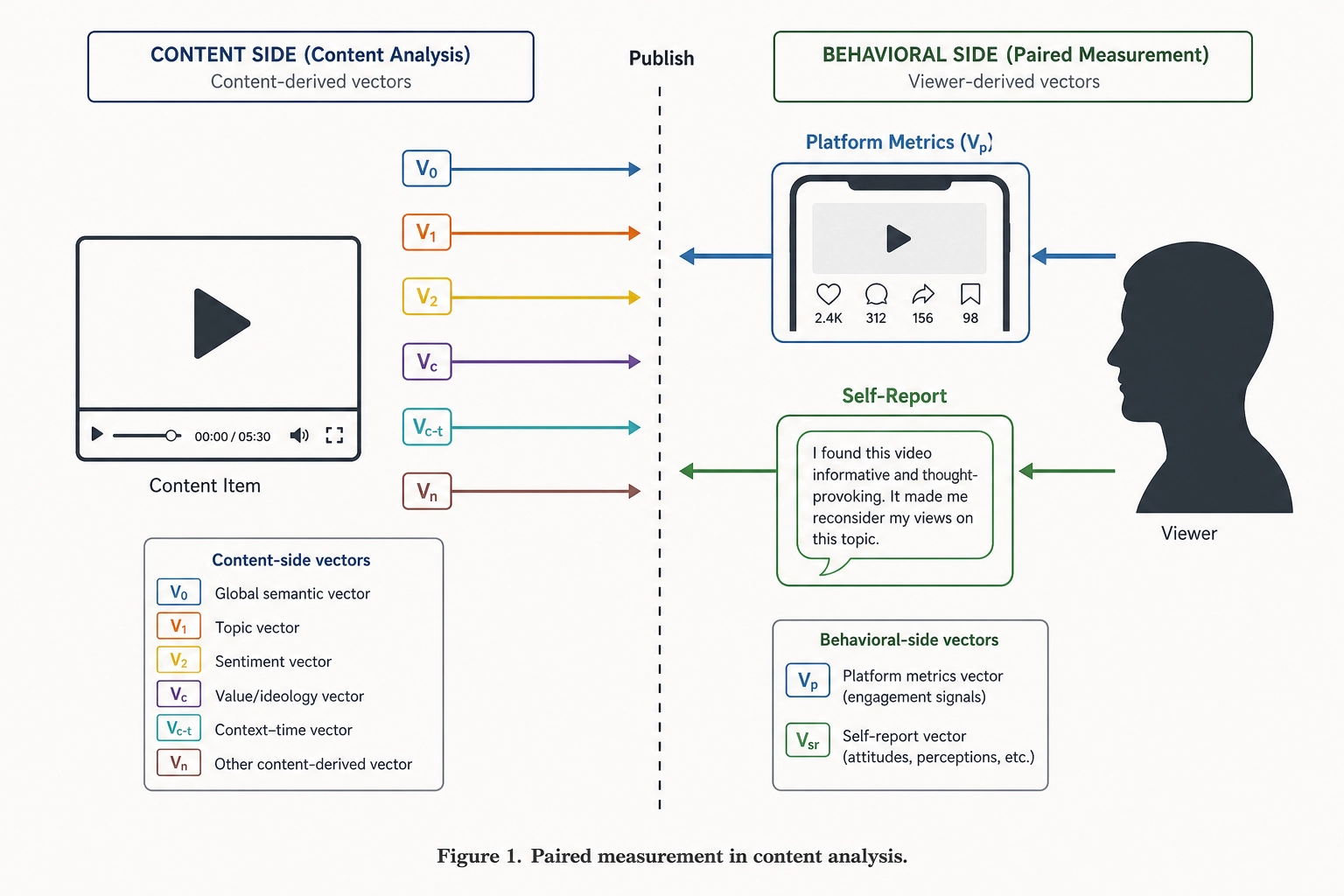
Chapter 5 specified the six vectors Khozai extracts from the content file: V₀ (25 physical channels), V₁ (16 first-order temporal channels), V₂ (12 second-order temporal channels), Vc (32 cognitive dimensions across 9 categories), Vc-temporal (24 cognitive-arc channels), and Vₙ (360 Glasser-area cortical predictions at 1 Hz). Every one of those vectors stops on the content side: they describe properties of the video, semantic content it carries, or predicted brain activation it would produce in an average viewer. None of them tells Khozai what actually happened after the video was published.
This chapter is about that second side. It describes the two operational subspaces Khozai uses to observe what viewers do with a published piece of content: Vₚ - the platform-metric vector, the platform-reported behavioral metrics - and the structured outputs of the self-report extraction pipeline, which reads viewer comments and produces machine-readable records of what those comments report. Both live in Behavioral Output Space - the formal space of outputs the brain produces that affect the body or the external world (Chapter 2 section 2.4). Both are how the framework gets paired data: a content file with its measured V-vectors on one side, and behavioral outcomes on the other. Without that pairing, the correlation engine in Chapter 8 has nothing to map content properties to.
How the chapter is organized. Section 1 walks through the twenty-two platform metrics in Vₚ. Section 2 walks through the three structured outputs of the self-report pipeline, with three worked examples. Section 3 enumerates the limitations of both channels. Section 4 connects the two channels back to the rest of the framework.
1. Vₚ - The Platform-Metric Vector
1.1. What Vₚ is and what it is not
Vₚ is the vector of platform-reported behavioral measurements Khozai collects after a piece of content is published. The Phase-5 Vₚ specification locks twenty-two metrics across three short-form vertical video platforms - TikTok, Instagram Reels, and YouTube Shorts - chosen because those are the surfaces Khozai is built around. Each metric is a number (or a small structured object, in the case of the retention curve) that the platform itself records and exposes through an API.
Per the spec’s section 1, every Vₚ entry is a consequence of a motor action a viewer performed: a finger swipe, a tap on a heart icon, a tap on a save button, a typed comment, a tap to share, a tap to follow. This places Vₚ specifically in the motor-output subspace of Behavioral Output Space - the subspace containing voluntary motor actions a viewer’s body produced. The spec uses “motor-output subspace” because Behavioral Output Space contains more than motor output (autonomic, endocrine, immune, and offline downstream consequences of viewing all live in Behavioral Output Space too), and Vₚ does not reach any of those. The implication for Khozai: when the framework reports that a content property correlates with a Vₚ outcome, the correlation is about motor behavior only. It is not a claim about what the viewer’s autonomic nervous system did, what hormones their body released, or whether they later bought the product.
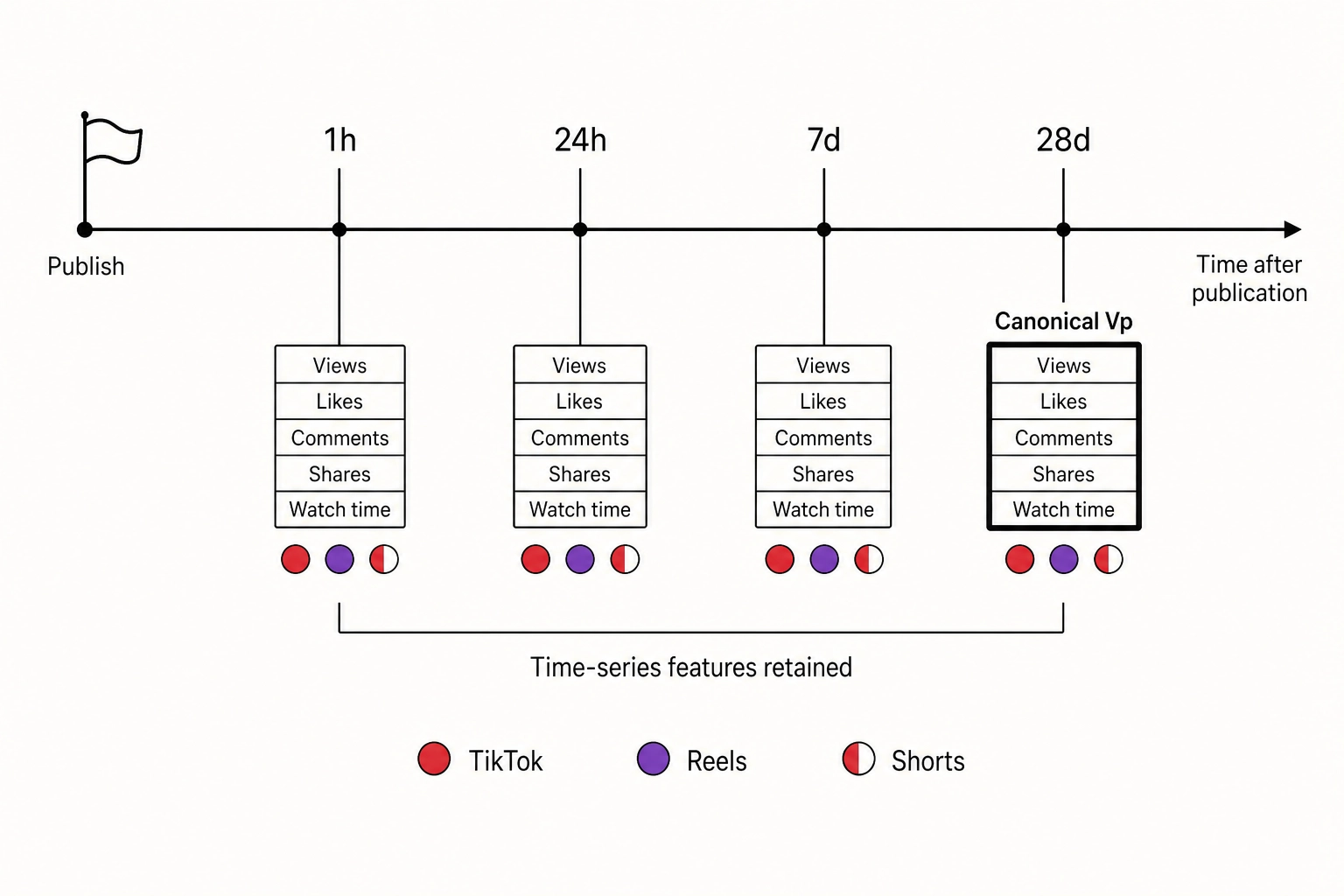
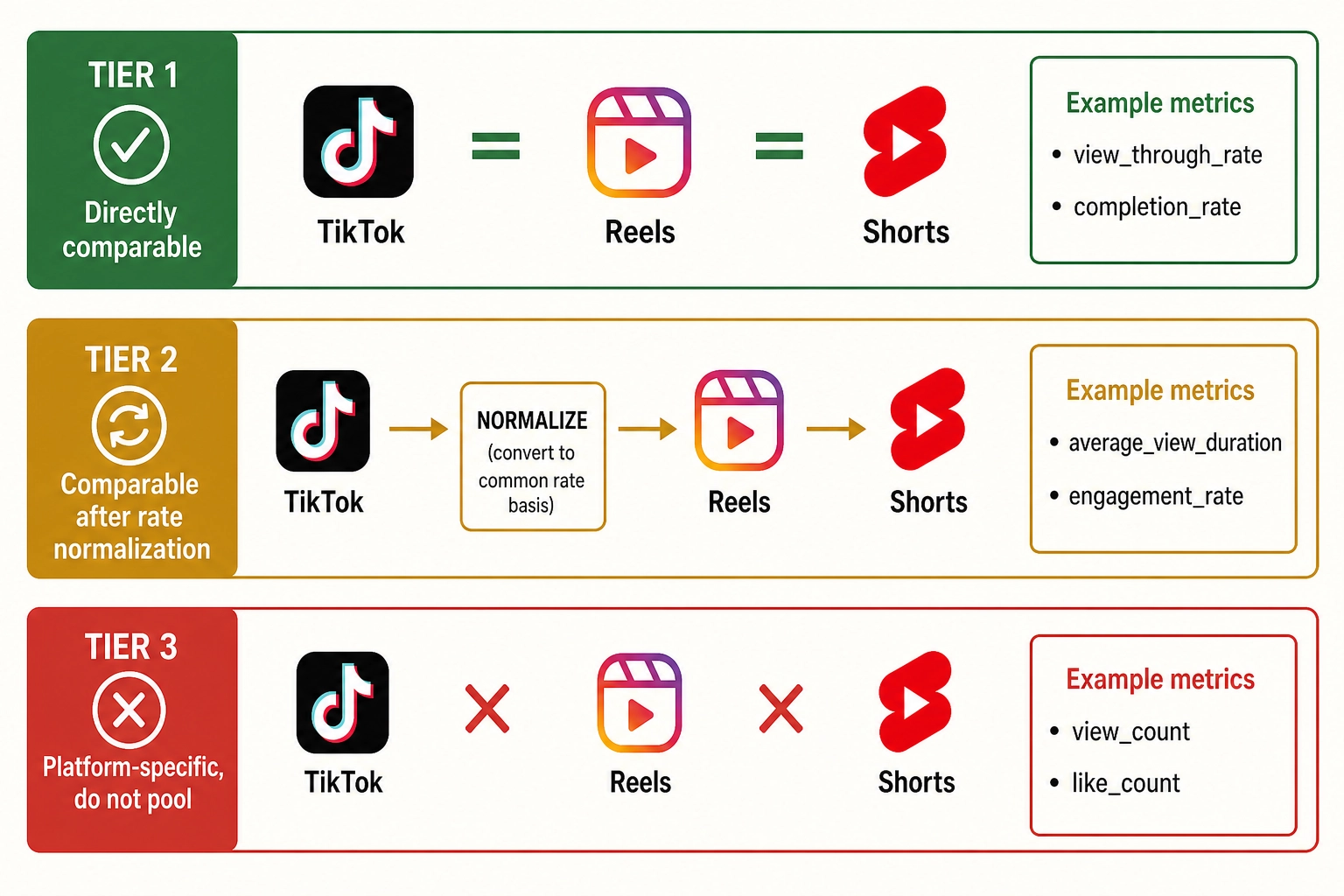
The collection convention is fixed by the spec’s section 3: every metric is sampled at four checkpoints relative to the publish timestamp - 1 hour, 24 hours, 7 days, and 28 days post-publish. The 28-day value is treated as the canonical Vₚ for correlation analysis; the earlier checkpoints are retained as time-series features. Each metric carries a platform tag (tiktok / reels / shorts), and the spec’s section 3 normalization tiers govern whether values can be pooled across platforms (Tier 1: directly comparable; Tier 2: comparable after rescaling to a rate; Tier 3: platform-specific, do not pool).
1.2. The five families of metrics
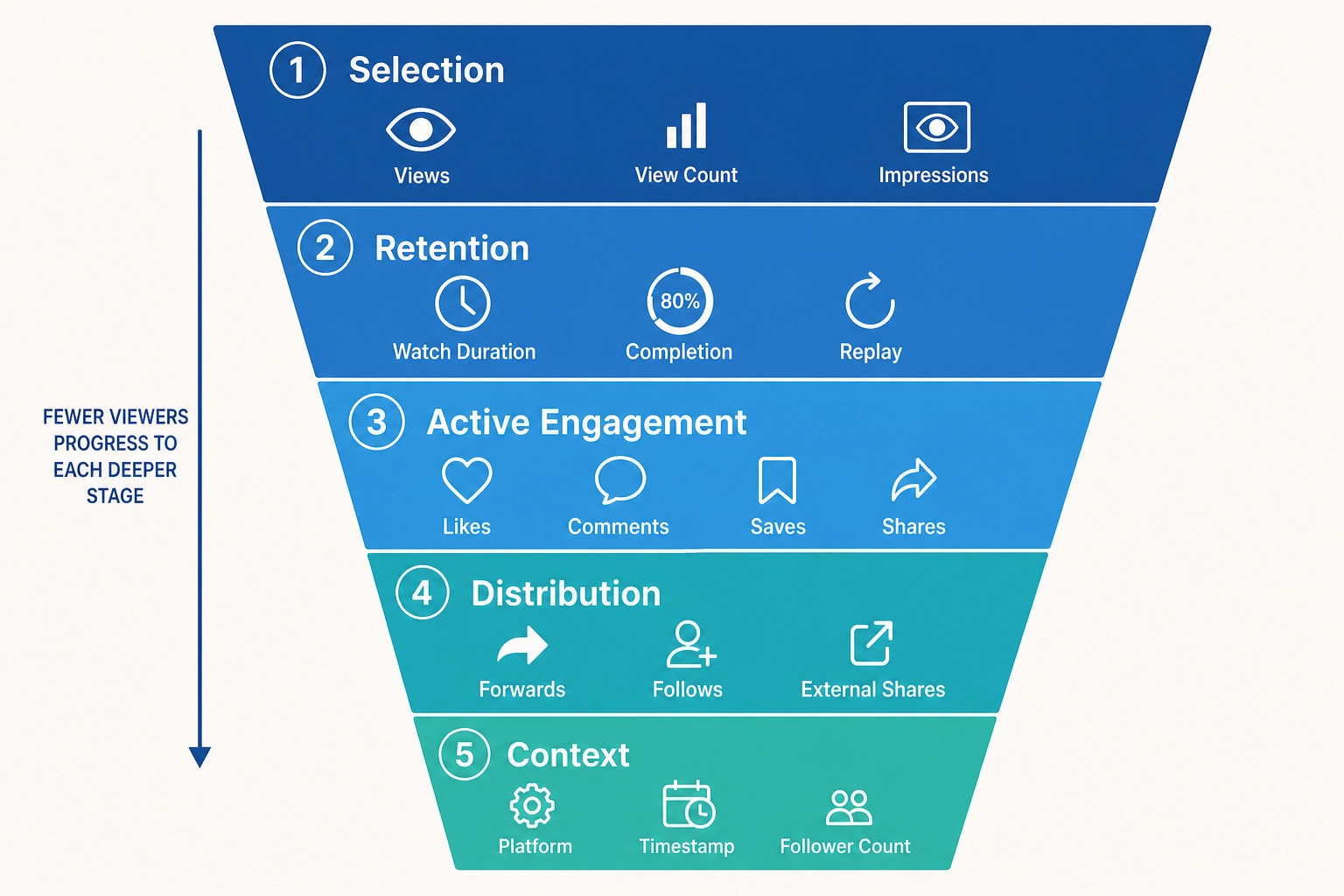
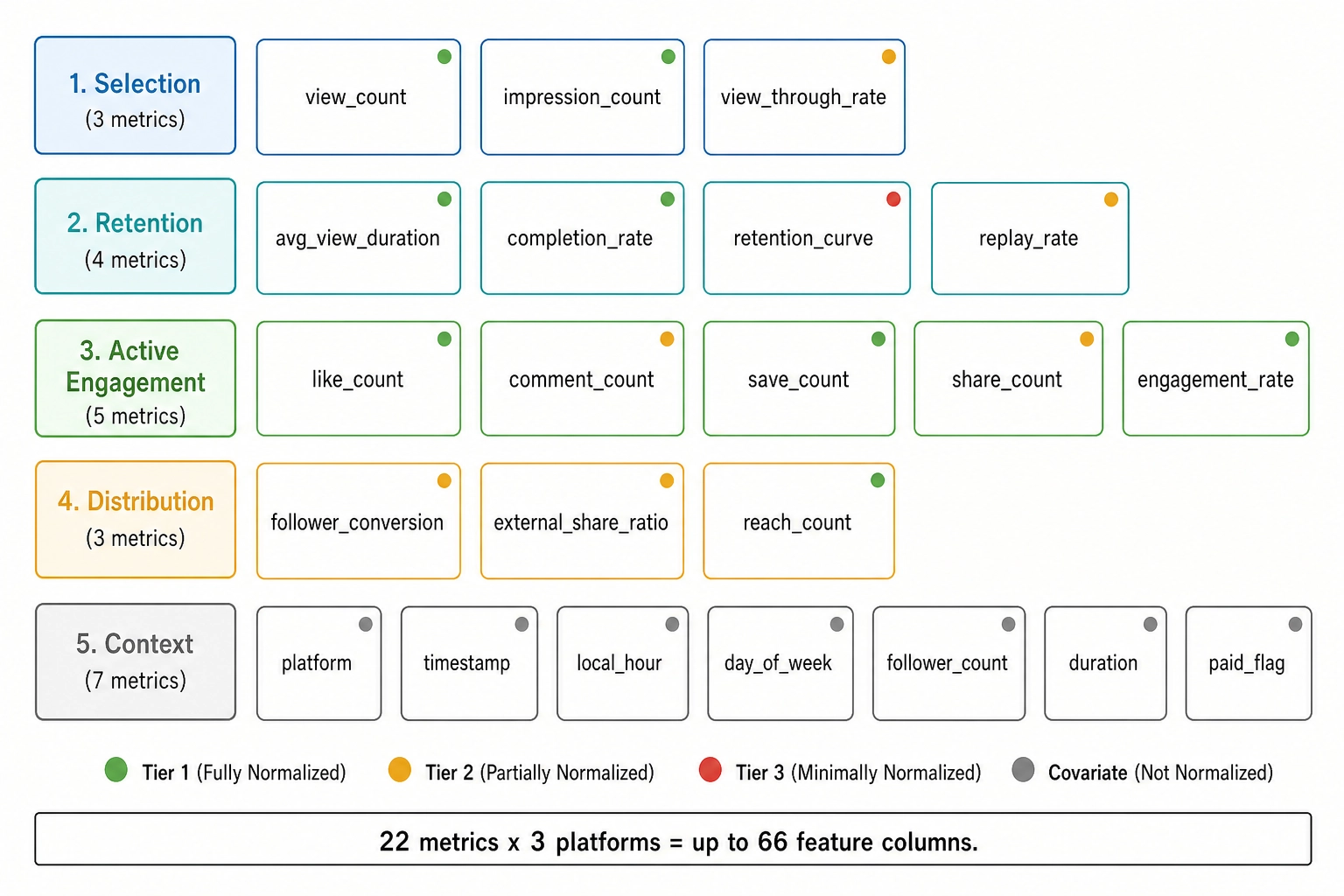
The twenty-two metrics are organized into five behavioral families, per the Phase-5 spec section 4. The families are not arbitrary - they trace the funnel a viewer’s behavior actually moves through, from the initial decision to commit attention to the eventual decision to redistribute the content.
1.2.1. Selection family - three metrics
Did the viewer commit to starting the content?
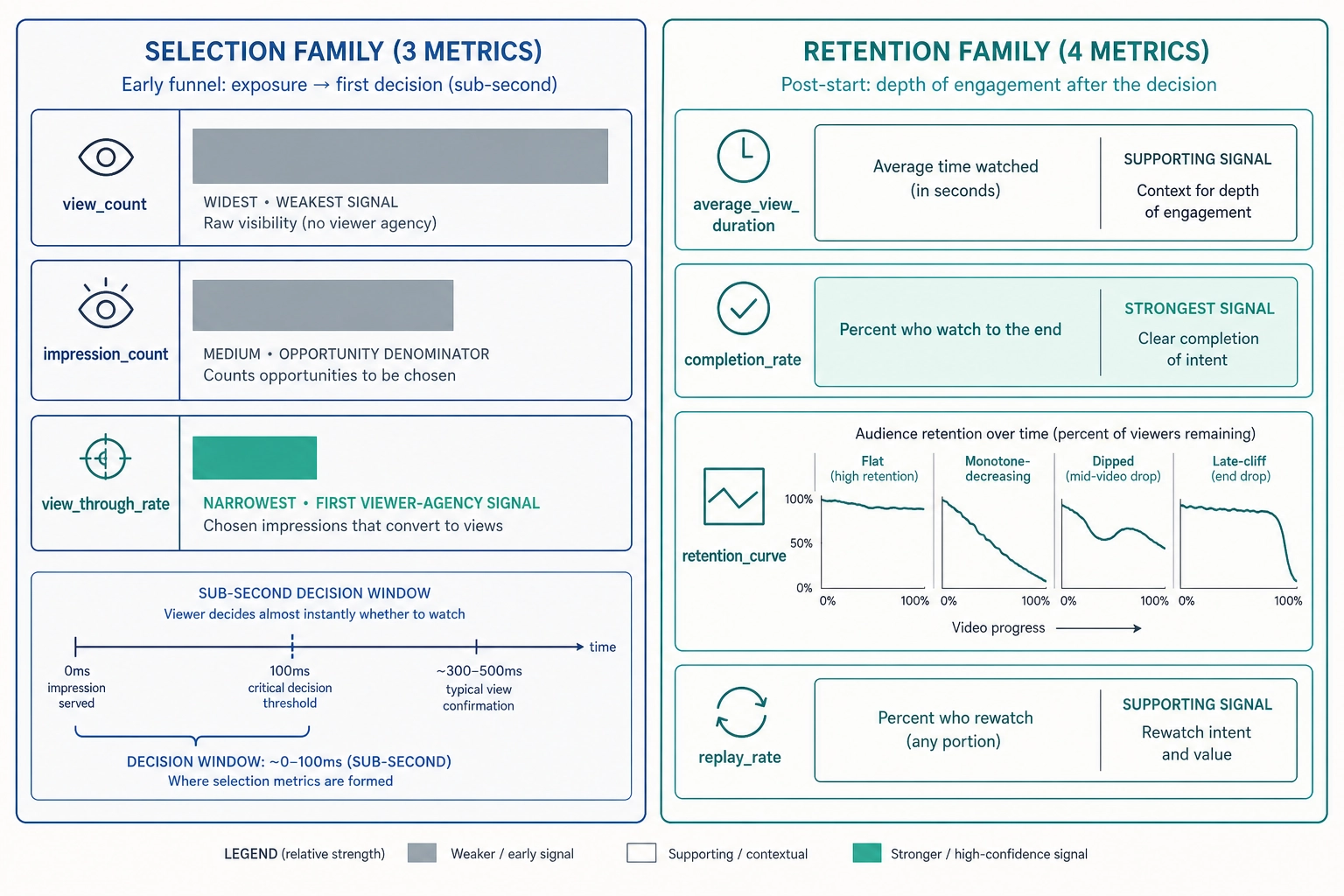
- vp_view_count - total view events over the collection window. Per the spec, this is the platform’s own count of how often its viewer-side commitment threshold was crossed. It is the weakest behavioral signal on the list because it mostly reflects algorithmic distribution rather than viewer agency: if the platform pushed the content into more feeds, view_count goes up regardless of what the content was. It is also platform-specific (Tier 3) because TikTok, Reels, and Shorts each define a “view” differently, and those definitions change over time, so the spec records the platform-specific definition at the time of each data collection rather than hardcoding a single definition.
- vp_impression_count - total times the content appeared on a viewer’s screen, regardless of whether it counted as a view. The opportunity-to-select denominator for selection-rate metrics. Where the platform does not expose this organically (TikTok historically), the field is recorded as null and never imputed.
- vp_view_through_rate - view_count divided by impression_count. The first decision point in the funnel where viewer agency starts to dominate over algorithmic distribution: an impression was offered, and the viewer either committed to starting or kept scrolling. Selection happens in well under a second - face detection drives saccades in as little as 100 ms (the vision researcher Sébastien Crouzet and colleagues, 2010 [3]), and viewport-logging studies confirm sub-second attention allocation to social media ads (the marketing researcher Lana De Vries and colleagues, 2025 [4]); the spec is explicit that the why of that decision belongs to the correlation engine, not to Vₚ.
1.2.2. Retention family - four metrics
Did the viewer keep watching?
- vp_average_view_duration - mean wall-clock seconds viewers spent on the content. The aggregate retention signal: longer durations mean drop-off thresholds were not crossed for longer.
- vp_completion_rate - fraction of views that reached the end of the content. The strongest single retention signal where it is exposed; Instagram Reels does not natively expose it as of April 2026 per the spec, so the field is null on that platform.
- vp_retention_curve - vector of retention values at sampled timestamps within the content. Where the curve drops off - flat, monotone-decreasing, dipped, late-cliff - is the per-second behavioral signature of where viewers’ attention failed. Resolution is platform-dependent: YouTube Shorts exposes near-second-level audience-watch ratio, TikTok exposes only quartile points (p25, p50, p75, p100), Reels does not expose the curve at all as of April 2026.
- vp_replay_rate - fraction of views in which the viewer rewatched at least once, or the rate of replay events normalized by view count. A viewer who decides to re-cross the selection threshold for the same content within a short window is producing a strong signal of perceived value or compulsion. The spec is careful not to commit to an interpretation: replay can mean “I missed something,” “I wanted to share it,” “I found it pleasurable,” or “I found it incomprehensible” - Vₚ records the act, not the motivation.
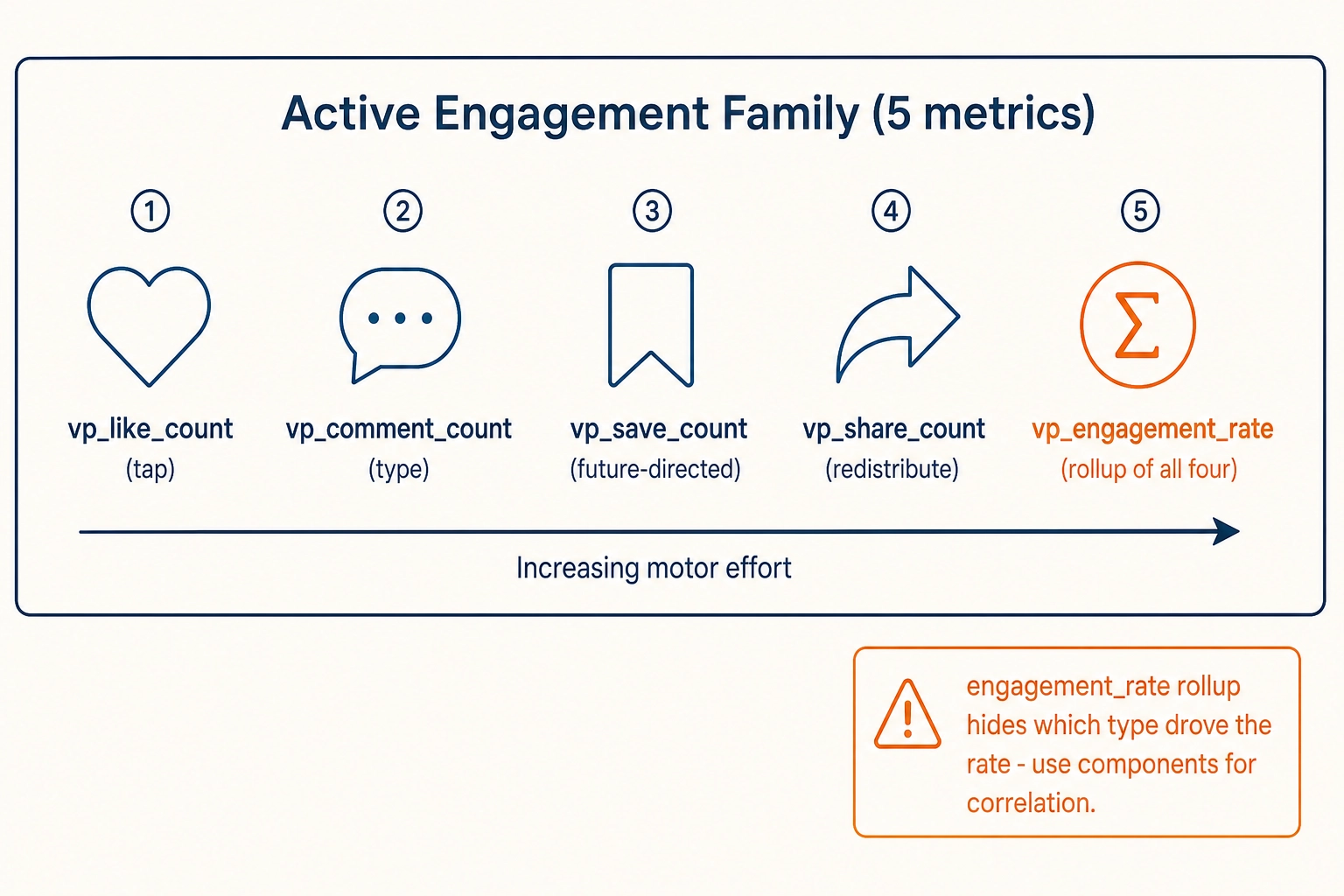
1.2.3. Active engagement family - five metrics
Did the viewer act on the content beyond watching it?
- vp_like_count - count of like / heart / thumbs-up events. An explicit affirmative motor commitment: a finger reached out and tapped a specific button.
- vp_comment_count - count of comments. The viewer chose to do meaningful additional motor work - typing - in response to the content. The text content of comments is the input to the self-report extraction pipeline (section 2), not to Vₚ; Vₚ records the count only.
- vp_save_count - count of save / bookmark events. A future-directed engagement signal: “I want to come back to this.” The spec notes this is a stronger value claim than a like.
- vp_share_count - count of share events. The viewer chose to extend the content’s reach by their own action.
- vp_engagement_rate - sum of likes, comments, shares, saves divided by views (or impressions, depending on platform convention). Commonly used as a single-scalar Vₚ summary. The spec is explicit that this rollup hides which engagement type drove the rate and that correlation analysis should use the components, not the rollup.
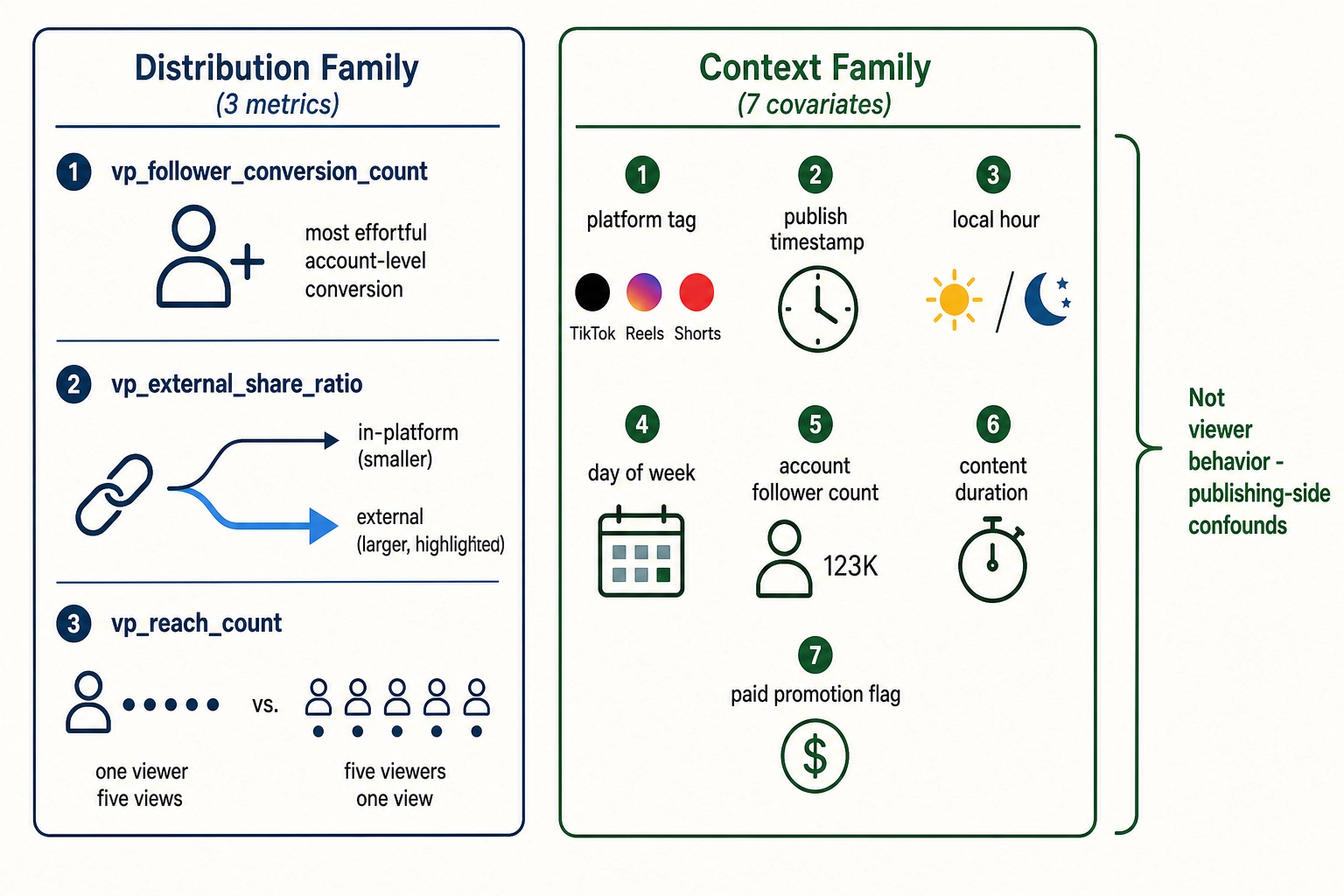
1.2.4. Distribution family - three metrics
Did the viewer pass it on?
- vp_follower_conversion_count - viewers who followed / subscribed to the publishing account as a result of viewing the content. The most effortful account-level conversion in the Vp set: the viewer committed to receiving more from this source.
- vp_external_share_ratio - fraction of share_count that went to surfaces outside the platform (DM to a friend, copy-link, share-to-another-app), as opposed to in-platform reposts. A high external ratio implies the viewer judged the content valuable enough to deliver to a specific named recipient - a higher-effort, higher-trust act than an in-platform repost.
- vp_reach_count - count of unique accounts the content reached. Distinguishes one viewer with five views from five viewers with one view each.
1.2.5. Context family - seven metrics
Under what conditions was the content published? These are not direct viewer behaviors but publishing-side conditions correlation analysis needs as covariates: vp_platform, vp_publish_timestamp, vp_publish_local_hour, vp_publish_day_of_week, vp_account_follower_count, vp_content_duration, vp_paid_promotion_flag. They belong in Vₚ rather than in V₀ because they are facts about the publish event, not properties of the content file. They are confounds on every other Vₚ entry: 10,000 views from a 100-follower account is a different signal than 10,000 views from a one-million-follower account, and paid views are a different audience than organic views.
| # | Family | Metric | What it measures | Normalization tier |
|---|---|---|---|---|
| 1 | Selection | vp_view_count | Total view events | Tier 3 (platform-specific) |
| 2 | Selection | vp_impression_count | Times content appeared on screen | Tier 3 |
| 3 | Selection | vp_view_through_rate | Views / impressions | Tier 1 (directly comparable) |
| 4 | Retention | vp_average_view_duration | Mean seconds viewed | Tier 2 (comparable after rate normalization) |
| 5 | Retention | vp_completion_rate | Fraction of views reaching end | Tier 1 |
| 6 | Retention | vp_retention_curve | Per-timestamp retention values | Tier 3 |
| 7 | Retention | vp_replay_rate | Fraction of views with rewatch | Tier 1 |
| 8 | Active engagement | vp_like_count | Like/heart events | Tier 3 |
| 9 | Active engagement | vp_comment_count | Comment events | Tier 3 |
| 10 | Active engagement | vp_save_count | Save/bookmark events | Tier 3 |
| 11 | Active engagement | vp_share_count | Share events | Tier 3 |
| 12 | Active engagement | vp_engagement_rate | (likes + comments + shares + saves) / views | Tier 2 |
| 13 | Distribution | vp_follower_conversion_count | New followers from this content | Tier 3 |
| 14 | Distribution | vp_external_share_ratio | Off-platform shares / total shares | Tier 1 |
| 15 | Distribution | vp_reach_count | Unique accounts reached | Tier 3 |
| 16 | Context | vp_platform | TikTok / Reels / Shorts | Covariate |
| 17 | Context | vp_publish_timestamp | UTC publish time | Covariate |
| 18 | Context | vp_publish_local_hour | Local hour of publish | Covariate |
| 19 | Context | vp_publish_day_of_week | Day of week | Covariate |
| 20 | Context | vp_account_follower_count | Account followers at publish | Covariate |
| 21 | Context | vp_content_duration | Video length in seconds | Covariate |
| 22 | Context | vp_paid_promotion_flag | Paid vs organic | Covariate |
Total dimensionality: twenty-two metrics times three platforms equals up to sixty-six platform-tagged feature columns, with nulls where a platform does not expose a metric.
1.3. What Vₚ does not see
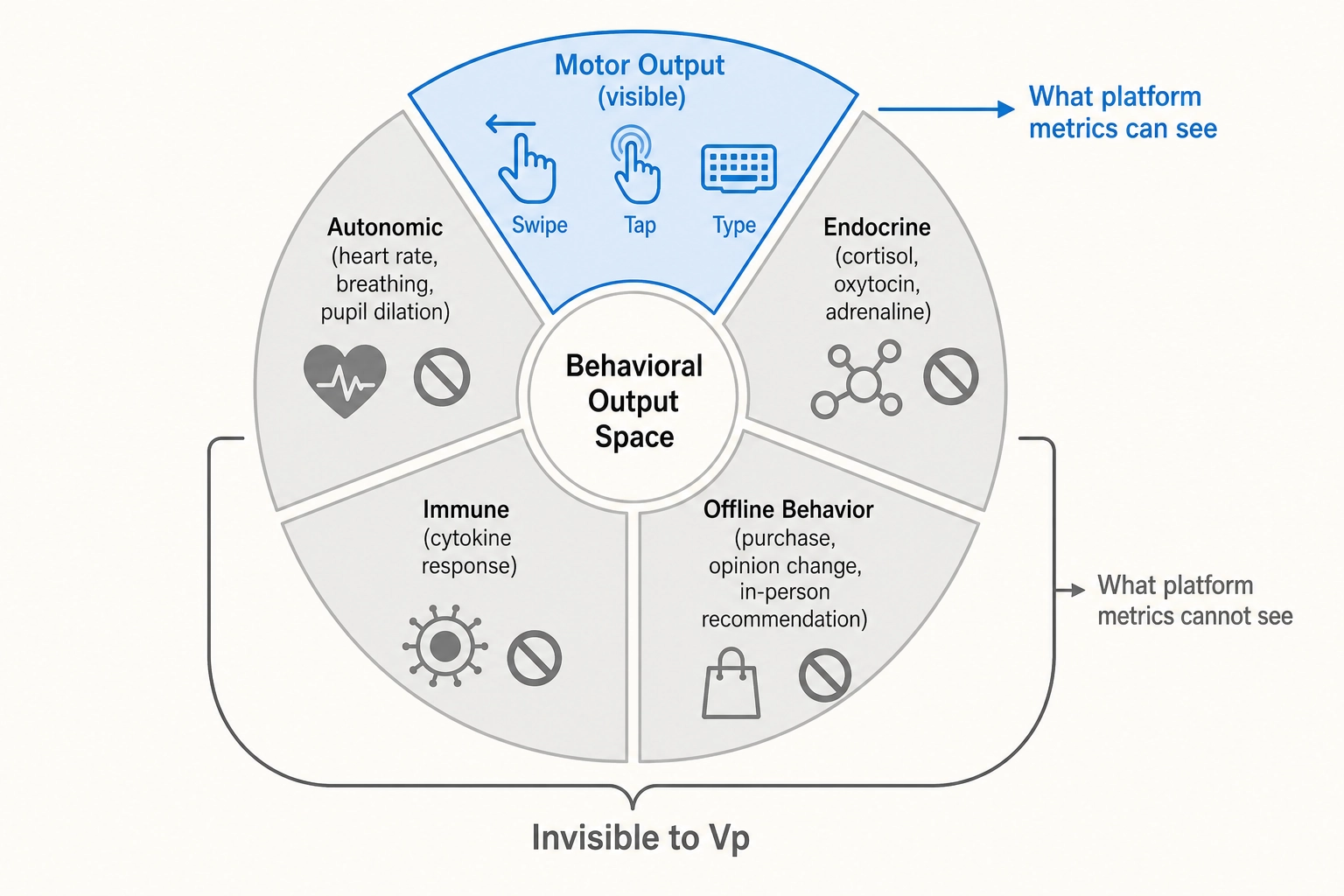
The Phase-5 Vₚ spec section 2 names four categories of behavioral output that exist in Behavioral Output Space but Khozai cannot measure through Vₚ. These are not failings of the spec; they are properties of platform telemetry.
- Autonomic output - heart rate, breathing, pupil dilation, skin conductance, blood pressure. Timescale: seconds. Invisible because no platform telemetry surfaces it.
- Endocrine output - cortisol, adrenaline, oxytocin, testosterone responses to the viewing event. Timescale: minutes to hours. Invisible; measurement requires a blood draw or saliva assay.
- Immune output - cytokine response, immune-cell mobilization. Timescale: hours to days. Invisible.
- Offline behavioral consequences - purchasing the product, trying the recipe, changing an opinion, recommending the video to a friend in person, voting differently. Some leaks back through advertiser-instrumented conversion-tracking pixels, but those are not platform-reported on the content piece itself and are not in Vₚ v1.
The implication for Khozai: Vₚ is a real but partial slice of behavior. When the framework infers that a content property “drives engagement,” the inference is about the visible motor-output slice. It is not a claim that the property changed pulse, hormone level, or whether the viewer made a different real-world decision later. The spec’s section 2 calls this a known constraint that propagates through the framework; Chapter 11 section 1 will treat it as a scope boundary.
One more thing Vₚ does not see: motivation. A like is a count, not a feeling. A replay is an event, not a reason. The spec records that the act occurred and leaves the why to the correlation engine and to the second behavioral channel - self-report - that this chapter turns to next.
2. Self-Report - Three Structured Outputs from Comment Text
2.1. Why self-report has a unique position
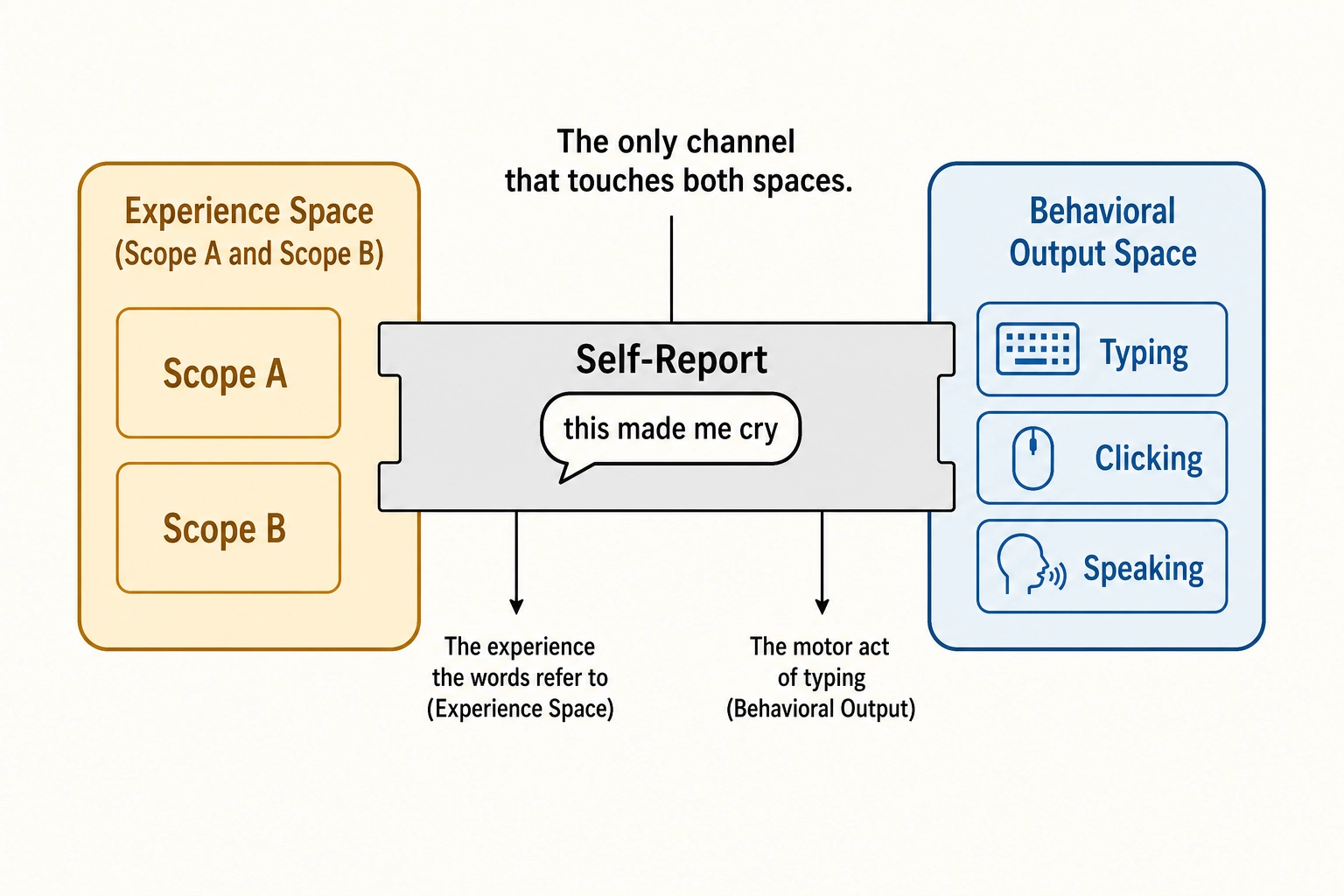
Comments are motor output. A viewer typing “this made me cry” is performing a motor action - finger taps on a keyboard - and the platform records the resulting text. By the spec for Behavioral Output Space (Chapter 2 section 2.4), that motor action lives in Behavioral Output Space alongside finger swipes, button taps, and follows.
But unlike a swipe, a comment has a property no other behavioral output has: its content references Experience Space. The viewer’s typed words describe their subjective experience. The motor act of typing is in Behavioral Output Space; the experience the words refer to is in Experience Space - Chapter 4’s space of perception, emotion, cognition, and motivation. Self-report is the bridge between the two.
This bridge is operationally critical because of how Chapter 2 section 4.4 partitioned Experience Space:
- Scope A - the structurally inferable region. The dimensions of experience, their independence from each other, their hierarchy, their relationship to neural architecture. Chapter 4 names eighteen dimensions across five aspects (Sensory, Affective, Cognitive, Motivational, Bodily). Scope A is reachable through Structural Inference - deriving structure from neural architecture without measuring any specific viewer’s experience.
- Scope B - the structurally opaque region. The qualitative content of experience: what the colour red actually looks like to a viewer, what crying-at-a-video actually feels like to that specific person. Scope B is real (viewers experience it) but it is not reachable through the structural-inference machinery the framework uses for Scope A.
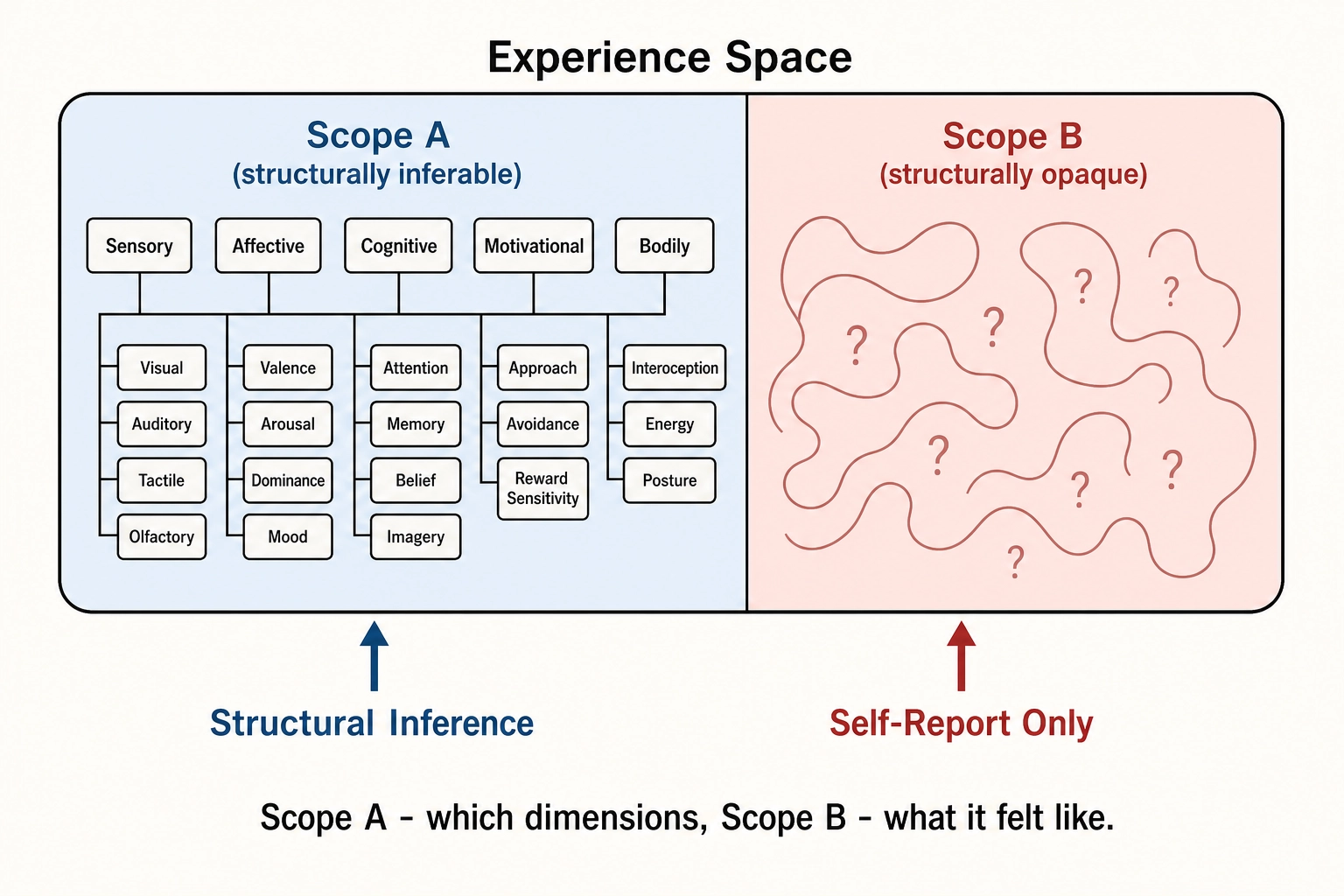
Chapter 2 section 2.4 is explicit on the consequence: self-report is the primary source of Scope B information. When a viewer says “this gave me chills,” they are reporting qualitative content - what their experience was like - that no neural-prediction tool, no content-property extractor, and no platform engagement metric can produce. Self-report also uniquely enables Scope A validation: when a viewer’s own construct label for their state (“I felt nostalgic”) matches the dimensional pattern the framework predicts for that construct (high Self-reference plus Episodic memory plus bittersweet Affective valence plus moderate Arousal - per Chapter 4 section 5), the structural decomposition is corroborated. The viewer is, in effect, naming a state and the framework is checking whether the named state decomposes the way the framework said it would.
Self-report plays a third role that the Scope A/Scope B framing does not fully capture: it specifically compensates for Vₙ’s subcortical blind spot. Chapter 4 identified four experiential dimensions driven primarily by subcortical structures that TRIBE v2 cannot directly predict - Drive (wanting), Hedonic (liking), Arousal, and Fear. These are exactly the dimensions where self-report is most valuable. A viewer comment like “I couldn’t stop watching” is direct evidence of Drive engagement that no cortical prediction can provide. “This terrified me” is direct evidence of Fear engagement that the amygdala’s lower-confidence Vₙ prediction can only approximate through cortical correlates. Self-report does not fix the subcortical blind spot - it is noisy, sparse, and subject to the introspective limitations Chapter 2 noted - but it is the only channel that provides experiential-level information about the dimensions the neural prediction layer is weakest on. This is a design choice, not an empirically validated substitution. Self-report for subcortical states is particularly vulnerable to the introspective-access limitation discussed in Section 3.2: Drive and Arousal are among the dimensions most poorly served by verbal report (the psychologist Lisa Feldman Barrett and colleagues, 2004). The framework treats self-report as supplementary evidence for these dimensions, not as a replacement for direct measurement. The extraction pipeline below is designed with this asymmetry in mind: the Scope A dimension estimates (Output 1) cover all eighteen dimensions, but their incremental value over Vₙ is greatest for the subcortical four.
2.2. The extraction pipeline
The Phase-5 self-report extraction methodology spec (Phase 5, locked) is the engineering artifact that operationalizes this bridge. It commits to an LLM-based extraction pipeline that takes raw comments and produces three structured outputs per comment. The primary LLM is Anthropic Claude Sonnet 4.5 under temperature 0 with a version-locked snapshot, fixed prompts, and fixed schemas (spec section 4). Reproducibility - not correctness - is what the model commitment locks; correctness is left to per-output evaluation against panel-labeled gold sets and to the calibration loop in Chapter 10. The pipeline runs in five stages (ingest, pre-extraction filter, LLM extraction, post-extraction validation, persist), and the same comment under the same lock version produces the same record. LLM-based extraction may also introduce systematic biases in dimensional classification that are distinct from human coder biases; the framework monitors for these through inter-version consistency checks.
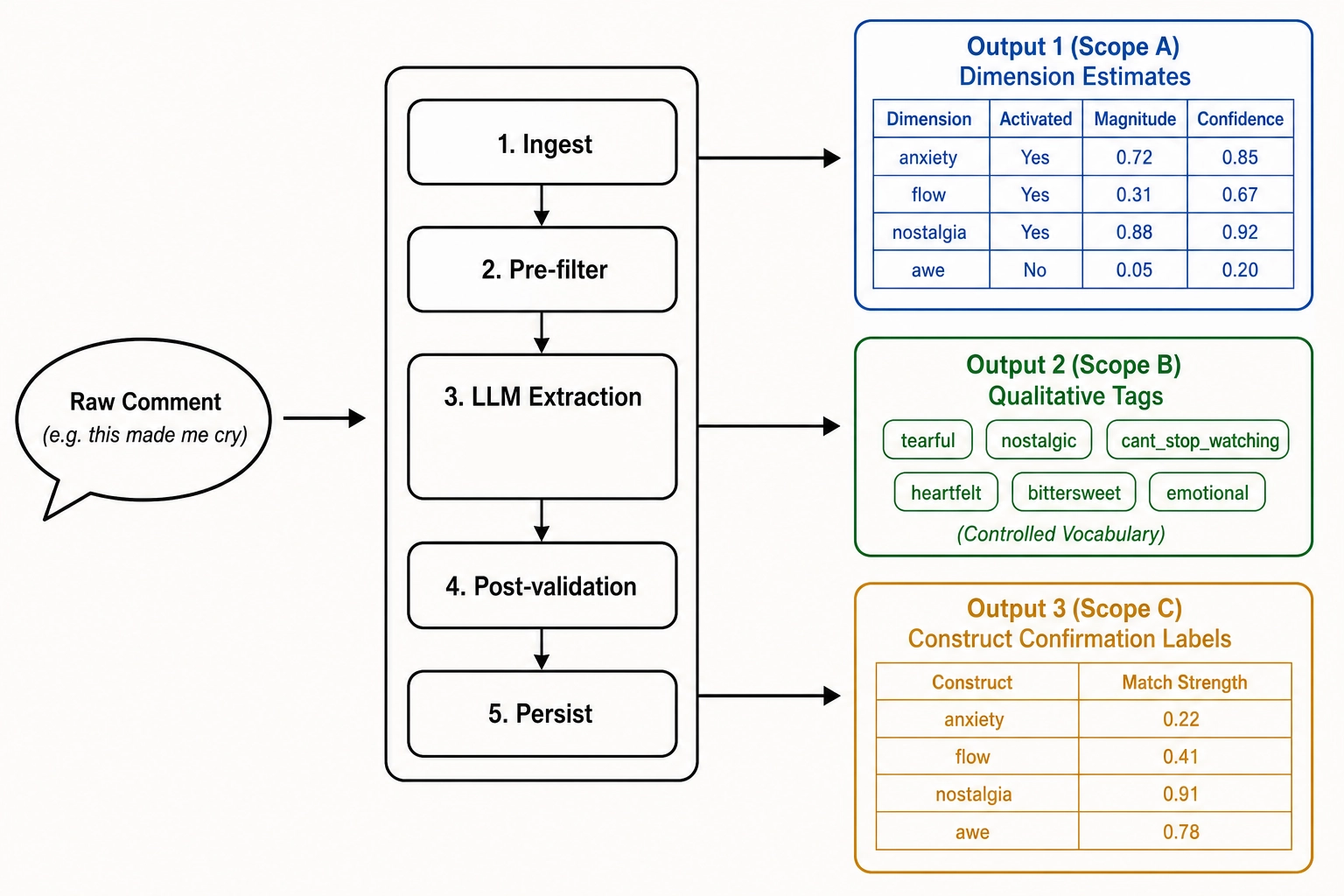
The three outputs the pipeline emits, per spec section 1:
2.3. Output 1 - Scope A dimension estimates
For each comment, the pipeline produces an estimate of which experiential dimensions from Chapter 4 the comment evidences as activated, with magnitude and confidence per dimension. The output answers, per dimension: “Does this comment provide evidence that this dimension was engaged for this viewer? If yes, at roughly what magnitude?”
Per spec section 5.1, this is not a measurement of the dimension itself. Scope A dimensions cannot be measured directly from a comment any more than they can from a like-count. It is a structured inference about what the comment reports. The model is asked at all three of Chapter 4’s resolution levels - the five broad aspects (Resolution Level 1: Sensory, Affective, Cognitive, Motivational, Bodily), the eighteen-dimension expansion (Level 2), and the within-modality and within-aspect splits (Level 3) - and is instructed to populate as deep a level as the evidence supports and to leave finer levels null when the comment underdetermines them.
Per dimension, the record contains: a canonical dimension identifier, the resolution level, a boolean activated flag, an ordinal magnitude in {1, 2, 3, 4, 5} when activated (a five-point intensity-of-evidence scale, where 5 means the comment language strongly evidences this dimension at high engagement), the verbatim evidence_span from the comment that supports the inference, and a confidence value in [0, 1]. The schema enforces parent-child consistency: a non-null Level 3 estimate requires a non-null Level 2 parent.
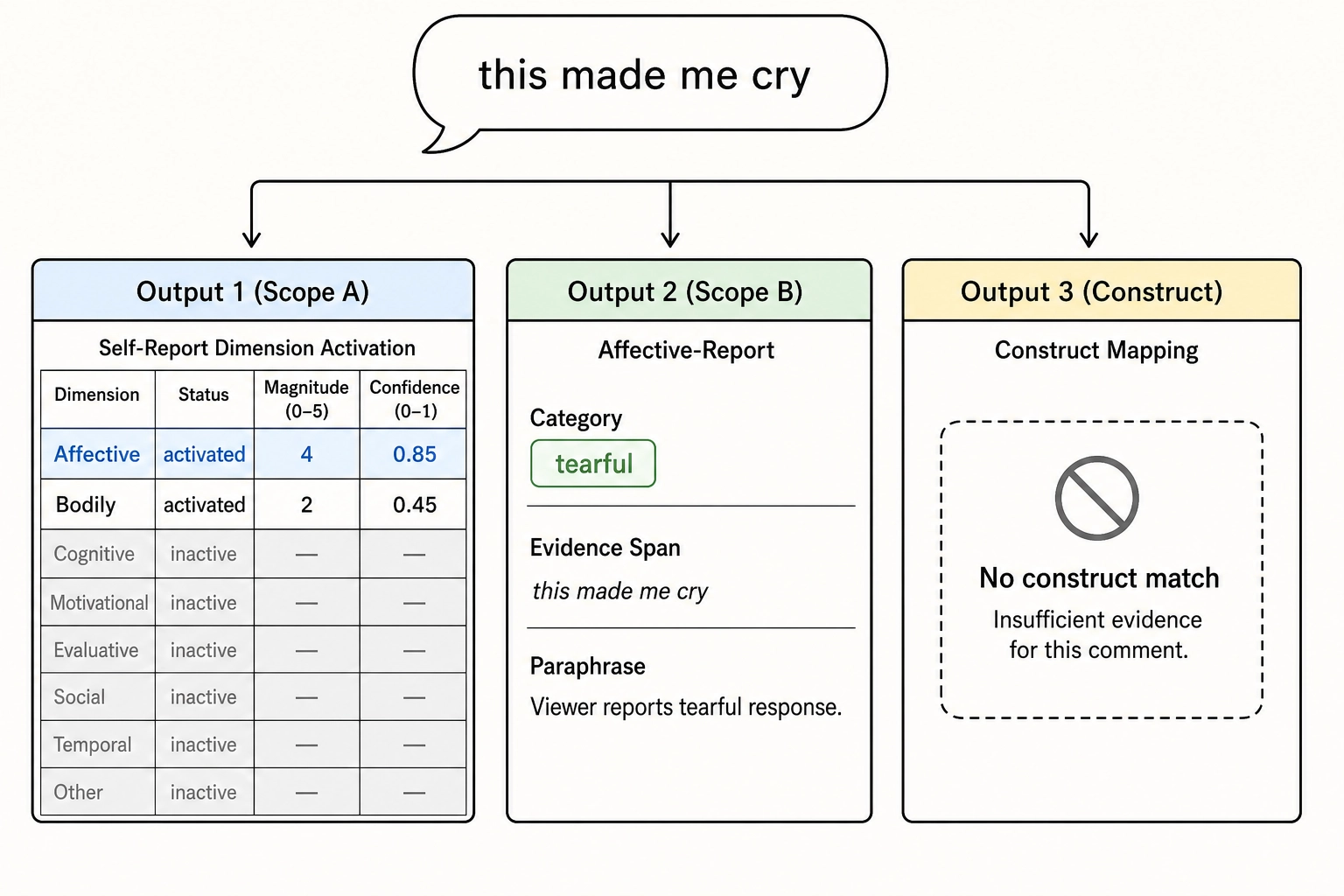
Worked example: “this made me cry.” Under the locked schema (spec section 5.4), this comment produces a Scope A record with Affective (Level 1) activated at magnitude 4 with evidence_span “this made me cry” and confidence around 0.85; Bodily (Level 1) activated at magnitude 2 with evidence_span “cry” and lower confidence - crying is a bodily output, and the comment reports bodily engagement indirectly; Hedonic (Level 2) activated at a magnitude that varies with the affective-valence inference, which the model is instructed to mark at low confidence when the comment is ambiguous; all other dimensions inactive. The plain-language synthesis: the pipeline records that this short comment evidences affective activation strongly, bodily engagement weakly, and is silent on every other dimension. That is the Scope A structured inference for “this made me cry.”
2.4. Output 2 - Scope B qualitative summary
The same comment, on the same call, also produces a controlled-vocabulary summary of what the viewer reported in their own words. This is the Scope B output: it captures qualitative content that the structural decomposition does not. Per spec section 6.1, the structural decomposition tells the framework which dimensions are engaged; the qualitative summary preserves what the viewer said - mapped to a tractable controlled vocabulary so downstream aggregation can count “how many viewers reported a tearful response on this video” without re-reading every comment.
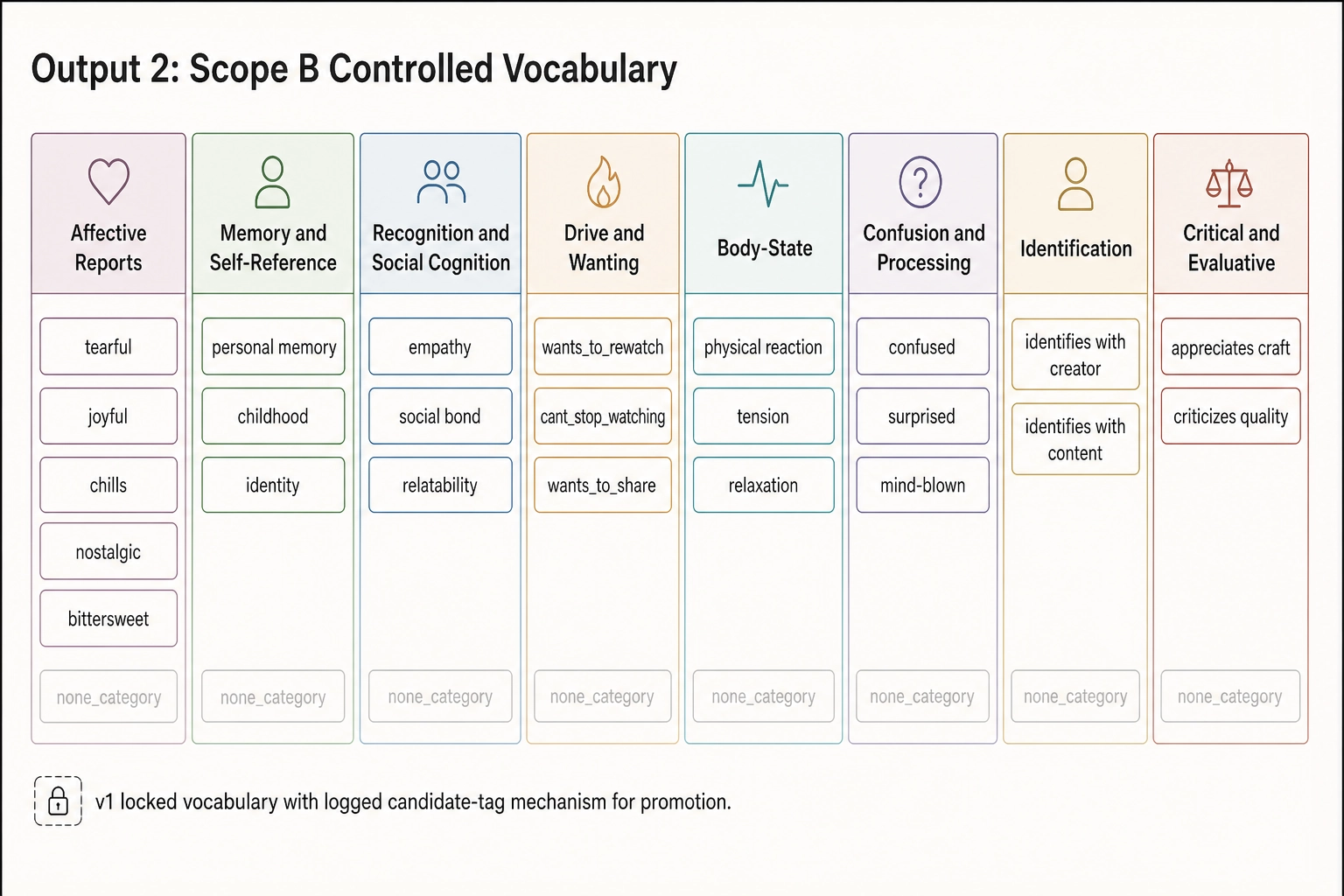
The controlled vocabulary is partitioned into eight categories that mirror the kinds of things viewers actually report (spec section 6.2): affective reports, memory and self-reference reports, recognition and social-cognition reports, drive / wanting reports, body-state reports, confusion / processing reports, identification with content / creator, and critical / evaluative reports. Each category contains zero, one, or more locked tags (e.g., affective-report tags include tearful, joyful, chills_or_goosebumps, nostalgic, bittersweet, and others; drive-report tags include wants_to_rewatch, cant_stop_watching, wants_to_share). Each category also carries an explicit none_* entry so a downstream consumer can distinguish “the comment was silent on this category” from “the model failed to populate this category.”
The Scope B record contains: the list of controlled_vocabulary_tags (each a {category, tag, evidence_span, confidence} record, with out-of-vocabulary tags rejected by the validation stage); a one-sentence paraphrase of up to 200 characters that captures what the viewer reported in the model’s own words (preserved alongside the tags so qualitative texture is not entirely lost); a language_code for downstream filtering; and a report_explicitness ordinal in {1, 2, 3} that affects how Chapter 8 weights the record.
The vocabulary is locked at v1 with a logged candidate-tag mechanism for promotion (spec section 6.4). New tags never enter the vocabulary without an explicit version-tag bump, so cross-version comparisons are explicit and never silent.
Worked example: “I watched this five times.” This comment maps to the drive / wanting category - specifically the cant_stop_watching or wants_to_rewatch tag, depending on the inferred motivation. Output 1 (Scope A) records Drive (Level 2) activated at moderate to high magnitude, evidence_span “watched this five times.” Output 2 (Scope B) records the controlled-vocabulary tag and the paraphrase. The synthesis: a Vₚ replay-rate spike on this video is one piece of evidence about behavior; a comment like “I watched this five times” is a parallel piece of evidence - same underlying motivational state, two different channels, one quantitative and one self-reported, both flagged through the framework.
2.5. Output 3 - Construct-confirmation labels
For each comment, the pipeline checks whether the comment supports any of the named psychological constructs in the framework’s pattern dictionary, and emits a confirmation label with confidence when it does. This is the Scope A validation channel from Chapter 4 section 5 - when a viewer’s own construct label (or implicit construct match) aligns with the predicted dimensional pattern, the structural decomposition is corroborated.
Per spec section 7.1, a construct-confirmation label is emitted only when (a) the comment’s content is consistent with the construct’s predicted dimensional pattern according to the dictionary AND (b) the corresponding Scope A dimensions are also activated in Output 1 of the same call. Construct-confirmation is a derived output: it depends on Output 1 having activated the right dimensions, and the validation stage enforces that consistency.
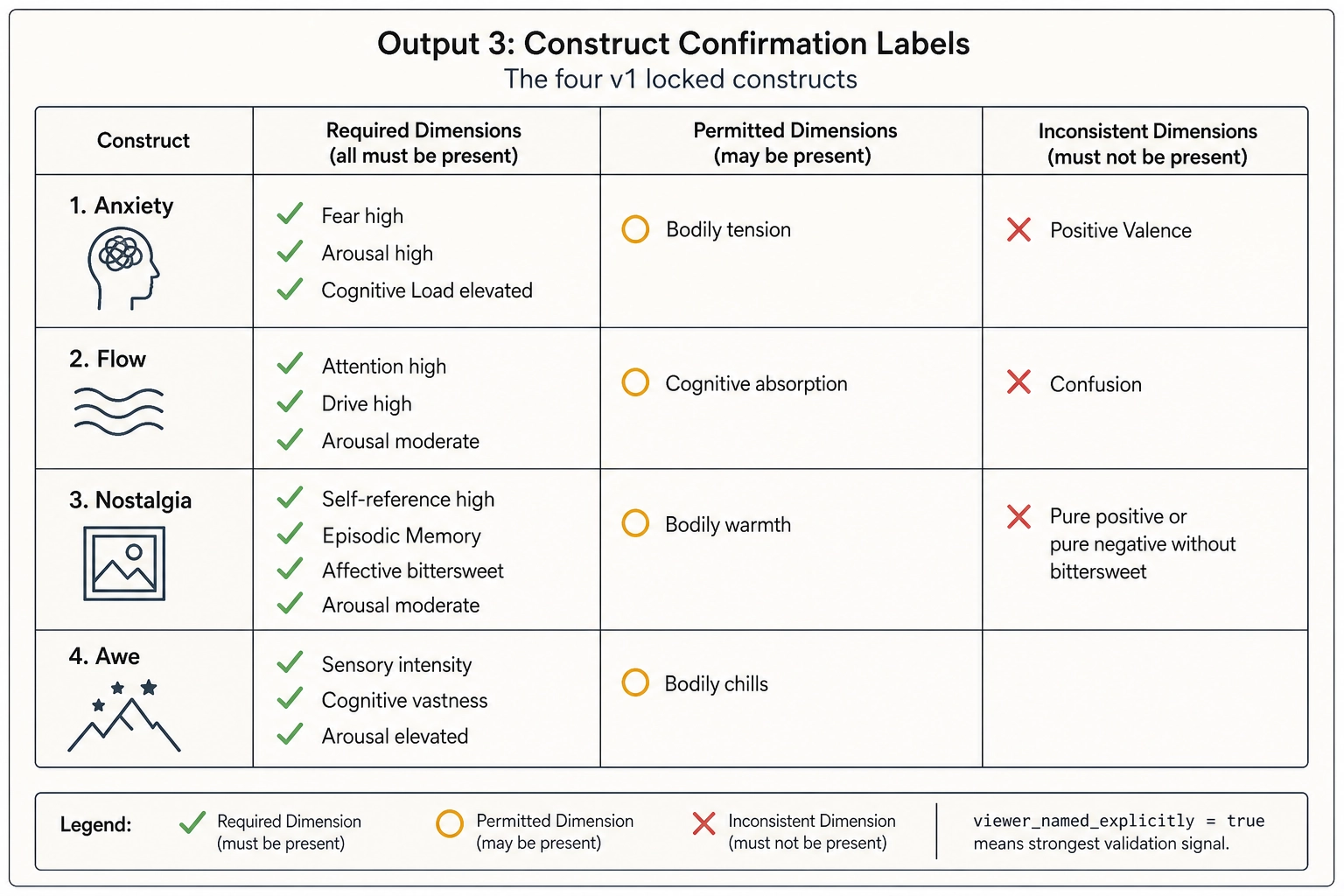
The v1 dictionary locks four constructs, lifted directly from Chapter 4 section 5: anxiety, flow, nostalgia, awe (spec section 7.2). Each construct is expressed as a required pattern across dimensions (the dimensions that must be activated for the construct to match), a permitted pattern (dimensions that may also be activated), and an inconsistent set (dimensions whose activation contradicts the match). For example, the nostalgia entry requires Self-reference (Level 2) high, Episodic memory (Level 3 within Cognition) activated, Affective (Level 1) bittersweet, and Arousal (Level 2) moderate; affective valence purely positive or purely negative without bittersweet character is inconsistent with the match.
Per match, the record contains: the construct name; a viewer_named_explicitly boolean (true if the viewer used the construct name or a clear synonym, false if the construct match is implicit); a match_strength ordinal in {1, …, 5}; the evidence_span; a confidence value in [0, 1]; and an inconsistencies list flagging any required dimensions absent from the matched Output 1 or any inconsistent dimensions activated. Non-empty inconsistencies are flagged, not rejected; downstream Chapter 8 decides how to weight them.
Worked example: “this reminded me of my dad.” Per spec section 7.4, this comment matches the nostalgia construct implicitly. The pipeline records: viewer_named_explicitly = false (the viewer did not say “nostalgic”); the dimensional activations in Output 1 are Self-reference (Level 2) plus Episodic memory (Level 3) plus Affective (Level 1) with bittersweet valence inferred from the parental reference at moderate confidence; match_strength 4; inconsistencies empty (Arousal moderate is permitted, not required-failed). The synthesis: a comment that does not name a construct can still corroborate the framework’s structural decomposition of the construct, because the predicted dimensional pattern is what gets matched, not the construct word. A second comment on the same video that says “this made me feel so nostalgic” would match the same construct with viewer_named_explicitly = true - the strongest validation signal Chapter 4 section 5 supports, because when the viewer explicitly names a state, the framework’s prediction about which dimensions should be active under that state is directly testable.
2.5. The two-region split, operationalized
Putting the three outputs back together: Output 1 is the Scope A side - which Chapter 4 dimensions the comment evidences as activated, at which resolution level, with magnitude and confidence. Output 2 is the Scope B side - what the viewer reported in their own words, mapped to the locked controlled vocabulary so the qualitative texture stays usable. Output 3 is the Scope A validation channel - when a viewer’s named or implicitly-matched construct fits a predicted dimensional pattern, the pattern is corroborated; when it doesn’t, the inconsistency is flagged. The three together are the operational answer to Chapter 2 section 2.4’s claim that self-report is both the primary source for Scope B and a validation channel for Scope A.
3. Limitations of Vₚ and Self-Report
Both channels are real but partial. The framework’s discipline is to state both sides every time - what the channel can do and what it cannot. This section enumerates the cannot-do side; the can-do side is what section 1 and section 2 just walked through.
3.1. What Vₚ cannot do
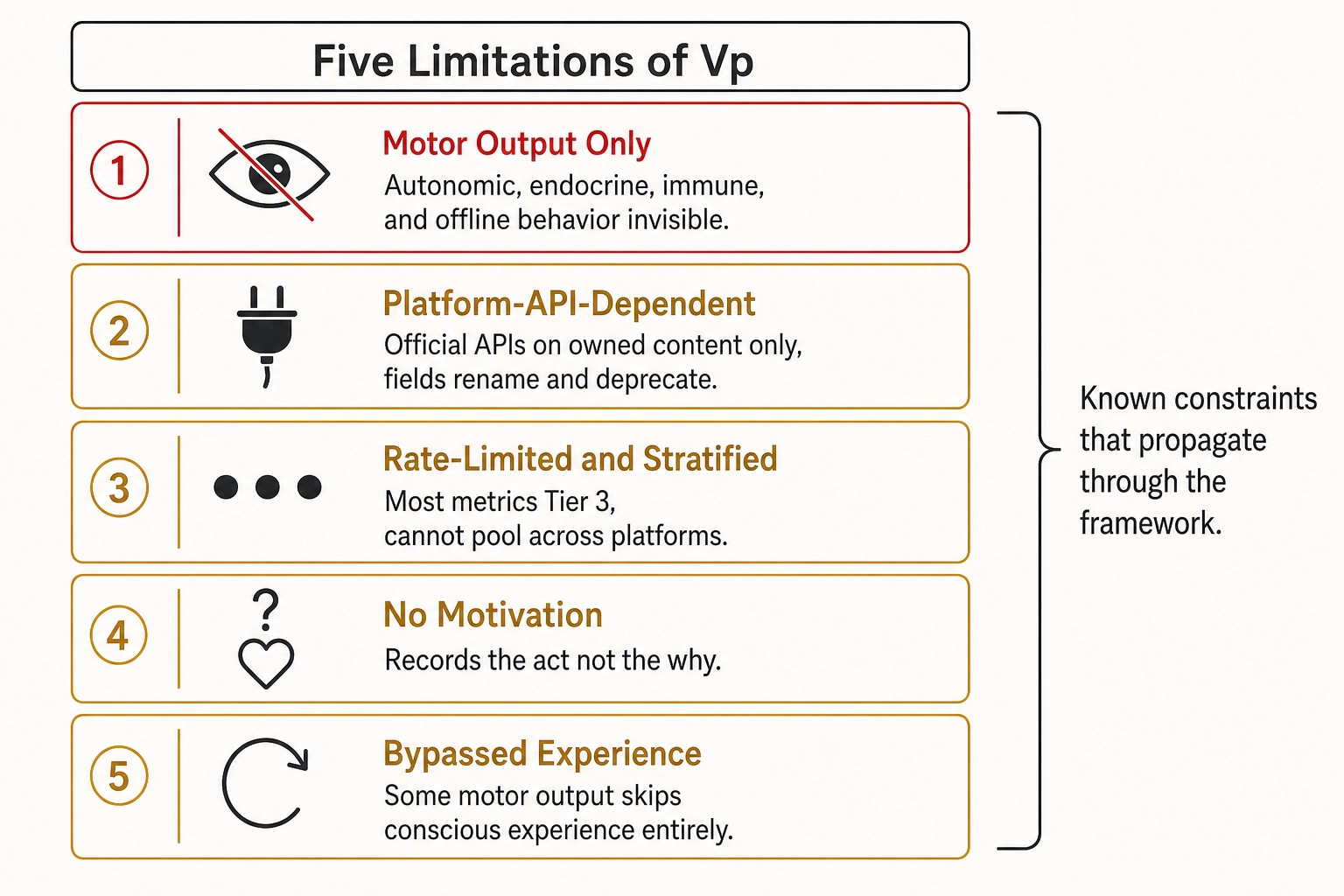
Vₚ is the motor-output subspace only. Per the Phase-5 Vₚ spec section 2, the four invisibility categories repeat here as a chapter-level restatement: autonomic responses (heart rate, breathing, pupil dilation, skin conductance) are silent to platform telemetry; endocrine responses (cortisol, oxytocin, adrenaline, testosterone) are silent for the same reason and require lab measurement Khozai does not have; immune responses are silent; offline behavioral consequences (purchase, recipe-attempt, opinion change, in-person recommendation) are mostly silent, with partial leakage through advertiser-instrumented conversion pixels that are out of scope for Vₚ v1.
Vₚ is platform-API-dependent. The locked metric list assumes Khozai pulls metrics through official platform APIs on owned content. Competitive or public-feed scraping of others’ Vₚ is out of scope for v1. Exact API field names are verified at implementation time against live platform documentation, because platforms rename and deprecate fields without notice.
Vₚ is rate-limited and platform-stratified. Per spec section 3, most volumetric metrics are Tier 3 (platform-specific) and cannot be pooled across TikTok, Reels, and Shorts. The platform tag is a covariate or stratification key on every Vₚ feature. The four-checkpoint timing convention (1h, 24h, 7d, 28d) means Vₚ is sampled, not continuously streamed.
Vₚ records the act, not the motivation. A like is an event. A replay is an event. The spec records that the event occurred and is silent on why. The why belongs to the correlation engine paired with self-report.
Vₚ may reflect bypassed-experience motor output. Chapter 2 section 3.4 names a property of Mapping 4 (Neural State to Behavioral Output): some motor output bypasses Experience Space entirely - reflexive swipes, autoplay-driven re-watches, behavior produced by implicit processing that never entered conscious experience. Vₚ records that the swipe occurred; whether it was deliberate or reflexive is a Scope A / Scope B question for the self-report channel.
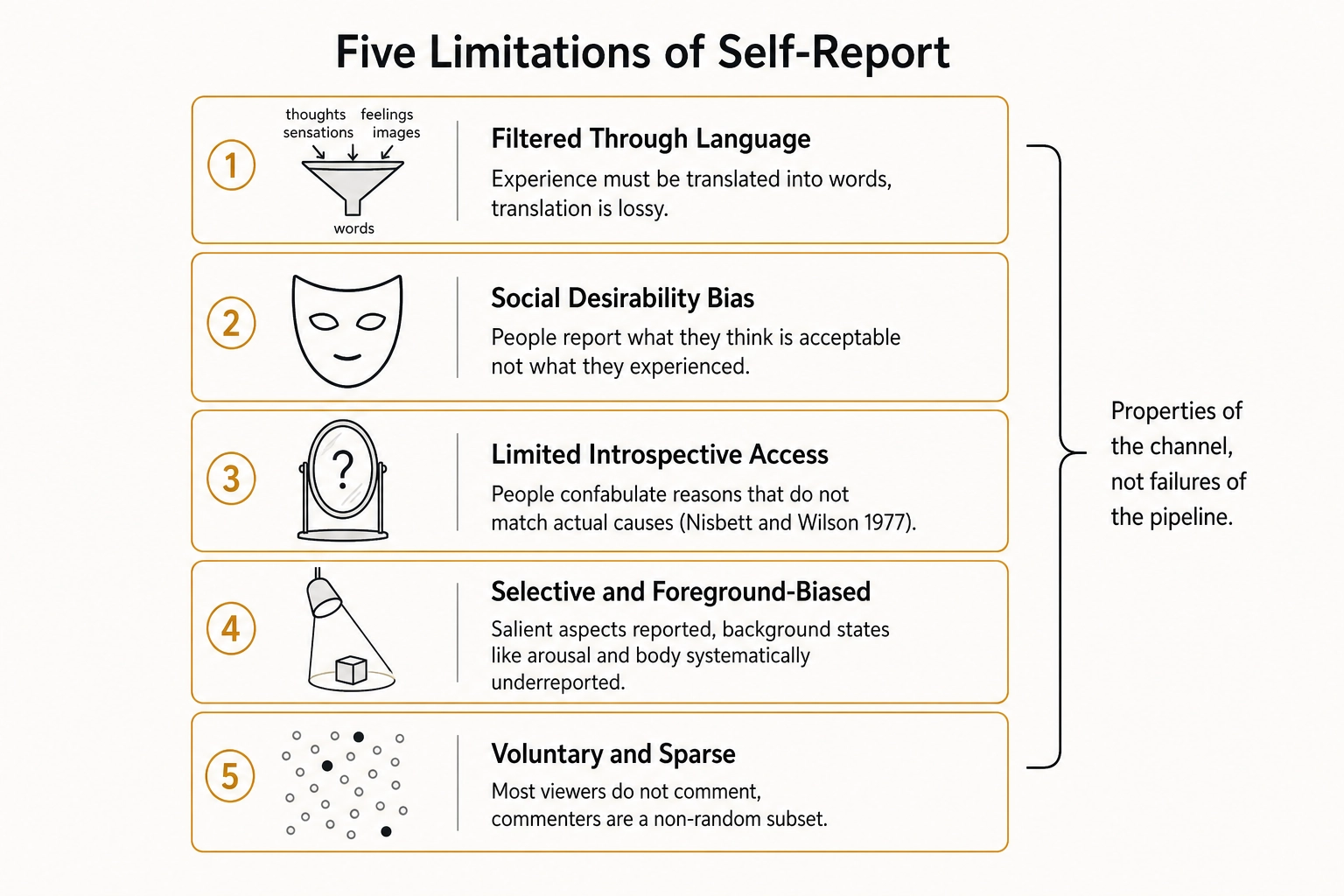
3.2. What self-report cannot do
The Phase-5 self-report spec section 9 inherits in full the Chapter 2 section 2.4 limitations of self-report. Filtered through language. Experience must be translated into words. Many experiences resist verbal description - particularly the fine-grained qualitative content of Scope B - and the translation is lossy. The pipeline’s outputs are bounded by what the viewer can say, not by what they experienced. An absent dimension in Output 1 means the comment did not evidence the dimension; it does not mean the dimension was not engaged.
Biased by social desirability. People report what they think is acceptable to be heard reporting, not always what they actually experienced. Comment content is also shaped by what plays well to the comment-section audience - comments are public. The pipeline does not correct for this distortion; downstream Chapter 8 has to.
Limited by introspective access. People are often wrong about their own states. The psychologists Richard Nisbett and Timothy Wilson (1977, “Telling more than we can know: Verbal reports on mental processes,” Psychological Review 84(3): 231-259) demonstrated that people frequently confabulate reasons for their behavior that do not match the actual causes. Scope A dimension-activation reports inherit this confabulation risk - a viewer who says “I cried because the music was sad” may have cried for reasons their introspective report cannot reach. Construct-confirmation inherits a related risk: viewers may name a state they did not actually have, simply because the named state is a culturally available label. This is precisely why the spec’s Output 3 separates viewer_named_explicitly = true from implicit pattern matches and treats explicit-construct precision against the predicted dimensional pattern as the strongest validation signal. Subsequent work has refined this position, distinguishing between types of introspective report: people are more accurate about preferences and feelings than about the cognitive processes that generated them (Schwarz, 1999).
Selective and foreground-biased. Viewers report salient aspects of experience, not all aspects. Background states (body, arousal, low-level perceptual processing) are systematically underreported relative to foreground states (affective, social-cognitive). The interoception literature quantifies this asymmetry: Barrett et al. (2004 [5]) showed that only high-interoceptive individuals emphasize arousal and body states in emotion reports, and the neuroscientists Hugo Critchley and Sarah Garfinkel (2017 [6]) confirmed that most people underweight bodily signals when describing their emotional experience.
Voluntary and sparse, with a non-random sampling population. Most viewers do not comment. Those who do are a non-random subset. Per-video aggregates derived from comments are aggregates over the commenting population, not the viewing population. The Phase-9 correlation methodology has to treat this as a sampling artifact, not as a property of viewer experience at large.
These are not failures of the pipeline. They are properties of the channel that Chapter 2 section 2.4 names explicitly. The pipeline’s job is to extract structure from a noisy, biased, sparse channel - not to fix the channel. The framework’s overall validity depends on combining self-report with Vₚ and with the content-side vectors, none of which alone is enough.
4. How Vₚ and Self-Report Connect to the Framework
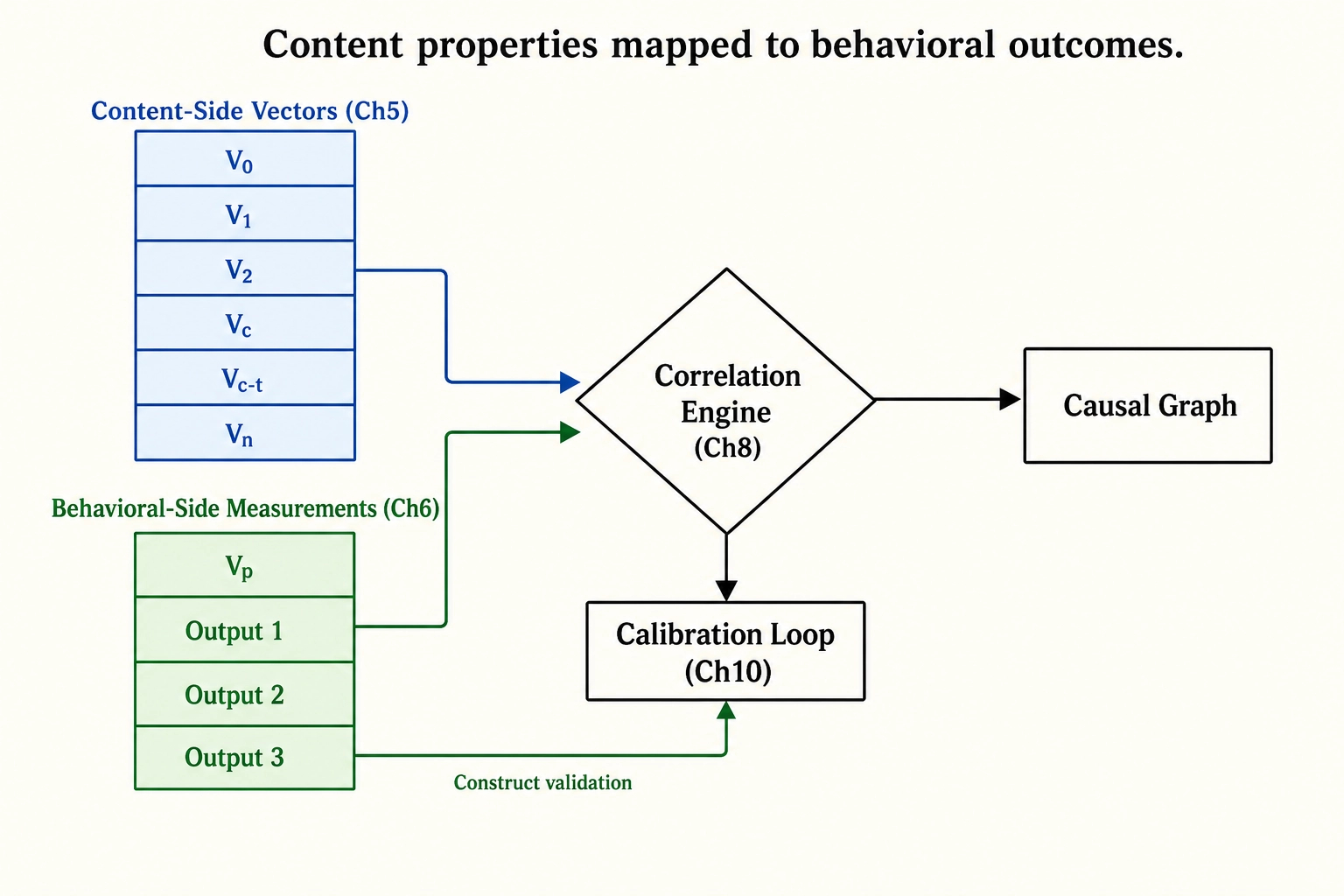
Behavioral outcomes are the dependent-variable side of Khozai’s correlation engine. Chapter 5 specified the content-side vectors - V₀, V₁, V₂, Vc, Vc-temporal, Vₙ - that describe what a piece of content is. This chapter has specified the behavioral-side measurements - Vₚ and the three self-report outputs - that describe what happened after the content was published. The correlation engine, introduced in Chapter 8, is the machinery that maps the first set to the second.
The forward references this chapter is allowed to make:
- Chapter 8 is where the correlation engine is detailed: how content-property values get mapped to Vₚ outcomes, how self-report outputs enter the analysis as confounders or as confirmatory evidence, how construct-confirmation labels weight predicted-pattern interpretation, and how per-content-piece measurements roll up into per-persona effect sizes. The Vₚ spec’s section 6 and the self-report spec’s section 10 both note that featurization into regression-ready vectors, and per-construct correlation thresholds, are Phase-9 decisions - not this chapter’s.
- Chapter 9 is where the inference chain runs end-to-end on a specific video: decompose the content; approximate Vc and Vₙ; predict; publish; observe Vₚ and the self-report outputs; mutate; correlate; interpret. This chapter supplies the “observe” step’s specification.
Two integration points shape how this chapter’s outputs get used downstream.
Vₚ and self-report are siblings under Phase 5, not sequential. They run in parallel on the same published content. Vₚ counts the comments; the self-report pipeline reads them. The two specs are designed to be consumed jointly: Vₚ tells the framework what viewers did, self-report tells the framework what they experienced (Scope B) and corroborates the structural decomposition of what they experienced (Scope A). Neither alone is enough; both together are still partial - autonomic, endocrine, immune, and offline behavior remain invisible.
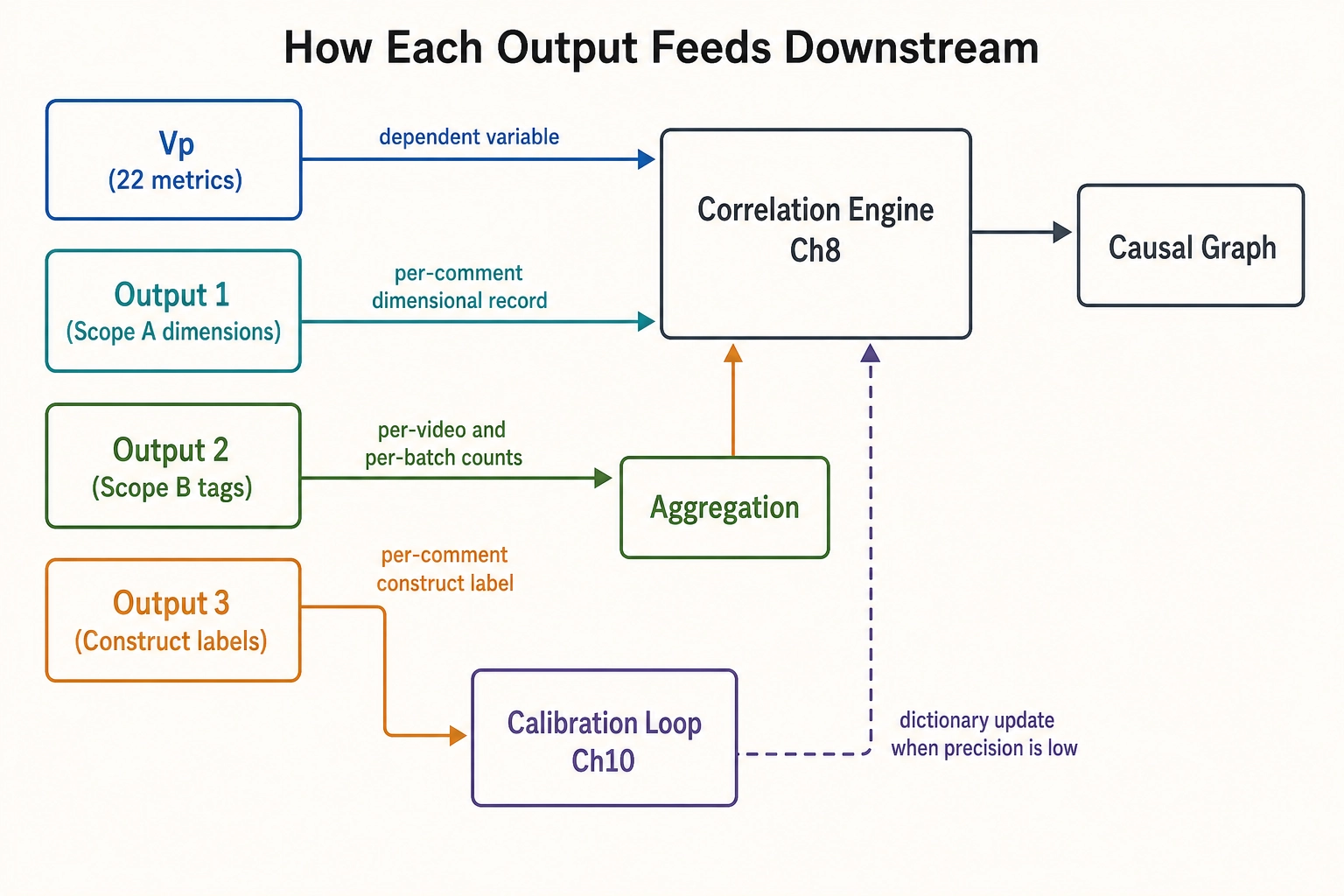
Self-report’s three outputs map onto distinct downstream uses. Output 1 (Scope A dimension estimates) feeds the correlation engine as a per-comment record of which dimensions were evidenced. Output 2 (Scope B controlled-vocabulary tags and paraphrase) feeds aggregation: per-video and per-batch counts of how many viewers reported a tearful response, a memory, a desire to rewatch, a confused reaction. Output 3 (construct-confirmation labels) feeds the framework’s own self-validation: every confirmed match is evidence for or against Chapter 4 section 5’s claim that named psychological constructs decompose without residual into configurations across the dimension set. The first two are inputs to Chapter 8’s correlation engine; the third also feeds Chapter 10’s calibration loop - when explicit-construct precision is persistently low for a given construct, the dictionary entry or the framework’s decomposition claim has a problem, and the calibration loop has to surface it.
The framework’s bets and risks both touch this chapter. Bet 2 - that predicted brain activation from an encoding model carries enough signal to predict performance - is the empirical question Chapter 11 section 2 will lock verbatim from Chapter 1 section 9. Vₚ is what “performance” means operationally on the platforms Khozai is built around. If Vₚ outcomes correlate with predicted-Vₙ patterns at meaningful effect sizes after controlling for confounders, the bet has empirical support; if they do not, the bet fails. This chapter does not adjudicate the bet; it fixes what the bet will be tested against.
The risks side is also touched. The commenting population is non-random; the Scope B controlled vocabulary is opinionated and v1-incomplete; self-reported LLM confidence is known to be poorly calibrated (the AI researcher Saurav Kadavath and colleagues, “Language Models (Mostly) Know What They Know,” 2022, arXiv:2207.05221, cited by the self-report spec section 4.4). On the Vₚ side: platform APIs change, field semantics drift, pooling across platforms is unsafe. The Phase-5 specs treat these as constraints that apply even if the framework’s three central bets succeed - properly RISKS, not BETS.
What Khozai can do with these two channels is observe behavior - partially, with known boundaries. What Khozai cannot do is observe everything Behavioral Output Space contains. Both sides are stated. The chapters that follow are about what the framework does with what it can see.
| Output | Space | What it captures | Downstream use |
|---|---|---|---|
| Vₚ (22 metrics) | Behavioral Output (motor subspace) | What viewers did: views, retention, engagement, distribution | Dependent variable for Ch8 correlation engine |
| Self-report Output 1 | Experience (Scope A, inferred) | Which Ch4 dimensions the comment evidences as activated | Per-comment dimensional record for Ch8 |
| Self-report Output 2 | Experience (Scope B, reported) | Controlled-vocabulary tags of qualitative experience | Per-video/per-batch aggregation counts |
| Self-report Output 3 | Experience (Scope A, validation) | Construct-confirmation labels against Ch4 pattern dictionary | Ch4 structural decomposition validation; Ch10 calibration loop |
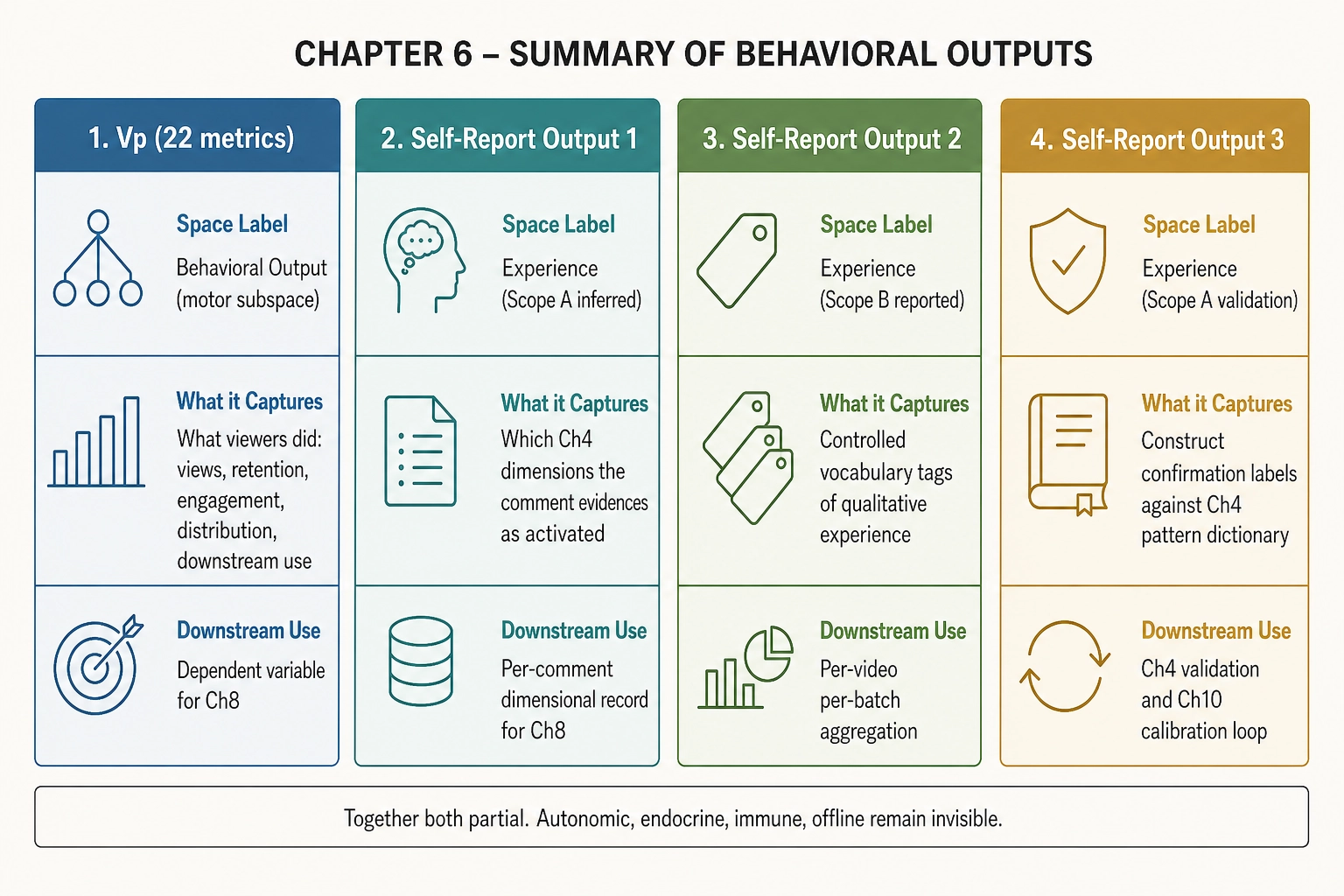
What this does NOT say. This chapter does not claim that Vₚ captures all viewer behavior: it captures the motor-output subspace visible through platform APIs. It does not claim that self-report is accurate: viewers confabulate, filter for social desirability, and systematically underreport background states. It does not claim that the commenting population represents the viewing population: commenters are a self-selected non-random subset. It does not claim that Output 1 (Scope A estimates) measures experiential dimensions directly: it is a structured inference about what comments report, not a measurement of experience. And it does not claim that Scope B is fully characterized: the controlled vocabulary is a v1 set that captures common qualitative reports but leaves most of what experience feels like uncaptured.
Khozai implication. The behavioral-side specification established in this chapter completes the measurement loop the framework requires: content-side vectors (V₀ through Vₙ, Chapter 5) describe what a content file is; behavioral-side measurements (Vₚ and self-report) describe what happened after publication. The correlation engine in Chapter 8 maps the first set to the second. Without Vₚ, the three central bets have no dependent variable to test against. Without self-report, Scope A validation has no corroboration channel, and Scope B has no data source at all. The two channels are complementary and both partial: Vₚ counts acts without knowing reasons; self-report provides reasons from a biased, sparse subset. The framework’s analytical validity depends on combining them.
Conclusion
This chapter specified the two behavioral-side measurement channels Khozai uses to observe what viewers do with published content. Vₚ locks 22 platform metrics across 5 behavioral families (selection, retention, active engagement, distribution, context), sampled at four post-publish checkpoints on three platforms. The self-report extraction pipeline produces three structured outputs per comment: Scope A dimension estimates (Output 1), Scope B qualitative tags (Output 2), and construct-confirmation labels (Output 3). Together they provide the dependent-variable side that the content-side vectors from Chapter 5 require.
Two facts established here carry forward. First, Vₚ is motor output only: autonomic, endocrine, immune, and offline behavioral consequences are invisible to platform telemetry. Second, self-report is the only channel in the framework that touches Scope B of Experience Space, but it does so through a noisy, biased, sparse bridge that the framework acknowledges and works around rather than trusts.
The next chapter introduces the mutation engine: the controlled single-variable intervention system that transforms the framework from an observational tool into an experimental one. Where this chapter specified what Khozai observes, Chapter 7 specifies what Khozai changes, and V∆ captures the difference.
Bibliography
[1] R. Nisbett, T. Wilson. Telling More Than We Can Know: Verbal Reports on Mental Processes. Psychological Review, 84(3): 231-259, 1977. [JOURNAL ARTICLE] Used in: Section 3.2 (self-report limitations), introspective access and confabulation risk.
[2] S. Kadavath et al. Language Models (Mostly) Know What They Know. arXiv preprint, arXiv:2207.05221, 2022. [PREPRINT] Used in: Section 4 (framework connection), LLM self-reported confidence calibration limitations for the self-report extraction pipeline.
[3] S.M. Crouzet, H. Kirchner, S.J. Thorpe. Fast Saccades Toward Faces: Face Detection in Just 100 ms. Journal of Vision, 10(4), 16, 2010. [JOURNAL] Used in: Section 1.2.1 (Selection family), evidence for sub-second content evaluation supporting the view-through-rate decision speed.
[4] E. De Vries, L. Hudders, S. Rathje. Measuring Gaining and Holding Attention to Social Media Ads with Viewport Logging. Journal of Advertising, 2025. [JOURNAL] Used in: Section 1.2.1 (Selection family), viewport-logging evidence for sub-second attention allocation in social media feeds.
[5] L.F. Barrett, K.S. Quigley, E. Bliss-Moreau, K.R. Aronson. Interoceptive Sensitivity and Self-Reports of Emotional Experience. Journal of Personality and Social Psychology, 87(5), 684-697, 2004. [JOURNAL] Used in: Section 3.2 (self-report limitations), evidence that only high-interoceptive individuals emphasize arousal and body states in emotion reports.
[6] H.D. Critchley, S.N. Garfinkel. Interoception and Emotion. Current Opinion in Psychology, 17, 7-14, 2017. [REVIEW] Used in: Section 3.2 (self-report limitations), evidence that most people underweight bodily signals when describing emotional experience.