Introduction
Chapter 5 specified what Khozai measures from a content file: twenty-five physical channels in V0, sixteen first-order temporal patterns in V1, twelve second-order trends in V2, thirty-two cognitive dimensions across nine categories in Vc, twenty-four temporal-cognitive channels in Vc-temporal, and a predicted cortical activation pattern across 360 Glasser areas in Vn. That is 109 content-side channels in all (53 physics-layer channels from V0 + V1 + V2, plus 56 cognitive-layer channels from Vc + Vc-temporal). Chapter 6 specified what Khozai observes after the content is published: twenty-two platform metrics in Vp and three structured outputs from the self-report extraction pipeline. Together, the two chapters provide the paired data the framework needs: content properties on one side, behavioral outcomes on the other.
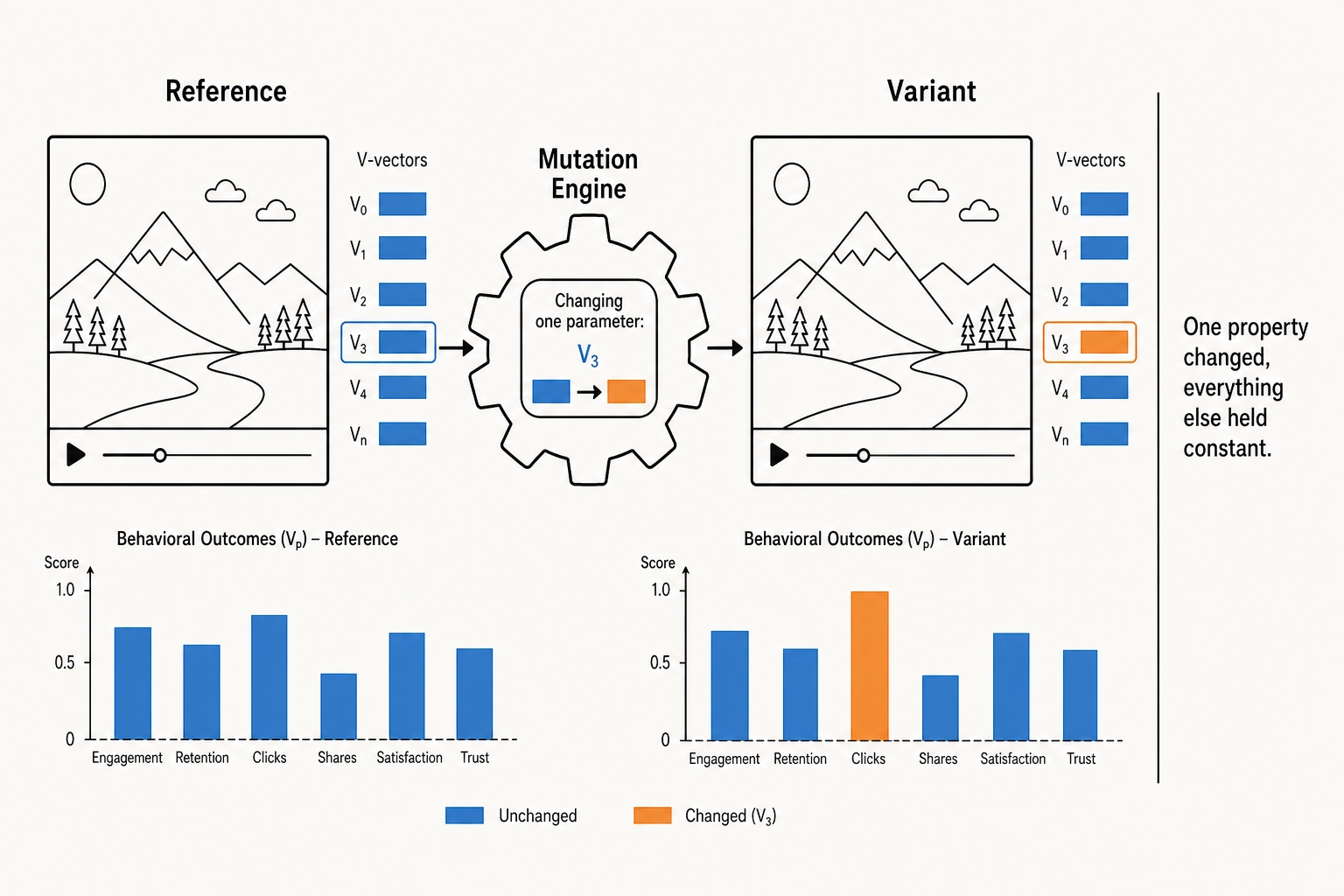
But paired data from existing content cannot answer the question the framework exists to answer. A video with a face, warm colors, fast pacing, and background music got 40% higher retention than a video that differed on all four. Which of those differences mattered? Post-hoc correlation on existing content cannot isolate the answer because the videos differ on dozens of properties simultaneously. The only way to know which property drove the result is to change one property at a time and measure what happens. That is what the mutation engine does.
How the chapter is organized. This chapter walks through the engine in seven sections. Section 1 states the principle. Section 2 defines V-delta, the difference vector that makes “what changed” precise. Section 3 introduces the types of mutations the operator vocabulary supports. Section 4 describes the technical substrate that makes controlled mutation possible: the scene-AST architecture. Section 5 covers the experimental design that turns mutations into statistically trustworthy evidence. Section 6 connects the engine back to the formal framework through Mapping 5’s feedback loops. Section 7 surveys the landscape of controlled content experimentation as it exists outside Khozai.
1. The Principle: Controlled Mutation
The principle behind the mutation engine is the same one that governs every controlled experiment in science: change one thing, hold everything else constant, measure the effect. The default experimental design is single-variable - one property changed per variant - because it maximizes interpretability. If single-variable mutations show no reliable isolated effect, the same logic extends to coordinated multi-variable mutations: change a defined set of properties together while holding everything else constant. The control is over which properties change and which don’t, whether that means one or a defined combination.
In Khozai’s terms: take a piece of content with known V-vectors (V0, V1, V2, Vc, Vc-temporal, Vn), change one property (or a defined combination) at one or more vector layers, verify that all other properties stayed within tolerance, publish both the original and the variant under identical conditions, collect Vp outcomes for both, and attribute the difference in outcomes to the difference in the targeted properties.
“Change one thing” is easy to say and hard to do with video. A video is not a spreadsheet where you can edit one cell and leave the rest untouched. Changing the luminance of a frame changes the pixel values (V0), which changes the temporal pattern of luminance over the file (V1), which may change the luminance slope over the file’s duration (V2), which may change what the vision-language model recognizes (Vc), which changes what the brain encoding model predicts (Vn). A single physical change propagates through the entire V-vector stack. The mutation engine’s job is to make one targeted change, declare the expected propagation at every other layer, verify that the actual propagation stayed within declared bounds, and record the whole V-delta profile so the correlation engine knows exactly what changed and by how much.
This is not a new idea in experimental science. It is a new application domain. The closest academic precedent is stimulus-controlled video databases for neuroimaging [6] and encoding-model work on natural movies [7]. Neither combines programmatic single-variable mutation with multi-layer verification. As of April 2026, no published or commercially available system performs controlled single-variable mutation of physical video properties - cut rate, luminance, motion energy, audio spectral shape, face area - under isolation verification at every V-vector layer. This is based on our survey of published systems and commercially available tools as of April 2026. Internal tools at platform companies may perform similar operations but are not publicly documented. What exists in the landscape is surveyed in Section 7. What Khozai builds on top of the principle is the subject of Sections 2-6.
2. V-delta: The Difference Vector
Chapter 2 Section 4.6 defined V-delta as the difference between two content pieces’ vectors at whichever layer is being compared: for any vector type, V-delta = V_variant minus V_reference. This section unpacks how V-delta works in practice and why the choice of reference matters.
The arithmetic
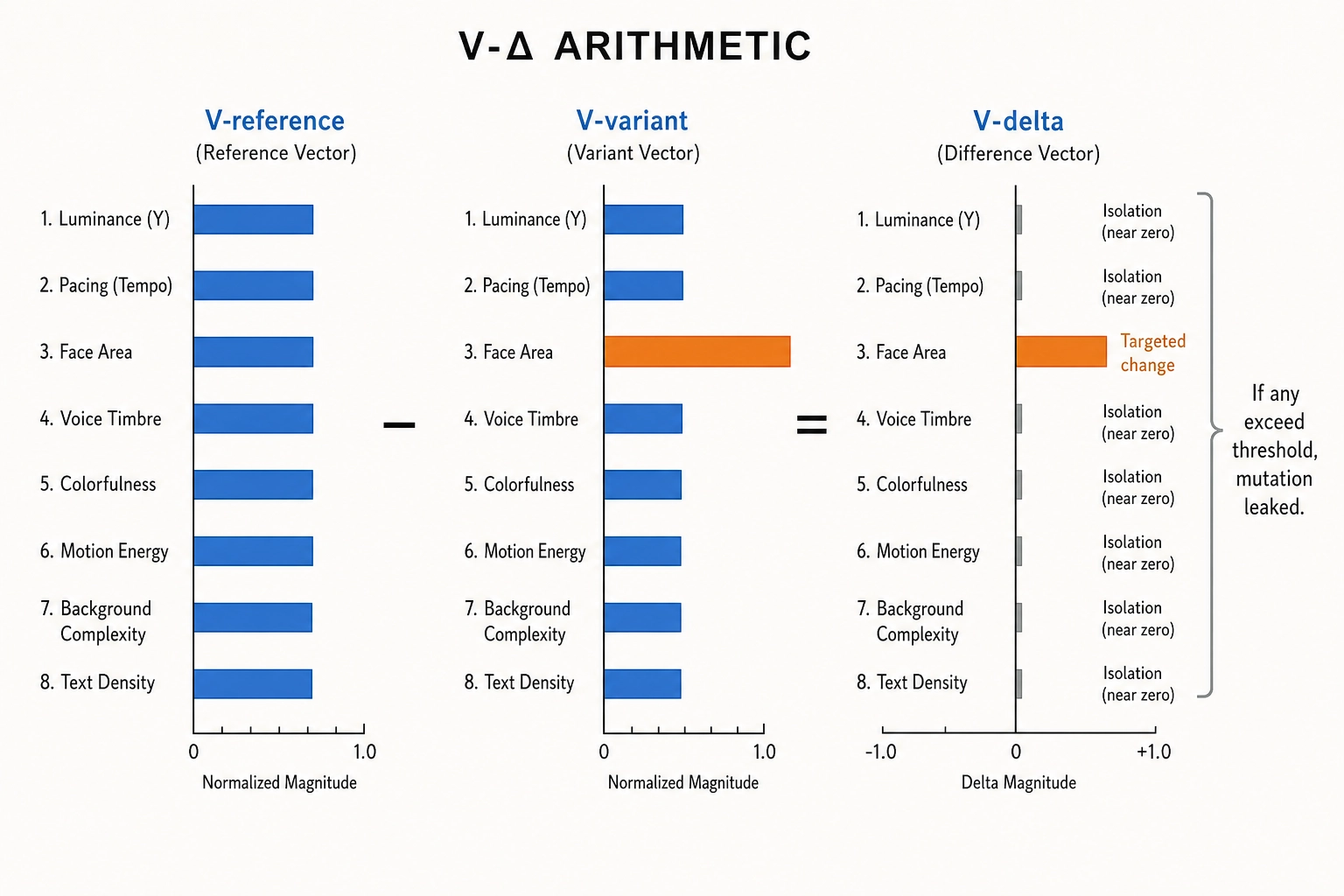
V-delta is computed per channel. If the reference video has a mean linear luminance of 0.35 and the variant has a mean linear luminance of 0.42, then V-delta on that channel is +0.07. If the reference has 1.2 cuts per second (V1 pacing) and the variant has 2.4, V-delta is +1.2 cuts per second. If the reference’s Vc reports vc_face_present = true on 80% of frames and the variant reports vc_face_present = true on 30% of frames, V-delta on that dimension is -0.50 (a 50-percentage-point drop in face-present fraction). The arithmetic is simple - subtraction - but the subtraction is done at every layer, on every channel, so the full V-delta profile tells you not just what the mutation targeted but how far the change propagated.
The mutation engine computes V-delta in both directions: the targeted V-delta (the property the operator changed, which should be large and in the intended direction) and the isolation V-delta (every property the operator promised not to change, which should be small). A successful mutation is one where the targeted V-delta is within the operator’s declared tolerance band and every isolation V-delta is below the operator’s declared footprint threshold. When an isolation channel’s V-delta exceeds its threshold, the mutation leaked: it changed something it was not supposed to. The verification pipeline (Section 4) catches this before the mutation enters the experiment.
Two kinds of reference
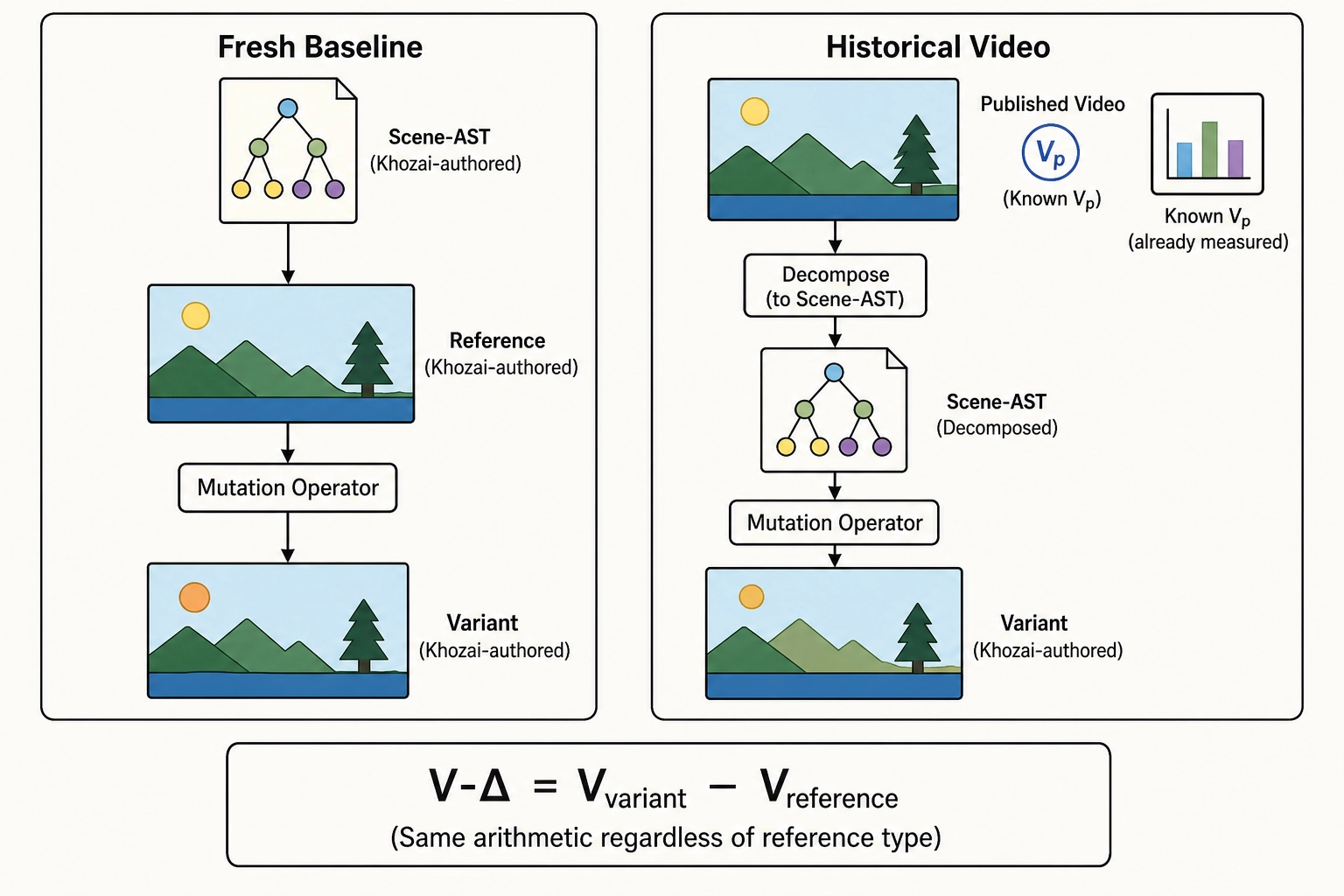
The framework treats two kinds of reference equivalently:
Fresh-generated baseline. The reference is a video that Khozai created from a scene-AST specification. Its V-vectors are measured at creation time. The variant is produced by applying an operator to the same AST, rendering, and measuring the result. Both reference and variant are Khozai-authored. This is the purest experimental setup: the reference was designed for the experiment.
Historical video. The reference is an existing video - one the creator already published, with already-observed Vp. Its V-vectors are extracted after the fact. The variant is produced by loading the historical video into a scene-AST representation (decomposing it into scenes, assets, durations, audio mix, captions), applying an operator, rendering, and measuring the result. The historical video’s Vp is already known; the variant’s Vp is collected after publication.
The framework treats both equivalently because V-delta is defined as V_variant minus V_reference regardless of how the reference was produced. The arithmetic does not care whether the reference was authored for the experiment or pulled from an archive. Both produce a V-delta profile that the correlation engine can map to a Vp difference.
The hybrid workflow
The historical-video reference enables the hybrid workflow: pick a historical video whose Vp is already known, mutate one property forward from it, publish the variant, and compare outcomes. This combines observational grounding - the historical video has real measured engagement data, not synthetic baseline assumptions - with experimental causal identification: the forward mutation produces a clean, verified V-delta on a single property.
The hybrid workflow is particularly valuable given Khozai’s operating scale. Platform ad engines learn from billions of impressions. Khozai operates at individual scale - hundreds to thousands of experiments, not billions. Starting from content that has already demonstrated engagement gives each experiment more leverage than starting from a synthetic baseline whose engagement level is unknown. The historical video’s Vp anchors the experiment to a known behavioral outcome; the mutation tests whether a specific property change moves that outcome up or down. This is a practical adaptation of the single-variable principle to a context where every experiment is expensive.
3. Types of Mutations: The Operator Vocabulary
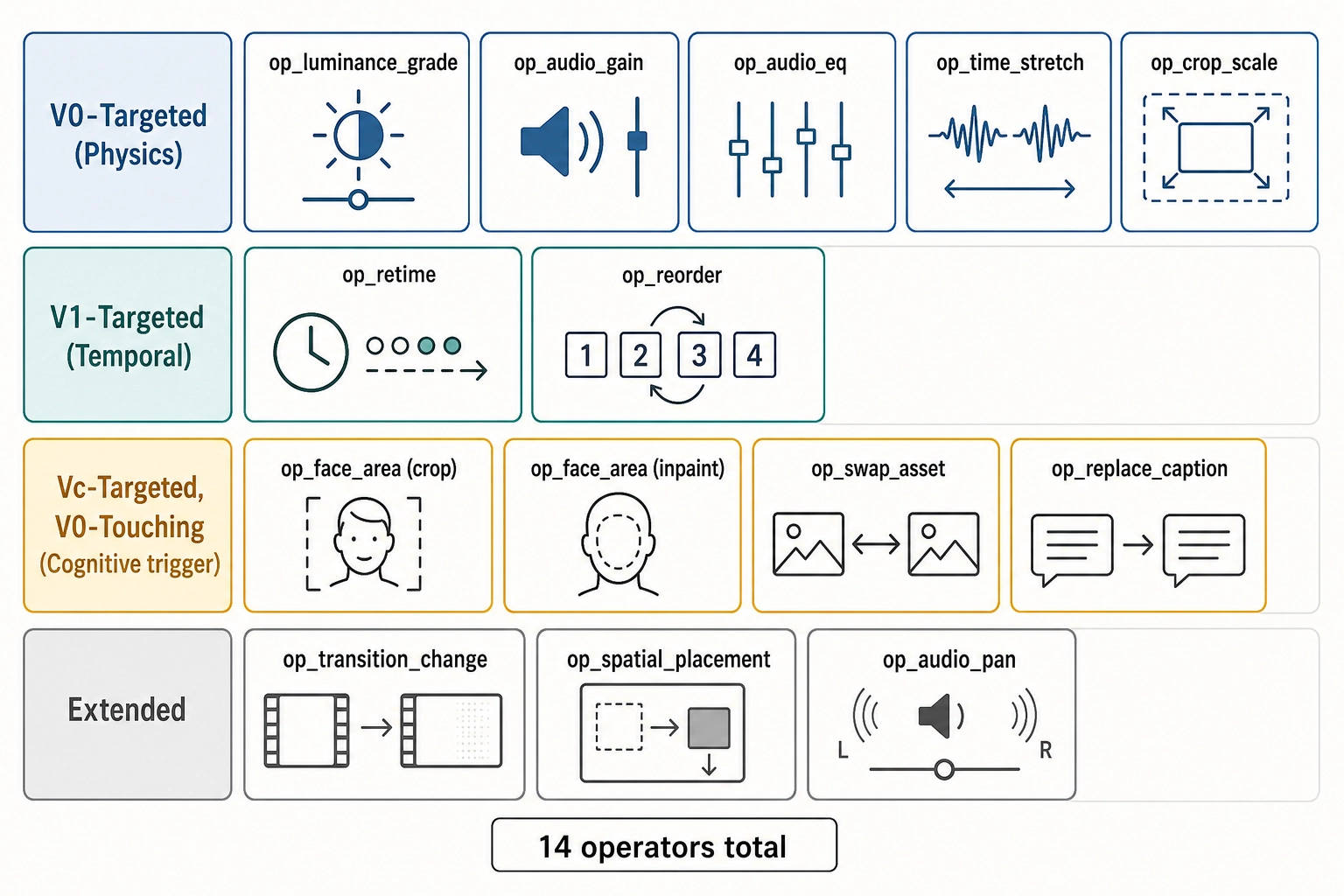
A mutation in Khozai is not a free-form edit. It is an application of a typed operator from a locked vocabulary. The operator vocabulary (Phase 7, locked) defines fourteen operators in v1, each of which declares what it targets, what it touches, what it holds constant, what it expects to propagate, and how it is verified. The operators fall into four categories by target layer and trigger mechanism.
The following table summarizes all fourteen operators:
| # | Tier | Operator | What it changes | V0/V1/V2 channels affected |
|---|---|---|---|---|
| 1 | V0-targeted | op_luminance_grade | Gain-offset-gamma curve on pixel luminance | V0: luminance stats; V1: luminance-derived temporal; V2: luminance slope |
| 2 | V0-targeted | op_audio_gain | Linear gain on audio waveform | V0: RMS energy, FFT power, peak amplitude; V1: energy channels |
| 3 | V0-targeted | op_audio_eq | Parametric EQ reshaping spectral distribution | V0: spectral centroid, spectral shape; V1: spectral channels |
| 4 | V0-targeted | op_time_stretch | Phase-vocoder playback speed change | V0: duration, frame spacing, audio waveform; V1: pacing (cuts/s); V2: shape, momentum |
| 5 | V0-targeted | op_crop_scale | Sub-region selection + Lanczos-3 rescale | V0: all pixel-domain channels |
| 6 | V1-targeted | op_retime | Scene duration scaling with audio sync | V1: pacing, energy channels |
| 7 | V1-targeted | op_reorder | Scene-order permutation | V1: pacing at boundaries; V2: shape channels (arc direction may flip) |
| 8 | Vc-targeted, V0-touching | op_face_area (crop) | Face bounding-box crop + scale (tier 1) | V0: all pixel-domain channels |
| 9 | Vc-targeted, V0-touching | op_face_area (inpaint) | Content-aware face resize with inpainting (tier 2) | V0: all pixel-domain channels |
| 10 | Vc-targeted, V0-touching | op_swap_asset | Whole-asset replacement from library | V0: all channels in asset span; V1: pacing if duration differs; V2: shape if arc changes |
| 11 | Vc-targeted, V0-touching | op_replace_caption | On-screen text content swap | V0: pixel-domain text region |
| 12 | Extended | op_transition_change | Scene-boundary transition type | V1: pacing at boundaries |
| 13 | Extended | op_spatial_placement | Asset repositioning within frame | V0: pixel-domain channels; potentially Vc compositional framing |
| 14 | Extended | op_audio_pan | Stereo balance shift | V0: stereo waveform (mono-derived invariant) |
| 15 | Extended | op_regenerate_clip | Generative clip replacement (tier 2: reference-frame; tier 3: text-to-video) | V0: all channels in asset span; V1: pacing if duration differs; V2: shape if arc changes |
The table lists fourteen distinct operator names. op_face_area has two implementation paths (crop and inpaint) but counts as a single operator. op_regenerate_clip spans two tiers (tier 2: reference-frame variant; tier 3: text-to-video variant) but is likewise a single operator.
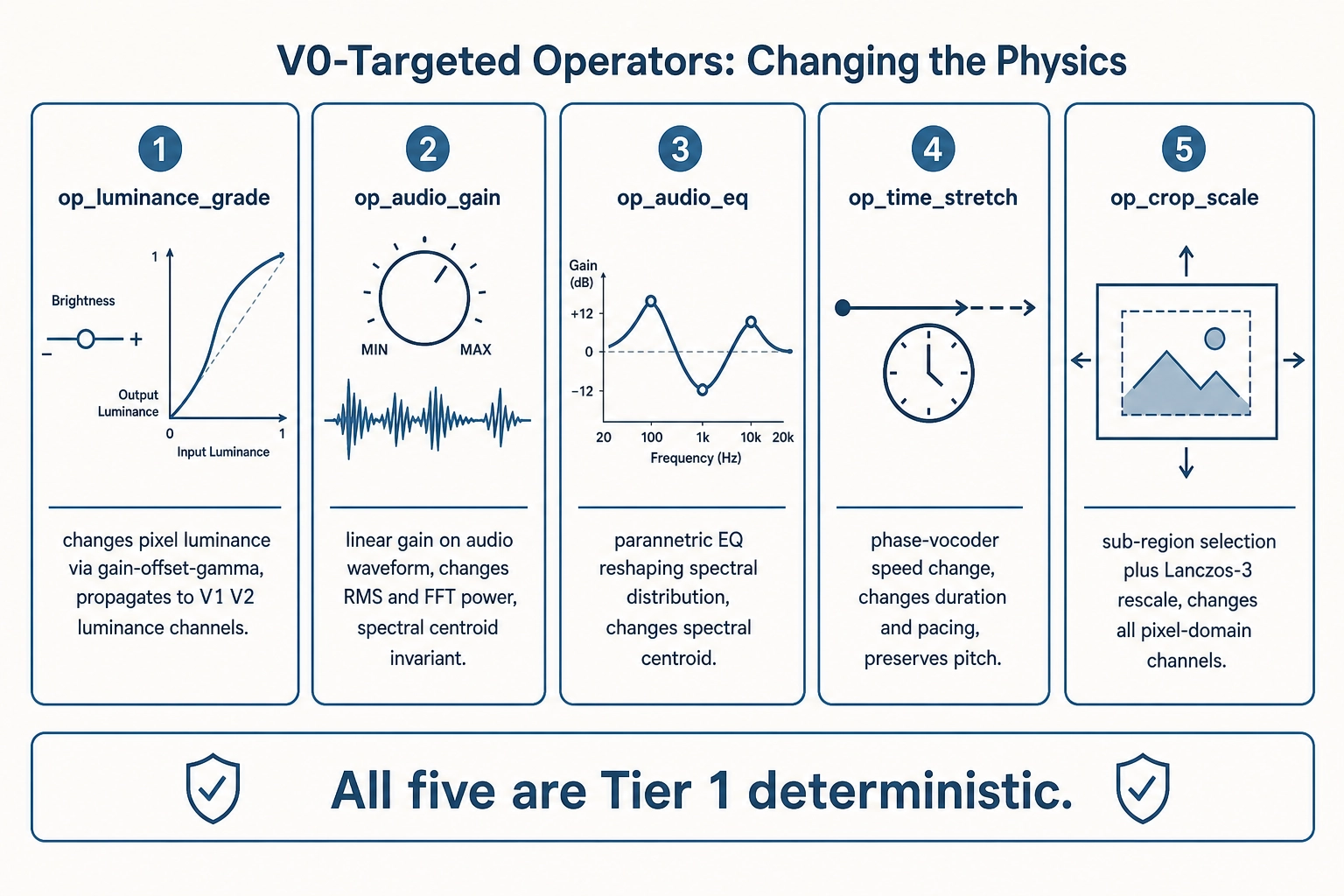
V0-targeted operators: changing the physics
Five operators target V0 - the physics layer - directly. They change pixel values, audio samples, or temporal structure without requiring any cognitive recognition as a trigger.
op_luminance_grade applies a gain-offset-gamma curve to the linear-light pixel values of a scope (a single asset, a segment, a scene, or the whole project). It changes luminance statistics (V0) and propagates through luminance-derived V1 and V2 channels. For moderate grading - gain between 0.5 and 2.0 - the Vc and Vn layers are expected to remain invariant: the vision-language model still recognizes the same objects and faces, and the brain encoding model predicts a small shift in early visual cortex proportional to the brightness change, with higher-order cortical areas unaffected. Extreme grading (near-black, near-white) can cause object-detection failures in Vc, which is a declared side-effect, not a surprise.
op_audio_gain applies a linear gain to the audio waveform. It changes RMS energy, FFT power, and peak amplitude (V0) while leaving the spectral centroid and zero-crossing rate invariant: uniform scaling does not change the frequency-weighted mean or the waveform’s sign pattern. Moderate gain changes propagate to V1 energy channels proportionally and leave Vc invariant. Extreme attenuation below audibility can cause the vision-language model to lose speech detection.
op_audio_eq applies a parametric equalizer - a bank of second-order IIR peaking filters (IIR: infinite impulse response, the standard filter topology in audio processing, NCJ) - that reshapes the spectral distribution without necessarily changing the total energy. It shifts the spectral centroid (the frequency-weighted mean of the spectrum, in hertz) and changes V1 spectral channels. The distinction from op_audio_gain is that EQ changes the shape of the audio spectrum while gain changes its level. The brain encoding model predicts a shift in auditory cortex activation pattern proportional to the spectral-shape change.
op_time_stretch changes the playback speed of a segment or scene using a phase-vocoder algorithm (phase vocoder: the standard time-stretch technique that changes duration while preserving pitch, NCJ). It changes the file’s duration, the temporal spacing of frames, and the audio waveform, while preserving the per-frame spatial pixel content and the audio pitch. Pacing channels in V1 shift because cuts per second changes with the tempo; V2 shape and momentum channels shift because the file’s temporal structure is different.
op_crop_scale selects a sub-region of the frame and scales it back to the project resolution using Lanczos-3 resampling (Lanczos: a deterministic resampling filter, NCJ). It changes every pixel-domain V0 channel because the spatial content of the frame is different. This operator is the building block for the face-area mutation described below.
V1-targeted operators: changing temporal structure
Two operators target V1 - the first-order temporal pattern layer - by changing the scene ordering and timing structure of the video without changing the per-frame spatial content.
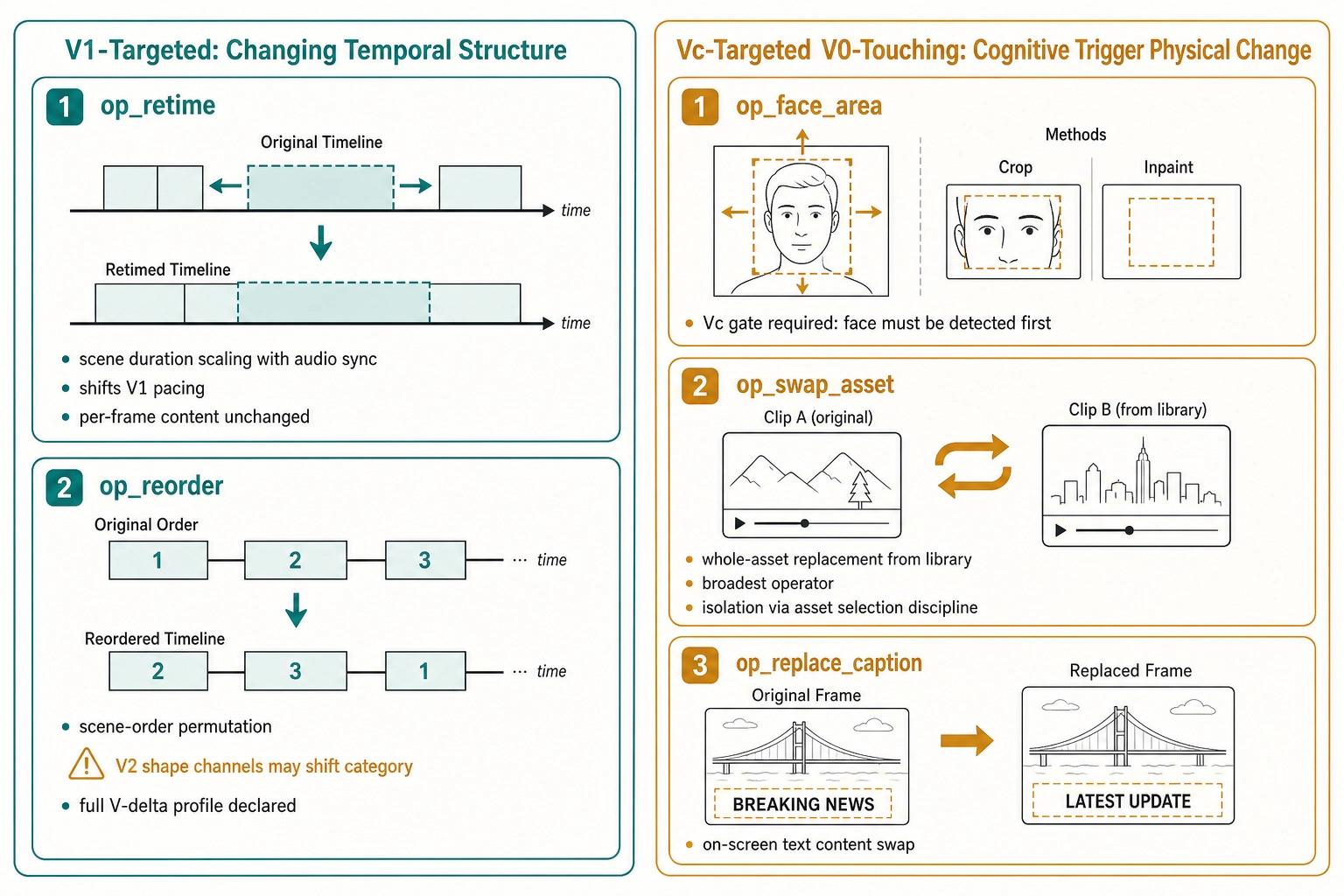
op_retime changes the duration of a specific scene, scaling its segments proportionally and time-stretching its audio to maintain synchronization. It shifts V1 pacing and energy channels because the scene now occupies a different fraction of the file’s timeline. The per-frame pixel content within the scene is unchanged.
op_reorder permutes the order of scenes in the project timeline. This is a hard case for isolation: reordering scenes does not change any scene’s internal content, but it changes the temporal arc of the entire file. V2 shape channels - where in the file the energy peaks, whether the pacing rises or falls - may shift category entirely (from “rising” to “falling,” for example). Vc narrative-arc dimensions shift because the story unfolds in a different order. Vn shifts because the brain encoding model receives a temporally different stimulus. The operator does not guarantee V1-level isolation: it is a whole-file structural change, and the framework measures the full V-delta profile rather than pretending the change was contained.
Vc-targeted, V0-touching operators: cognitive trigger, physical change
Three operators require cognitive recognition (Vc) to identify the target and then produce changes at the V0 pixel level. Per Chapter 2’s Tool 10 (Space Assignment), these operators are classified as Vc-targeted, V0-touching: the trigger requires recognizing a cognitive category (a face, an object, a scene), and the change touches pixels. This classification matters because it makes the cross-layer nature of the mutation explicit: it is not a pure V0 change and not a pure Vc change, but a Vc-gated transformation of V0 data.
op_face_area is the canonical example. The operator requires vc_face_present == true as a precondition: the system must recognize that a face exists before it can change the face’s area as a fraction of the frame. Two methods implement the change. The crop_to_face method uses op_crop_scale internally, centering the crop on the detected face bounding box and scaling to produce the target face-area fraction - this is deterministic (tier 1) but removes scene context outside the crop. The scale_face_region method uses content-aware inpainting (algorithmically filling in removed or resized regions to match the surrounding pixels) to resize the face within the frame while preserving the background - this is generative (tier 2) and introduces the stochastic variance that the verification pipeline manages through rejection sampling (generating multiple candidates and discarding those that fail the isolation check).
The face-area operator declares specific Vc isolation commitments: face identity and facial expression are held constant (the operator does not change who the person is or what expression they are making). Scene composition is declared as a potential side-effect: cropping to a face necessarily removes objects and setting context outside the crop region. This is honest engineering: the operator states what it can and cannot isolate, and the verification pipeline measures whether the promise held.
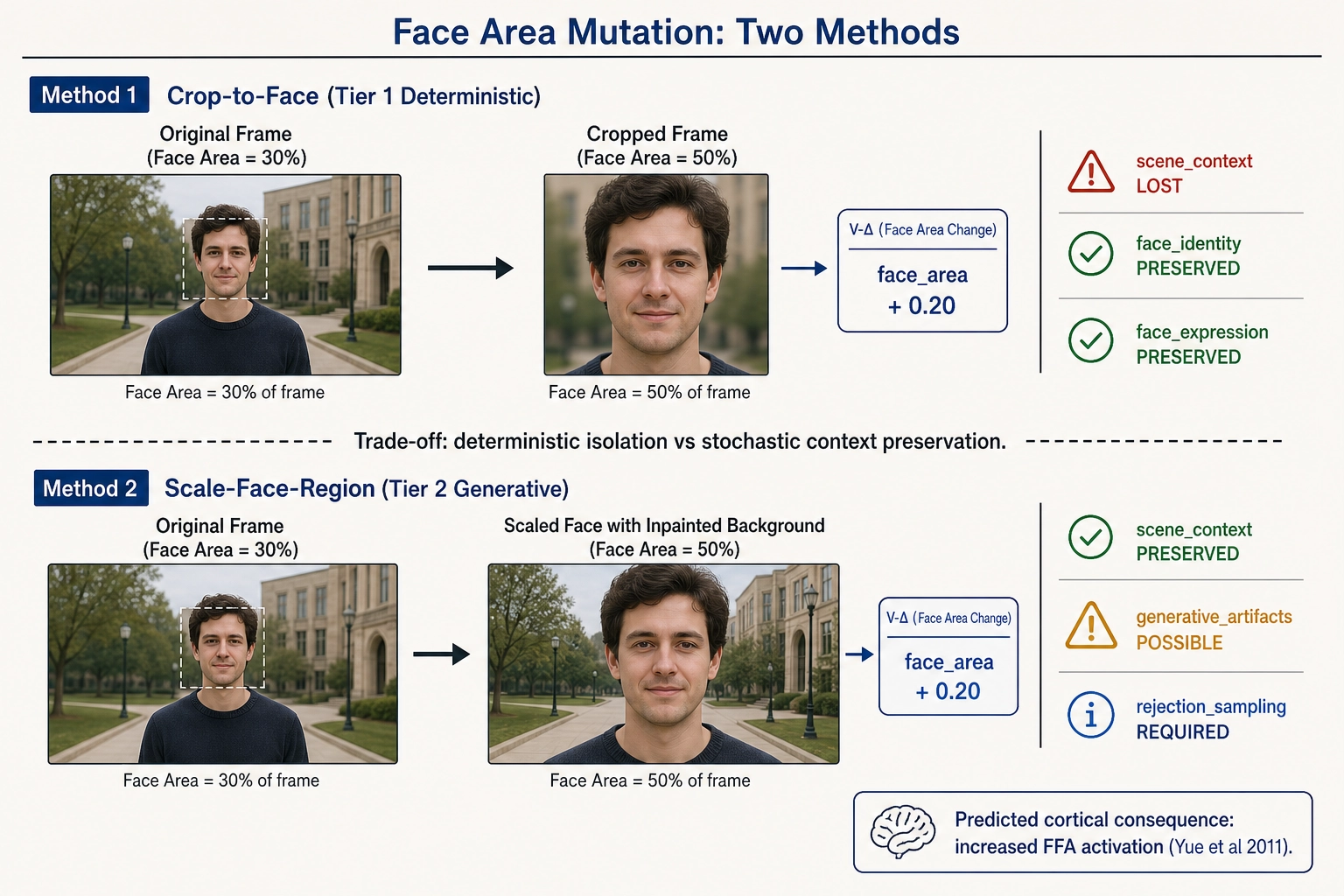
The predicted cortical consequence is concrete. Increasing face area is expected to increase activation in the fusiform face area (FFA - the cortical region with dedicated neural machinery for face processing). This expectation is grounded in evidence that FFA responses vary parametrically with face size, not just categorically with face presence [10]. The cited evidence (Yue et al., 2011) used static images under controlled laboratory conditions; whether parametric face-size sensitivity persists in the continuous, attention-divided context of short-form video viewing is an open question that Bet 2 is designed to test. This is the canonical worked example the correlation engine will use in Chapter 9: larger face, stronger FFA activation, stronger social-processing engagement, potential retention shift.
op_swap_asset replaces one asset in a scene with a different asset from the asset library. This is the broadest and the least isolated Vc-targeted operator: swapping an entire clip changes everything within that clip’s temporal span. Isolation is achieved not by the operator but by the experimenter’s discipline in selecting the replacement asset: if the replacement was chosen to match the original on every Vc dimension except one (same setting, same face count, different expression), then the isolation comes from the asset-selection step, not from the operator. The verification pipeline confirms the match.
op_replace_caption changes on-screen text content. It targets vc_text_on_screen while holding non-text Vc dimensions constant, as long as the caption is not the primary semantic carrier of the video. When the caption is the primary carrier (a text-only animation, for instance), the operator declares that all per-video Vc dimensions may shift.
Extended operators
Four additional operators round out the v1 vocabulary: op_transition_change (changing the transition type between scenes - cut to dissolve, dissolve to fade-to-black - which affects V1 pacing at scene boundaries), op_spatial_placement (repositioning an asset within the frame, changing pixel-domain V0 channels and potentially Vc compositional framing), op_audio_pan (shifting the stereo balance, which changes the stereo waveform while leaving mono-derived channels invariant), and op_regenerate_clip (generating an entirely new asset using a generative model, the highest-variance operator, managed through the rejection-sampling protocol described in Section 4).
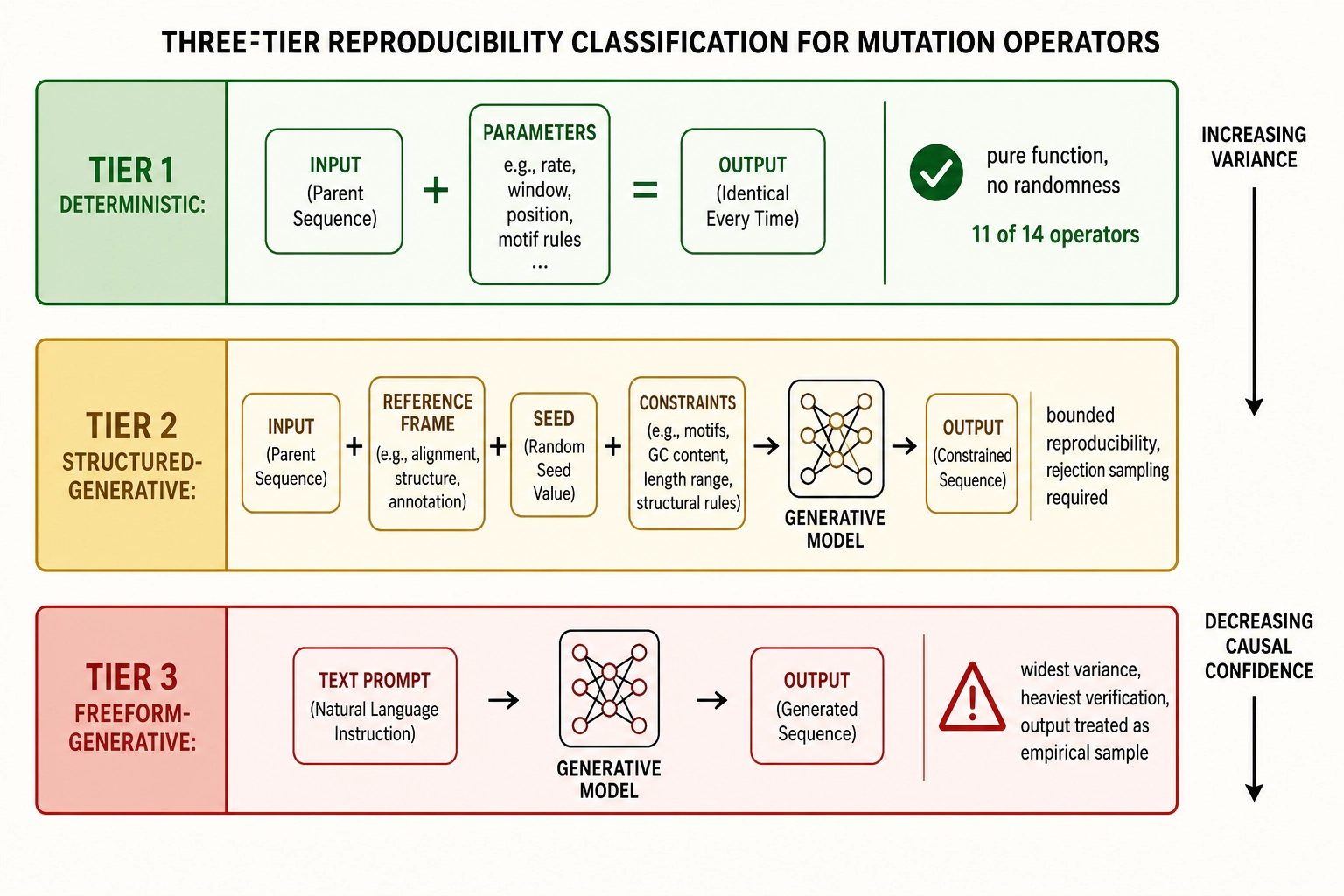
Generative versus deterministic: the tier system
Each operator carries a tier classification that determines its reproducibility contract.
Tier 1 (deterministic): the operator is a pure function of its parameters. Given the same input and the same parameters, two independent applications produce identical output. No random seed, no generative model. Eleven of the fourteen operators are tier 1, including all V0-targeted and V1-targeted operators, the crop-to-face method of op_face_area, op_swap_asset, and op_replace_caption.
Tier 2 (structured-generative): the operator invokes a generative model but anchors the generation with a reference frame, a fixed seed, and a constrained prompt. Reproducibility is bounded but not guaranteed across hardware contexts. The scale-face-region method of op_face_area and the reference-frame variant of op_regenerate_clip are tier 2. Generated assets go through rejection sampling before they enter the asset library.
Tier 3 (freeform-generative): the operator invokes a generative model without a reference-frame anchor. The output is treated as an empirical sample whose V-vectors are ground truth for downstream comparison. The text-to-video variant of op_regenerate_clip is tier 3. This is the widest-variance tier and carries the heaviest verification burden.
The tier system is the mutation engine’s way of being explicit about where stochasticity lives. Tier 1 operators produce predictable V-delta profiles; the verification pipeline confirms the prediction. Tier 2 and 3 operators produce variable V-delta profiles; the rejection-sampling protocol selects the candidate whose profile is closest to the target.
4. Technical Implementation: The Scene-AST Substrate
The previous sections described what the mutation engine does: controlled single-variable changes on a locked operator vocabulary. This section describes how it does it, and why the implementation architecture matters for the framework’s claims about isolation and verification.
The obvious-first solutions and their failure modes
Two natural approaches to controlled video mutation present themselves immediately, and both fail in ways that are worth narrating because the failure modes motivate the architecture Khozai actually uses.
Approach 1: let the agent edit videos. Give an AI agent access to a video editing tool - Adobe Premiere, DaVinci Resolve, or a programmatic equivalent - and instruct it: “increase the face area by 20% and do not change anything else.” The agent would use its judgment to crop, scale, or reframe the video. The problem is perceptual disputability: when the agent makes a judgment call (how much background to keep, where to center the crop, whether to inpaint the edges), the result is a function of the agent’s interpretation, not a function of a declared specification. Two runs of the same instruction on the same video may produce different results. The V-delta is not reproducible. And when the correlation engine asks “did the face-area change cause the retention shift, or did the agent’s incidental reframing choices cause it?”, the answer is indeterminate because the agent’s choices were not declared, not measured, and not held constant.
Approach 2: let the generator hit the spec. Give a generative video model a target specification - “generate a 15-second clip identical to this reference but with the face occupying 50% of the frame instead of 30%” - and let the generator produce the result. The problem is generative noise: the generator cannot reproduce the reference exactly. Every pixel, every audio sample, every frame is regenerated from scratch. The V-delta is not just the face-area change - it is the face-area change plus thousands of incidental pixel differences, audio artifacts, style drift, and generative hallucinations. The targeted V-delta is contaminated by generative variance that is neither declared nor measurable in advance.
Both approaches share a root cause: the specification of “what to change” and “what to hold constant” is implicit in the tool’s behavior rather than explicit in a data structure. The agent interprets the instruction; the generator approximates the specification. Neither provides a guarantee that can be verified against a declared contract.
The resolution: a deterministic substrate with contained stochasticity
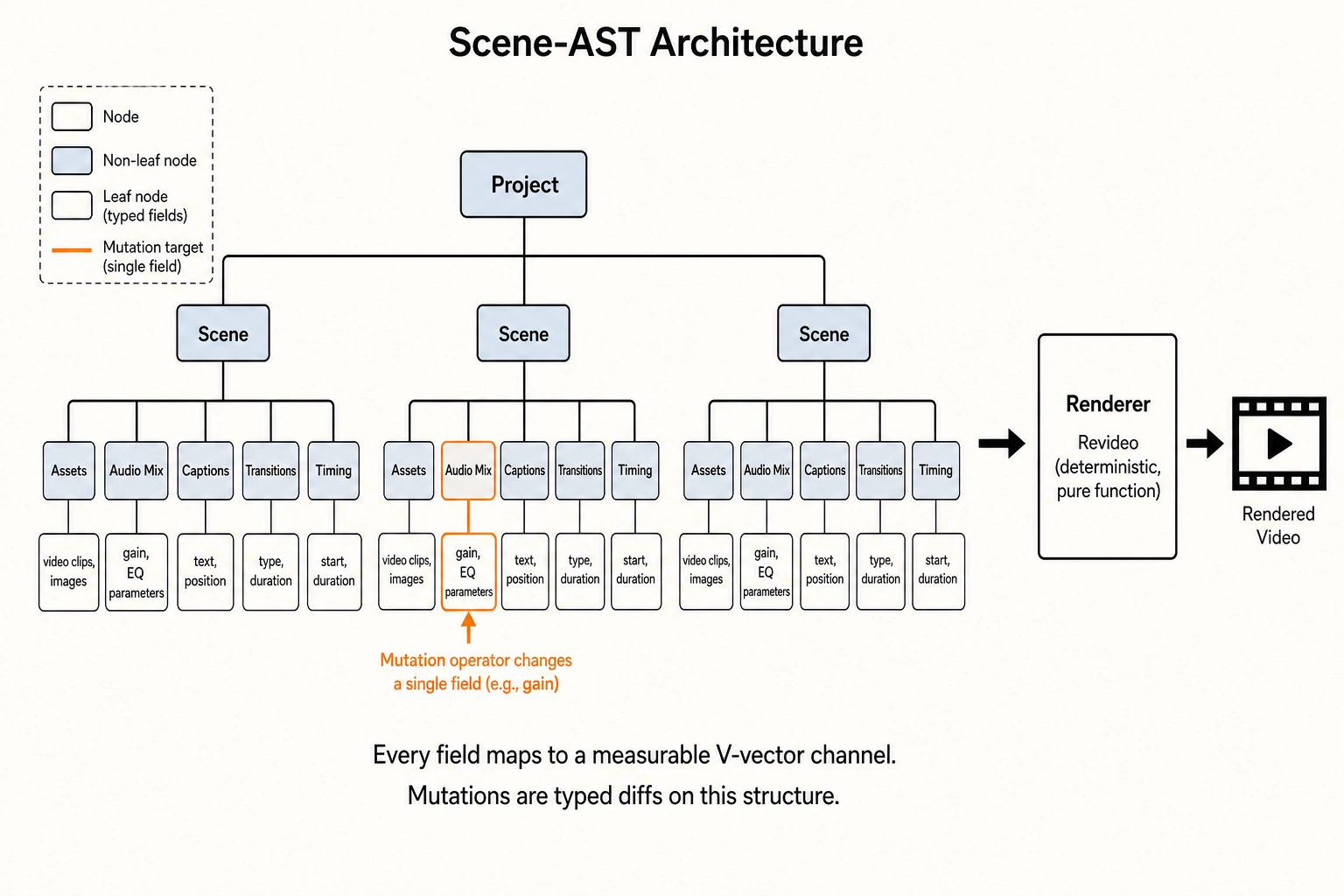
The mutation engine resolves both failure modes by pushing the specification onto a deterministic substrate - the scene-AST - and containing stochasticity to named, typed, rejection-sampled asset slots.
The scene-AST (scene abstract syntax tree: the typed configuration structure that defines a video before rendering) is the data model that specifies everything about a video: which assets appear, in which scenes, at which positions, for how long, with which transitions, which captions, which audio mixing parameters, which post-processing operators applied at which scope. The renderer - a fork of Revideo, the MIT-licensed TypeScript-based programmatic video editing framework (https://github.com/redotvideo/revideo, MIT License) - is a pure function of this configuration. Given the same scene-AST and the same asset library, two independent renders produce identical encoded output. The video is not an opaque binary blob; it is a typed, auditable, diffable configuration object whose every field maps to a measurable property of the rendered output.
This architecture makes three things possible that the obvious-first approaches could not provide.
Mutations are schema-validated diffs. A mutation is not “edit the video.” It is “apply this typed diff to this AST field.” The diff declares exactly which fields change and to what values. The verification pipeline’s first layer - structural verification - checks that the diff was applied as specified and that no unintended fields changed. This is a deterministic check on a data structure, not a perceptual judgment on a rendered video.
Isolation is structurally auditable. Because the AST declares every field that contributes to a V-vector channel (the channel-to-AST map covers all 109 content-side channels: 25 V0, 16 V1, 12 V2, 32 Vc, 24 Vc-temporal, plus Vn’s 360 Glasser areas), an operator that changes one AST field can declare, at the schema level, which V-vector channels are affected and which are structurally guaranteed to be invariant. When op_audio_gain changes the gain parameter in the AudioMix block, the pixel-domain V0 channels are structurally invariant because the diff touches no pixel-related field. This is stronger than a statistical test on the rendered output: it is a structural proof from the data model.
Stochasticity is contained to named asset slots. The only place in the pipeline where generative models produce content is the asset library. An AI-generated clip - the output of a text-to-video or image-to-video model - enters the library as a named asset with a recorded prompt, seed, model version, reference frames, and measured V-vectors. The asset goes through rejection sampling: N candidates are generated, each is measured, and the candidate whose V-vectors are closest to the target on the mutation dimension and closest to zero-delta on isolation dimensions is selected. The stochastic part of the pipeline (the generative model) is bounded by a measurement-and-selection loop that imposes V-vector constraints on the output before it ever enters the AST.
Hard cases
Three hard cases test the architecture’s limits.
Changing cut rate without changing scene content. Cut rate is a V1 property: the number of visually discontinuous boundaries per second. On the AST, cut rate is determined by how many scenes there are, how long each lasts, and what transition types separate them. To increase cut rate from 1.0 to 2.0 cuts per second, the mutation can either split existing scenes into shorter sub-scenes (using op_retime) or reorder scenes to create more visual discontinuities at the boundaries (using op_reorder). Neither approach changes the per-frame spatial content within any scene: the same frames appear in the same order within each scene. But both approaches change the temporal structure of the file, which shifts V2 shape channels (the energy arc may change from “rising” to “peaked”), Vc narrative dimensions (the story unfolds at a different rhythm), and Vn (the cortical encoding model is temporally sensitive). The mutation engine handles this by declaring the full V-delta profile - the targeted V1 change plus all the expected propagation - and verifying each layer against its declared tolerance. The experimenter knows that “cut rate +1.0” is not a pure V1 change; it is a V1 change with declared V2, Vc, and Vn side-effects. The correlation engine receives the full V-delta profile and can control for the side-effects in its analysis.
Changing face area without changing identity. Face area is a Vc-targeted property - recognizing a face is a cognitive operation - that produces V0 pixel changes. The crop-to-face method solves the identity problem (the same face pixels are preserved, just scaled) but creates a scene-composition side-effect (the background is cropped away). The scale-face-region method preserves the background through inpainting but introduces generative artifacts at the face-background boundary. Neither method changes which face is present or what expression it has - both preserve face identity and expression by construction. The trade-off between the two methods is explicit: deterministic isolation of face identity versus stochastic preservation of scene context. The experimenter chooses based on whether the experiment’s hypothesis is about face size in isolation (use crop) or face size in context (use inpainting, accept the generative variance, rely on rejection sampling).
Generative versus deterministic operators on the same video. A single video can have tier-1 operators applied to some scenes (a luminance grade on scene 1, a time-stretch on scene 3) and a tier-2 operator on another scene (a face-area change with inpainting on scene 2). The verification pipeline runs the appropriate checks per operator per scene. The rendered output’s V-delta profile records the full picture: deterministic, verified changes in scenes 1 and 3; stochastic, rejection-sampled changes in scene 2. The tier tag travels with the mutation into the correlation engine’s causal-confidence weighting: tier-1 mutations get higher causal confidence than tier-2, and tier-2 gets higher than tier-3.
The four-layer verification pipeline
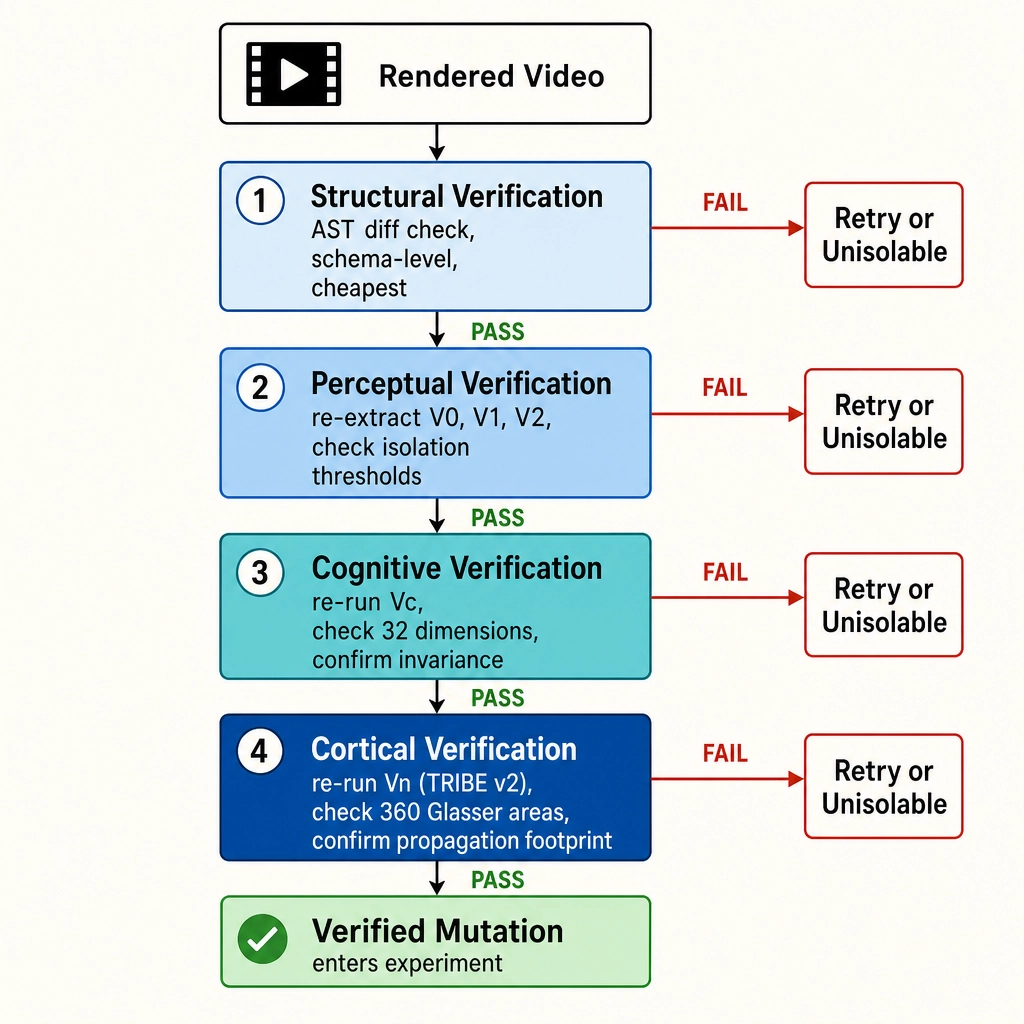
The verification pipeline runs on every rendered output and checks four layers in strict order, each gated by the mutation’s target V-vector.
| Layer | Name | What it checks | Scope |
|---|---|---|---|
| 1 | Structural verification | AST diff applied as specified; no unintended fields changed | Schema-level equality check on data structure; cheapest, most deterministic layer; runs on every mutation |
| 2 | Perceptual verification | Re-extracts V0, V1, V2 from rendered output; targeted channel V-delta within tolerance; all isolation channels below threshold | Catches physics-level leakage (e.g., luminance grade must not shift audio RMS above noise floor) |
| 3 | Cognitive verification | Re-runs Vc on rendered output; computes Vc-delta across all 32 dimensions; confirms target dimension shifted or Vc invariance held | Catches cases like extreme luminance change causing VLM object-detection failure |
| 4 | Cortical verification | Re-runs Vn (TRIBE v2); computes Vn-delta across 360 Glasser areas; checks Vc-Vn consistency signal | Confirms cortical-activation propagation matches declared footprint; flags inconsistencies (e.g., face-area increase with no FFA shift) |
The layers are sequential, not parallel. A failure at any layer halts the sequence and routes to the failure-handling protocol. The failure protocol has three escalation levels: asset-level retry (regenerate the stochastic asset, score the new candidate against V-vector targets), operator-level retry (adjust the operator’s parameters within its declared range and re-apply), and unisolable classification (after exhausting retries, log the mutation as “unisolable on this footage” - the operator, on this specific reference video, could not produce the intended change while keeping isolation channels within bounds). Only mutations that pass all four layers enter the experiment.
The worst-case resource ceiling before unisolable classification is 5 operator retries times 3 asset-rejection-sampling rounds times 10 candidates per round: 150 generated candidates. This is a bound, not a target; well-designed operators on compatible footage typically pass on the first attempt.
5. Experimental Design
A verified mutation is not yet an experiment. An experiment requires a design: how many arms, how many viewers, how the arms are deployed, and what statistical test will evaluate the result. The experimental design specification (Phase 7, locked) locks these choices for Khozai v1.
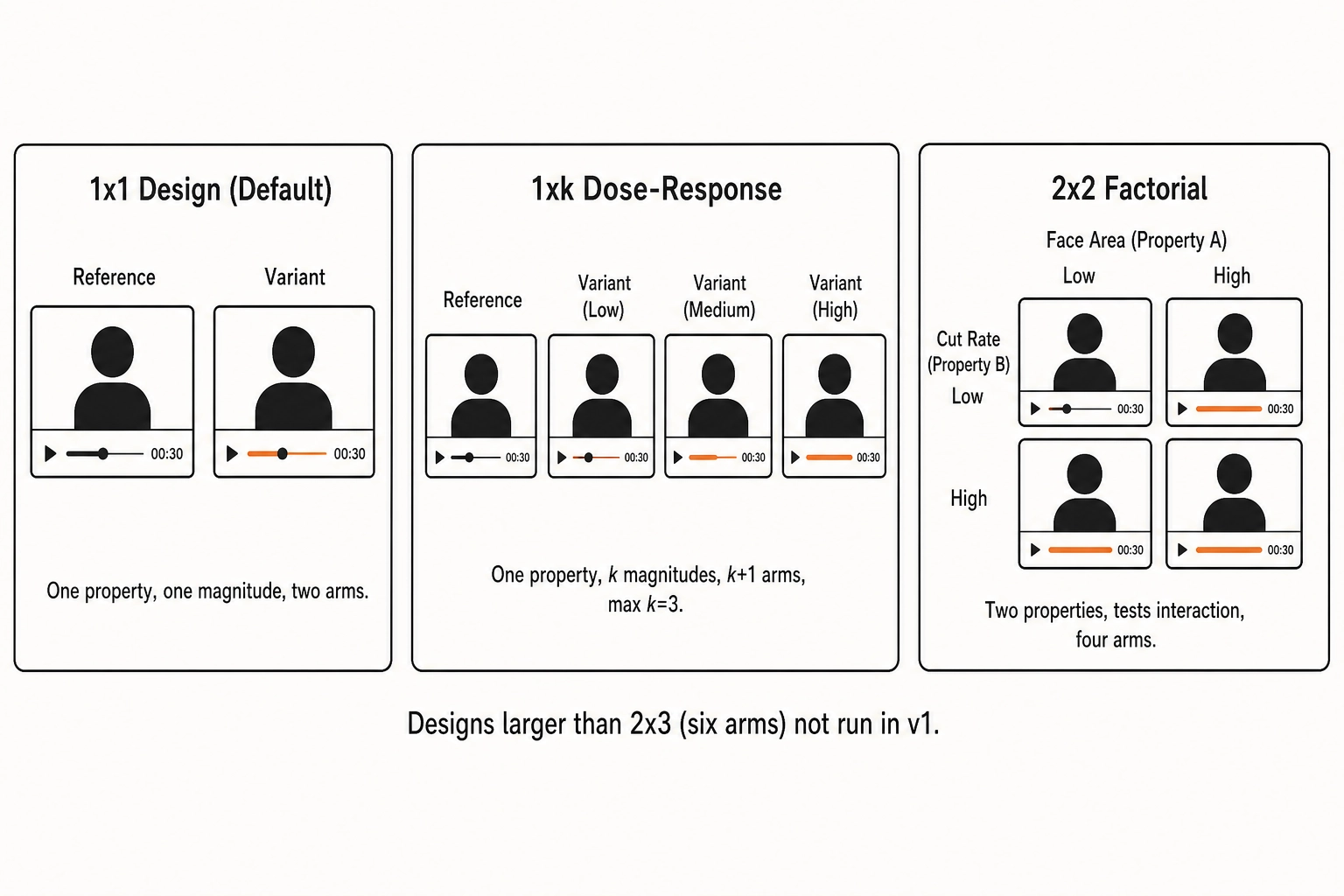
Factorial design: start simple, escalate with reason
The default experiment is a 1x1 design: one reference, one variant, one targeted V-vector change at one magnitude. Two arms. This is the default because the operator vocabulary is built around isolating a single property at a time, and every additional arm multiplies the sample-size requirement without adding a question. The 1x1 answers the question: “does this property change at this magnitude affect this Vp outcome?”
When the property of interest plausibly has a non-monotone or threshold relationship with the outcome - face area at 15%, 35%, and 55% of frame, for example, or cut rate at 1.0, 2.0, and 4.0 cuts per second - the design escalates to a 1xk dose-response with k = 2 or k = 3 levels plus the reference. Three is the maximum for a single-variable design in v1.
A 2x2 factorial is used only when the experiment is explicitly testing an interaction between two properties - “does the effect of face area depend on cut rate?” - not to save sample size by piggybacking two unrelated questions. Four arms. The interaction term is the question of interest.
Designs larger than 2x3 (six arms) are not run in v1. The combinatorial explosion of arms collides with per-platform budget constraints and sample-size requirements. Larger designs are deferred until the correlation engine has accumulated enough single-variable results to justify the cost.
Sample size: how many viewers per arm
The per-arm sample-size calculation uses the standard two-proportion z-test formula (the statistician Jacob Cohen, 1988) for rate-form Vp metrics (completion rate, view-through rate) and the standard two-sample t-test formula for continuous Vp metrics (average view duration). The locked defaults for v1 are: significance level alpha = 0.05 (two-sided), statistical power 1 - beta = 0.80, and a minimum detectable effect (MDE) of a 5% relative shift in the primary Vp outcome.
The 5% relative MDE is consistent with the 2-5% range that the online experimentation literature treats as standard for platform-scale tests [8][9]. Plugging these defaults into the proportions formula at a plausible baseline - a 28-day completion rate of 0.40 on short-form vertical video - produces approximately 9,400 viewer-completion observations per arm. For a 1x1 experiment, roughly 19,000 observations across both arms. For a 2x2, roughly 38,000.
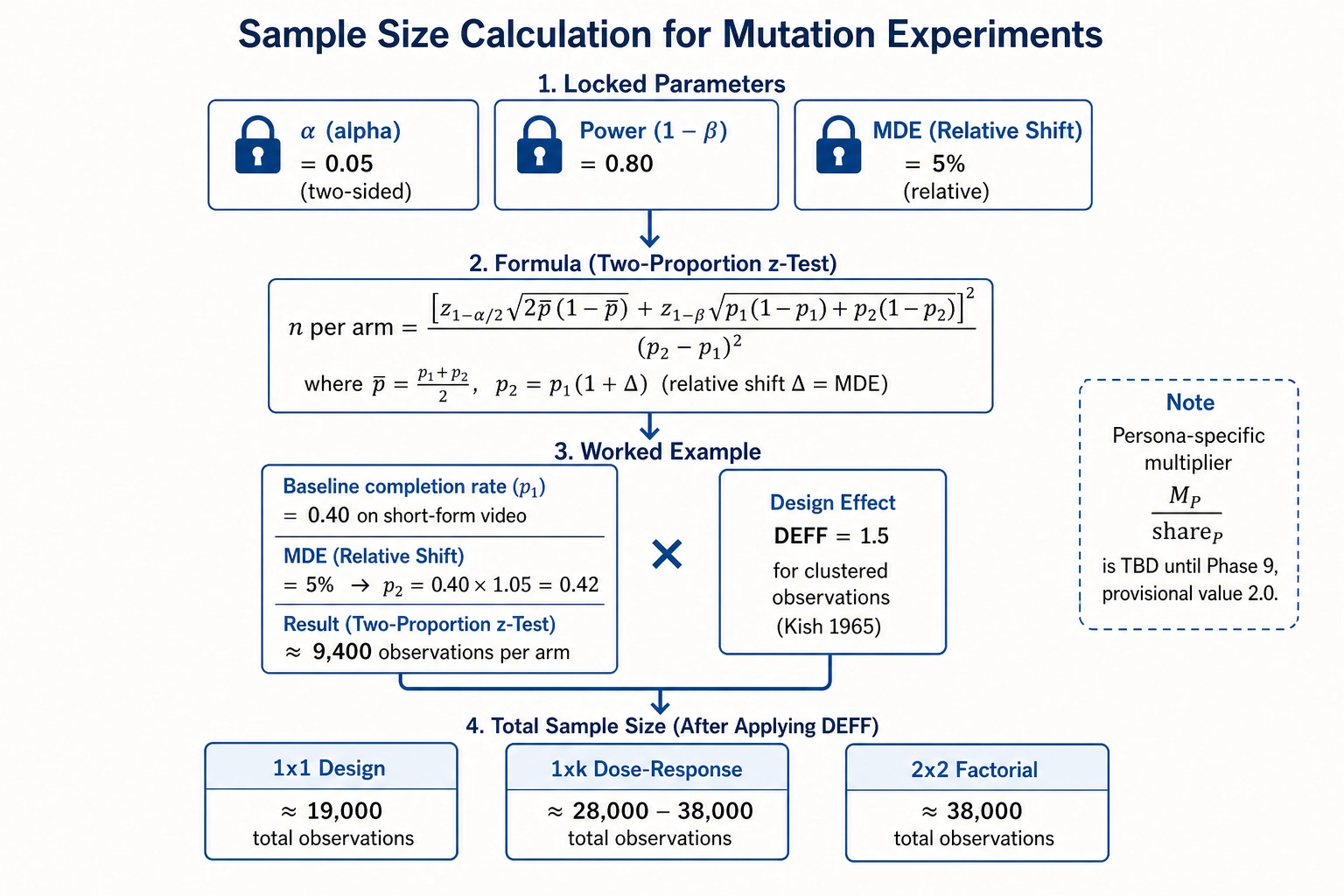
Platform impressions are not independent observations: the same viewer can see the content multiple times, recommendation clusters concentrate exposures, and engagement is heavy-tailed. A fixed design-effect inflation factor of DEFF = 1.5 is applied to every per-arm sample size, drawn from the survey-sampling tradition where design effects of 1.2 to 2.0 are standard for clustered observations (the survey methodologist Leslie Kish, 1965). Recent platform experiments confirm that interference between clustered users inflates variance substantially: The econometrician David Holtz and colleagues (2025) measured 19.76% bias in marketplace experiments without cluster randomization [11], and the computational social scientist Martin Saveski and colleagues (2017) demonstrated methods for detecting such network effects in randomized experiments [12]. DEFF = 1.5 is a conservative choice within this range.
Persona-aware sample sizes: the Phase-9 dependency
When the experiment’s primary question is about a specific persona rather than the average viewer - “does face area affect retention for this audience segment specifically?” - the per-arm sample size must be inflated by a persona-specific multiplier M_P divided by the persona’s expected share of impressions (share_P). The structural form is locked:
n_per_arm_persona = n_per_arm_default x DEFF x M_P / share_P
The numerical value of M_P is TBD until the Phase-9 persona specification lands. Phase 9 will define how personas are constructed from behavioral data, how many Khozai v1 maintains, and the per-persona within-cluster variance of each Vp metric that determines M_P. Until Phase 9 commits, every protocol that names a per-persona primary outcome carries an explicit placeholder: “M_P = TBD (Phase-9 dependency); provisional value 2.0.” The provisional value is a deliberate over-estimate, chosen large enough that the experiment is unlikely to be retroactively under-powered when Phase 9 lands. Every experiment launched under the provisional value records the provisionality and re-evaluates for primary-evidence eligibility once Phase 9 produces the real number.
This is the only sample-size parameter in the experimental design that is not numerically locked. The dependency is stated explicitly rather than papered over with a guess.
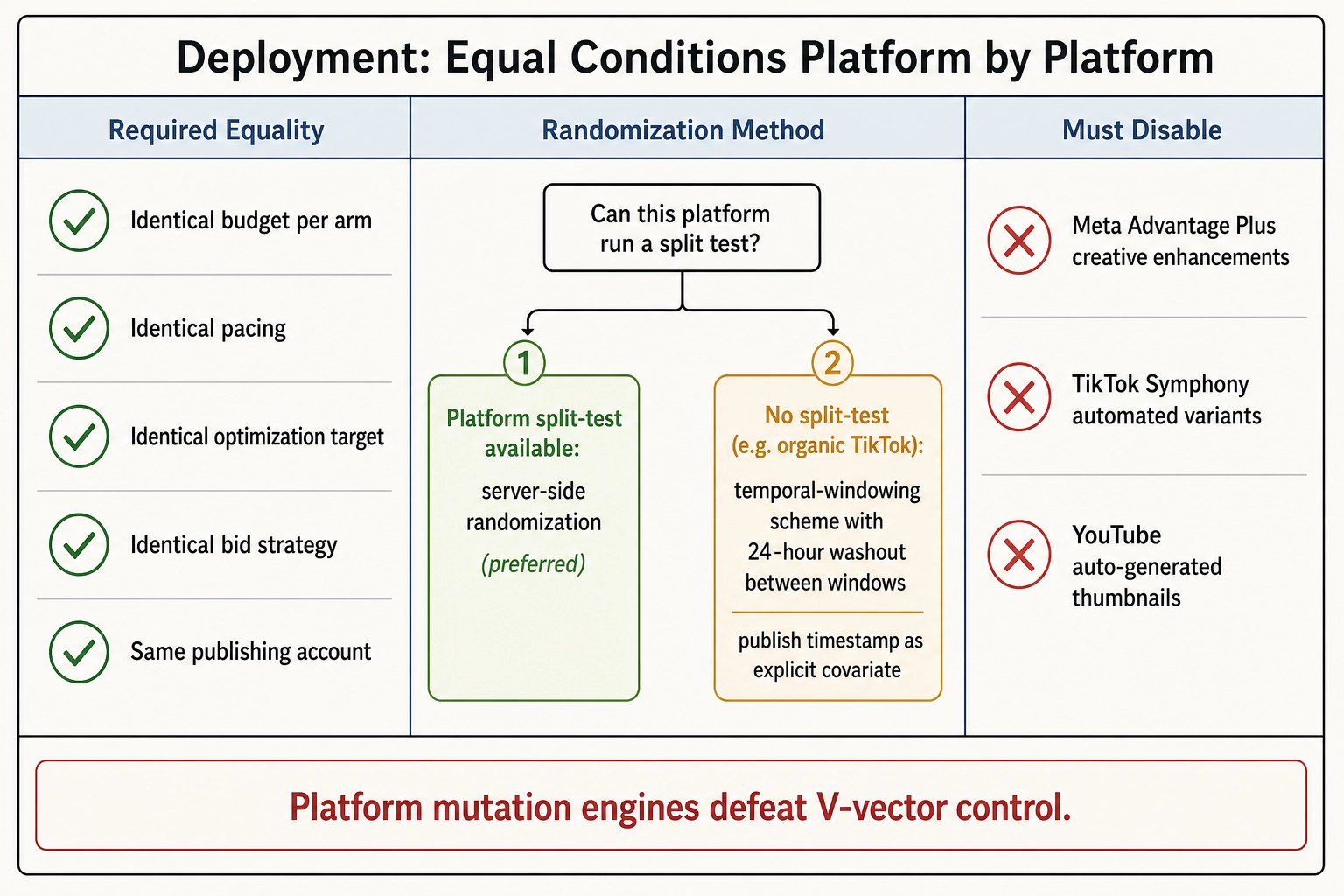
Deployment: equal conditions, platform by platform
All arms in an experiment receive identical budget, identical pacing, identical optimization-target settings, and identical bid strategy. The platform’s native split-test product is the default randomization mechanism: it randomizes impression assignment server-side, which is more trustworthy than any client-side scheme. When a platform does not expose a split-test product (organic-only experiments on TikTok, for instance), randomization degrades to a temporal-windowing scheme with a 24-hour wash-out between windows, and the experiment carries the publish timestamp as an explicit covariate.
Every arm is published from the same account. Different accounts have different distribution priors, follower bases, and platform-side scoring histories; they are not exchangeable.
Platform-side auto-mutation tools - Meta’s Advantage+ creative enhancements, TikTok’s Symphony automated variants, YouTube’s auto-generated thumbnails - are disabled at the campaign level. These are the platform’s own mutation engines, and they defeat Khozai’s V-vector control by producing variants the framework did not authorize and cannot measure.
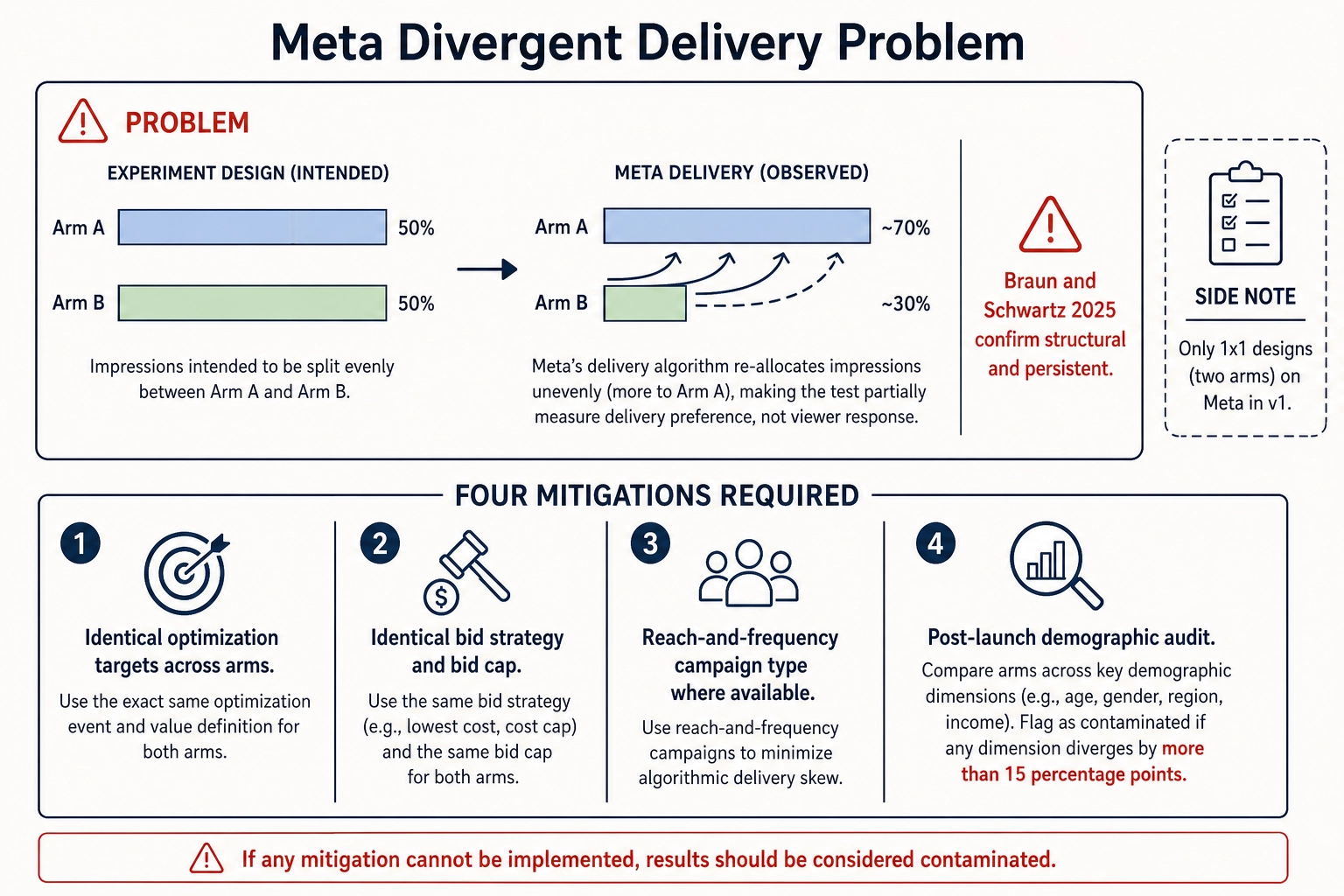
Meta’s divergent-delivery problem
Meta’s algorithmic delivery actively re-allocates impressions toward the arm it predicts will perform better, even when both arms are configured with identical budgets, audiences, and optimization targets. This divergent-delivery effect means that a naive A/B test on Meta partially measures delivery-system preference rather than viewer response to the V-delta [4]. The marketing researchers Michael Braun and Eric Schwartz (2025) confirm that this problem is structural to platform design and persists as of 2025, not a transient artifact of a particular algorithm version [13]. Every Meta experiment in Khozai v1 must implement four mitigations: identical optimization targets across arms, identical bid strategy and bid cap, reach-and-frequency campaign type where available [5], and a post-launch demographic-composition audit that flags the experiment as contaminated if any single demographic dimension diverges by more than 15 percentage points in impression share between arms. Additionally, only 1x1 designs (two arms) are run on Meta in v1: multi-arm designs compound the divergence problem because the platform re-ranks all arms simultaneously.
6. Mapping 5: Feedback Loops
Chapter 2 Section 3.5 defined Mapping 5 as two feedback pathways that close the loop in the framework’s information flow. The first is Experience to Neural State Space: conscious awareness modulates subsequent neural processing (noticing changes how the brain processes the next moment). The second is Behavioral Output to Physical Stimulus Space: actions change the physical world, producing new stimuli (scrolling to the next video, sharing a link, commenting).
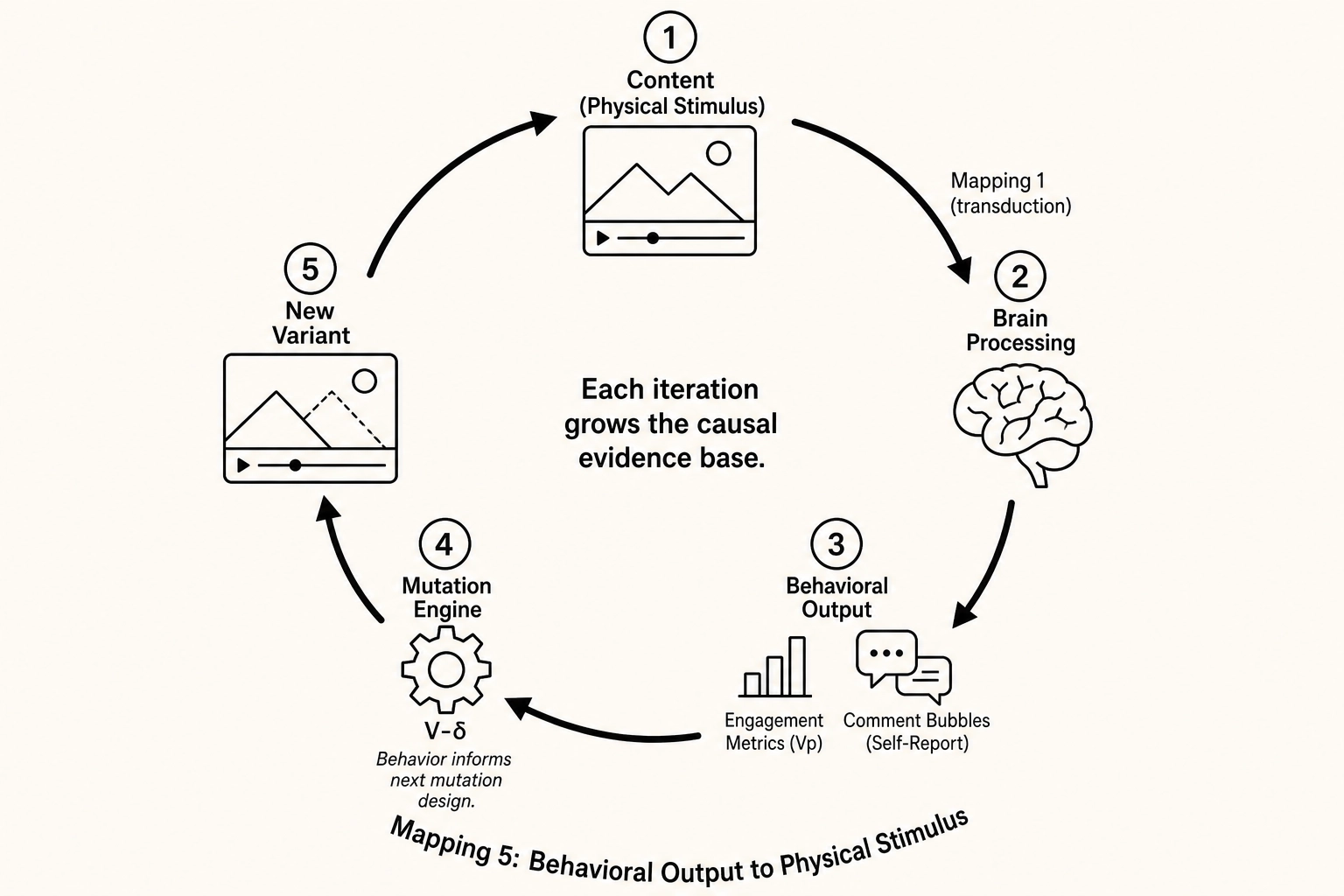
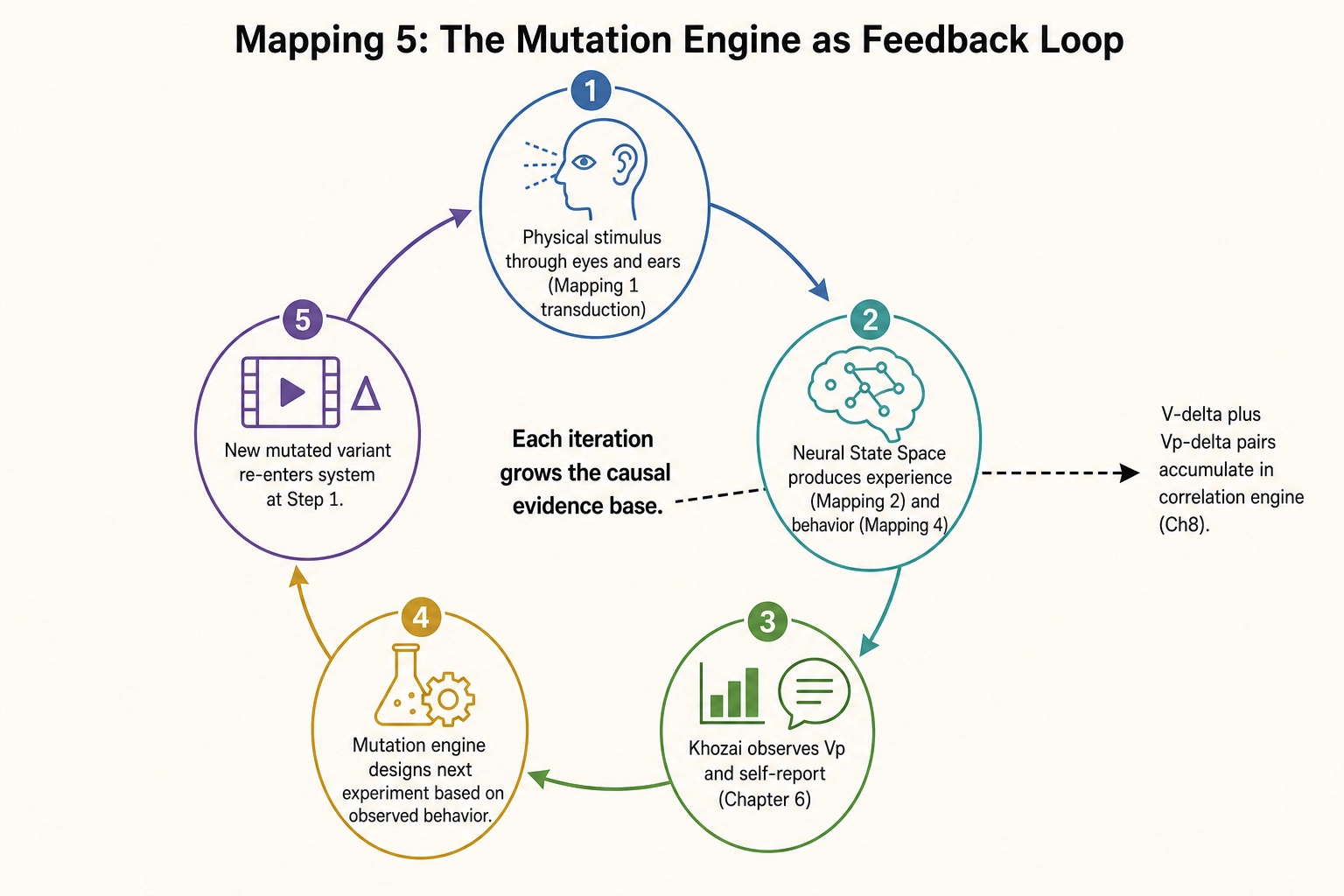
The mutation engine is one closed instance of the second feedback loop. The chain works like this:
- A piece of content - a physical stimulus - enters the viewer’s brain through the eyes and ears (Mapping 1, transduction).
- The brain processes the stimulus (Neural State Space), producing experience (Mapping 2, production) and behavioral output (Mapping 4, response).
- Khozai observes the behavioral output through Vp and self-report (Chapter 6).
- The mutation engine uses the observed behavior to design the next experiment - choosing which property to mutate, which direction to push it, what magnitude to try. The behavior feeds back into the design of the next stimulus.
- The new stimulus (the mutated variant) re-enters the system at step 1.
This is not a metaphor. It is the literal operation of the Behavioral Output to Physical Stimulus loop that Mapping 5 describes. A viewer’s retention curve (behavioral output) influences which property the next mutation targets (a new physical stimulus). The new physical stimulus produces new behavioral output. The loop continues.
The mutation engine makes this loop explicit and measurable. Each iteration produces a verified V-delta on the stimulus side and a measured Vp difference on the behavioral side. The correlation engine (Chapter 8) accumulates these paired measurements across iterations, building a causal graph of which properties drive which outcomes. Each experiment makes the next experiment more informed - not because the engine guesses better, but because the empirical evidence base grows with every iteration.
Chapter 3’s “always-on” property of the brain-as-a-country analogy describes this loop at the biological level: the country’s actions reshape its environment, producing new imports. The mutation engine is the Khozai-specific instantiation: the framework’s actions (generating controlled variants) reshape the stimulus environment (the content library), producing new data (Vp outcomes) that feed back into the next cycle of experiment design.
7. What Makes This Different
Several tools and approaches exist for controlled content experimentation. Understanding what they do - and where they stop - is essential to understanding what the mutation engine adds. The descriptions below are organized by what is tested and how, not by vendor. All claims are dated to April 2026.
Modular asset swapping
Marpipe is the closest commercial tool to controlled content experimentation in the ad-creative space. It performs multivariate testing by swapping modular assets - image A versus image B, headline X versus headline Y - rendering every combination, and running each in its own ad set with equal budget. This is real multivariate testing with real randomization and real statistical readout. What Marpipe tests is which component performs best in combination with other components.
Where Marpipe stops: it swaps whole components, not signal-level properties. You can test image A versus image B, but you cannot test “the same image with luminance increased by 15%” or “the same clip with face area scaled from 30% to 50%.” The properties that differ between image A and image B are uncontrolled: they differ on color, composition, face size, background, text placement, and dozens of other V-vector channels simultaneously. Marpipe’s test tells you which combination won; it cannot tell you which property of the winning image drove the win.
Language-element testing
Persado and Phrasee (now Jacquard) perform true single-variable testing on language elements: narrative framing, emotional tone, call-to-action phrasing. They generate variant text, test it against control text, and report which variant performed best with confidence intervals. This is genuine controlled experimentation on a specific modality.
Where they stop: they have no video capability. The modality is text - email subject lines, ad copy, push notifications, SMS. Video properties - visual composition, audio, pacing, face presence, motion energy - are outside their scope.
Platform-native A/B testing
Meta Ads Manager, YouTube video experiments, and TikTok’s split-testing product all provide server-side randomization with equal budget allocation across arms. The randomization is trustworthy: the platform controls impression assignment. This is the best available randomization infrastructure for content testing at scale.
Where they stop: the platform provides the randomization but not the variants. The advertiser or creator must author each variant manually. Two manually authored variants differ on an unknown and uncontrolled number of properties. The platform tells you which variant won; it does not tell you which property of the variant caused the win, because it did not control which properties differed.
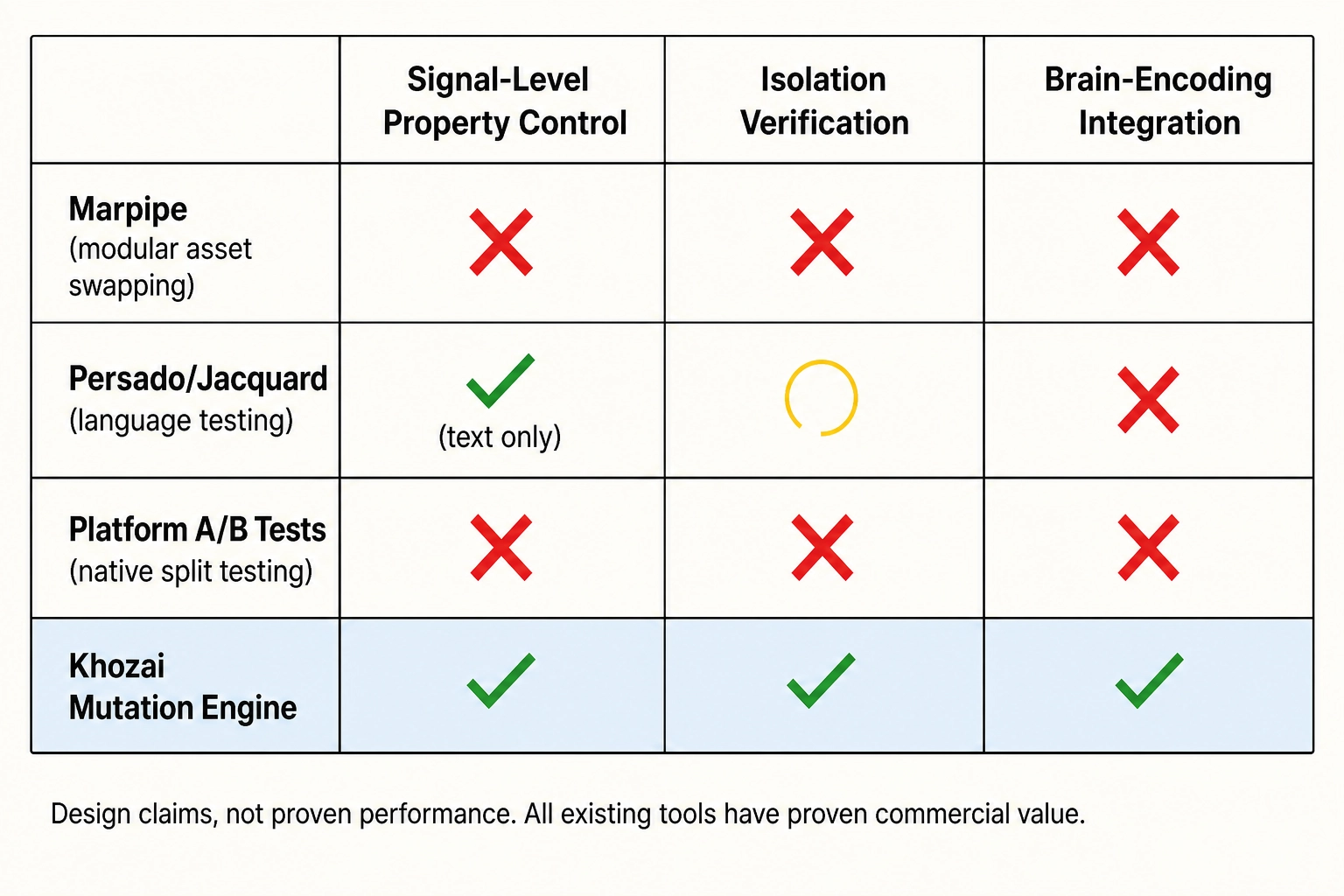
Where Khozai’s mutation engine sits
The mutation engine combines three capabilities that the existing tools provide separately but no single tool integrates as of April 2026:
Signal-level property control. The operator vocabulary targets physical and cognitive properties at the level of V-vector channels: luminance gain by a specific factor, face area at a specific fraction of frame, cut rate at a specific frequency, audio spectral shape by specific EQ parameters. This is the level at which the creative intelligence platforms (Chapter 1 Section 3.1) tag content but do not test, and the level at which the signal-level engineering libraries (Chapter 1 Section 3.3) extract measurements but do not connect to behavioral outcomes.
Isolation verification. The four-layer verification pipeline confirms that the targeted property changed as intended and that isolation properties stayed within declared bounds, from the AST schema through the physics, through the cognitive recognition, through the predicted cortical activation. No published or commercially available tool performs this layered verification as of April 2026.
Brain-encoding-model integration. The cortical verification layer re-runs TRIBE v2 on the mutated output and checks the predicted cortical-activation shift against the operator’s declared propagation footprint. This connects every mutation to the neuroscience layer: a face-area mutation is not just “pixels changed” but “fusiform face area activation shifted by a measurable amount.” As of April 2026, no published or commercially available system connects video mutations to predicted cortical activation patterns.
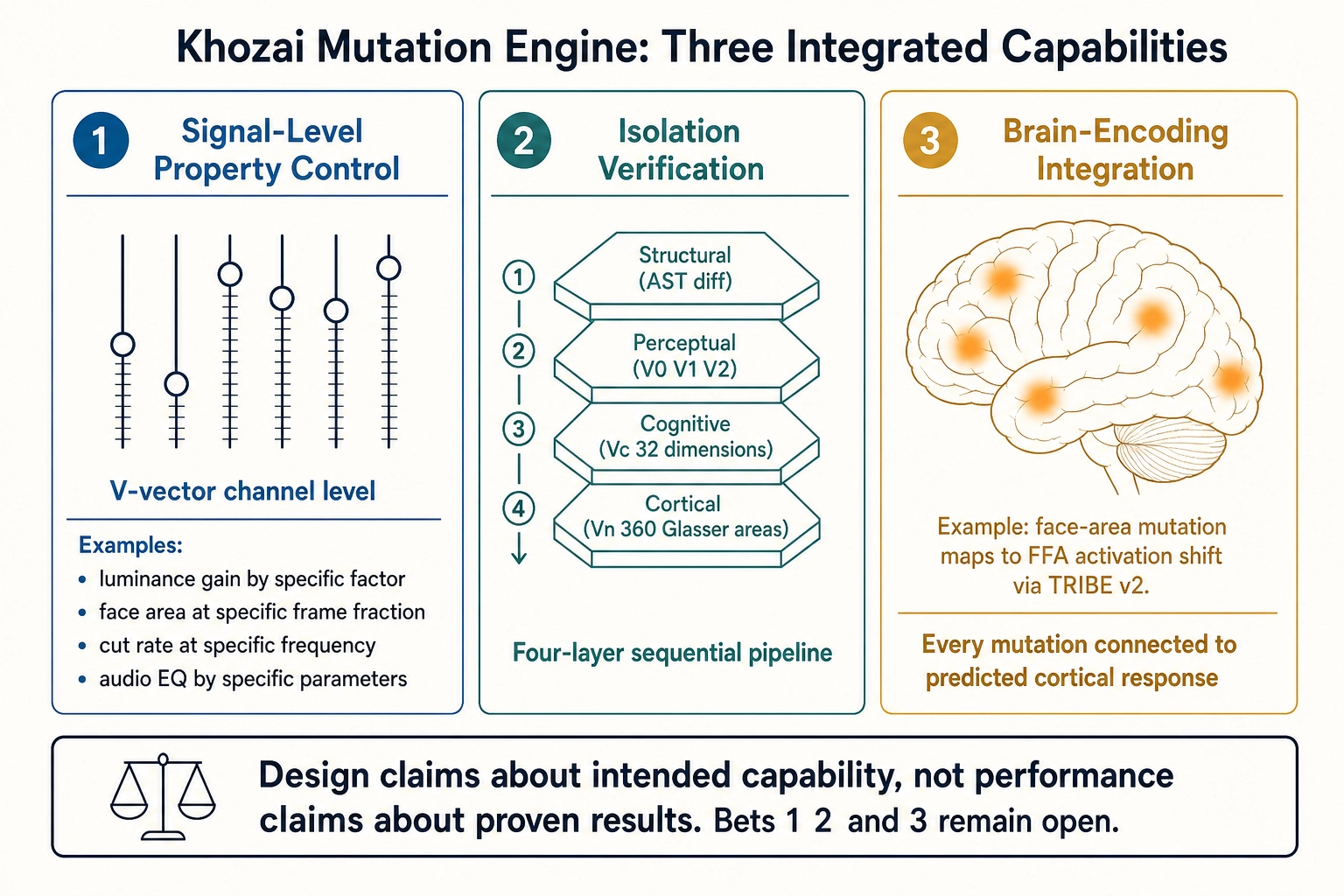
These are design claims about what the mutation engine intends to do, not performance claims about proven results. The engine has not been tested at scale. Whether signal-level property control adds value beyond Marpipe’s component-level testing is Bet 1: the empirical question of whether physics-level properties carry additional predictive signal beyond semantic-level properties. Whether brain-encoding integration adds value is Bet 2: the empirical question of whether predicted cortical activation carries enough signal to predict performance. Both bets remain open. The tools described above - Marpipe, Persado, Phrasee, platform-native testing - are real products with real users and proven commercial value. Khozai’s approach is untested. What the mutation engine provides is the infrastructure for testing the bets, not evidence that the bets are right.
The mutation engine turns the framework from a measurement system into an experimental system. Chapters 5 and 6 gave Khozai the ability to describe content and observe behavior. The mutation engine gives Khozai the ability to intervene: to change one thing, measure the effect, and learn. Chapter 8 describes the correlation engine that accumulates those lessons into a growing causal graph. Chapter 9 walks the full inference chain end-to-end.
What this does NOT say
The mutation engine does not claim that its edits are imperceptible. Every mutation changes the rendered video in ways that a viewer may notice; the engine’s job is to ensure that the change is controlled and measured, not invisible. The engine does not claim that single-variable control is perfect in practice. Propagation across V-vector layers means that a targeted change at one layer always produces secondary shifts at other layers; the verification pipeline catches and records these, but it does not eliminate them. The engine does not claim that transfer from controlled experiments to real-world creative decisions (Bet 3b) is proven. Transfer is an empirical question that the framework is designed to test, not an assumption it builds on.
Khozai implication
The mutation engine is Khozai’s mechanism for testing Bet 3: that controlled, single-variable experiments on content properties can produce transferable causal knowledge about what drives engagement. Without the mutation engine, Khozai can describe content (Chapters 4-5) and observe behavior (Chapter 6), but it cannot intervene. The mutation engine closes the loop from observation to experiment, making it possible to ask “does changing this property cause a change in that outcome?” rather than “are this property and that outcome correlated in the archive?” The answer to the causal question is what Bet 3 wagers on, and the mutation engine is the infrastructure that makes the wager testable.
Conclusion
This chapter specified how Khozai moves from passive measurement to active experimentation. The mutation engine takes a piece of content with known V-vectors, applies a typed operator from a locked fourteen-operator vocabulary, verifies isolation at four layers (structural, perceptual, cognitive, cortical), and publishes the result under controlled experimental conditions. The V-delta profile records exactly what changed and by how much, giving the downstream correlation engine a clean input for causal inference. No existing tool combines signal-level property control, multi-layer isolation verification, and brain-encoding integration on video content.
The mutation engine is what makes Khozai an experimental system rather than an analytics platform. Without it, the framework’s vectors are descriptive: they characterize content (V₀, Vc), predict cortical response (Vₙ), and record behavioral outcomes (Vₚ). With it, the framework runs controlled experiments at scale. Each mutation is a perturbation of Physical Stimulus Space; each publication is a field experiment with sample sizes that dwarf typical laboratory studies; each V-delta/Vₚ-delta pair is a data point in a growing causal graph. Chapter 1 framed content platforms as “organic laboratories” where every publication is an experiment and every viewer response is a data point. The mutation engine is the instrument that converts that framing from metaphor into method - it provides the controlled perturbation that distinguishes experimentation from observation. When Chapter 8’s correlation engine and Chapter 10’s calibration governance are added, the result is a closed experimental loop: mutate, measure, correlate, calibrate, and feed the calibration back into the next mutation’s design. This is the full vertical integration Chapter 1 described.
Chapter 8 describes the correlation engine that accumulates the mutation engine’s paired measurements - V-delta on the content side, Vp-delta on the behavioral side - into a growing causal graph.
Bibliography
[1] Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Lawrence Erlbaum Associates, 1988. [TEXTBOOK] Used in: Section 5, sample-size calculation (two-proportion z-test formula, locked defaults for alpha, power, MDE).
[2] Kish, L. Survey Sampling. John Wiley & Sons, 1965. [TEXTBOOK] Used in: Section 5, design-effect inflation factor DEFF = 1.5 for clustered observations.
[3] Revideo. Open-source programmatic video editing framework. GitHub: https://github.com/redotvideo/revideo. MIT License. [SOFTWARE] Used in: Section 4, scene-AST renderer description.
[4] Gordon, B. R., Moakler, R., & Zettelmeyer, F. A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook. Marketing Science, 38(2), 193-225, 2019. [JOURNAL] Used in: Section 5, Meta’s divergent-delivery problem (algorithmic re-allocation of impressions across A/B arms).
[5] Meta Business Help Center. About Reach and Frequency Buying. Meta for Business, 2025. [DOCUMENTATION] Used in: Section 5, Meta divergent-delivery mitigations (reach-and-frequency campaign type).
[6] Lazar, A. et al. An open-access database of video stimuli for action observation research in neuroimaging settings. Frontiers in Psychology, 15, 1407458, 2024. [JOURNAL] Used in: Section 1, closest academic precedent for stimulus-controlled video databases.
[7] Nishimoto, S. et al. Reconstructing Visual Experiences from Brain Activity Evoked by Natural Movies. Current Biology, 21(19): 1641-1646, 2011. [JOURNAL] Used in: Section 1, encoding-model work on natural movies as prior art.
[8] Kohavi, R., Tang, D., and Xu, Y. Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press, 2020. [BOOK] Used in: Section 5, 2-5% MDE as standard range for online experiments.
[9] Larsen, N. et al. Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology. The American Statistician, 78(2): 135-149, 2024. [JOURNAL] Used in: Section 5, 2-5% MDE as standard range for online experiments.
[10] Yue, X., Vessel, E. A., and Biederman, I. Lower-level stimulus features strongly influence responses in the fusiform face area. Cerebral Cortex, 21(1): 35-47, 2011. [JOURNAL] Used in: Section 3, parametric FFA response to face size.
[11] Holtz, D., Lobel, F., Liskovich, I., and Aral, S. Reducing Interference Bias in Online Marketplace Experiments Using Cluster Randomization. Management Science, 71(1): 390-406, 2025. [JOURNAL] Used in: Section 5, interference bias (19.76%) supporting DEFF > 1 in platform experiments.
[12] Saveski, M. et al. Detecting Network Effects: Randomizing Over Randomized Experiments. KDD 2017, 2017. [CONFERENCE] Used in: Section 5, detecting network effects in randomized experiments.
[13] Braun, M. and Schwartz, E. M. Where A/B Testing Goes Wrong: How Divergent Delivery Affects What Online Experiments Cannot (and Can) Tell You. Journal of Marketing, 89(1): 71-95, 2025. [JOURNAL] Used in: Section 5, Meta divergent-delivery problem confirmed as structural and persistent post-2019.