Introduction
This chapter collects the framework’s structural limitations, locks the three central bets in their final wording, specifies what would falsify the project, and frames the open questions that remain.
How the chapter is organized. Section 1 enumerates the five structural limitations of Khozai v1. Section 2 restates the three central bets in their locked wording. Section 3 separates risks from bets. Section 4 specifies what would falsify the framework. Section 5 addresses ethical limitations. Section 6 frames what comes next. Section 7 applies Tool 13 (Consistency) as a cross-chapter verification.
1. What the Framework Cannot Do
The previous ten chapters built a framework piece by piece: premises, spaces, vectors, mutation engine, correlation engine, inference chain, calibration governance. Each chapter stated what Khozai can do and what it cannot. This chapter collects the cannot-do side in one place, locks the project’s three central bets in their final wording, separates risks from bets, specifies what would falsify the framework, and frames what comes next. Everything in this chapter is a constraint the framework carries into Chapters 12 and 13, which build on it.
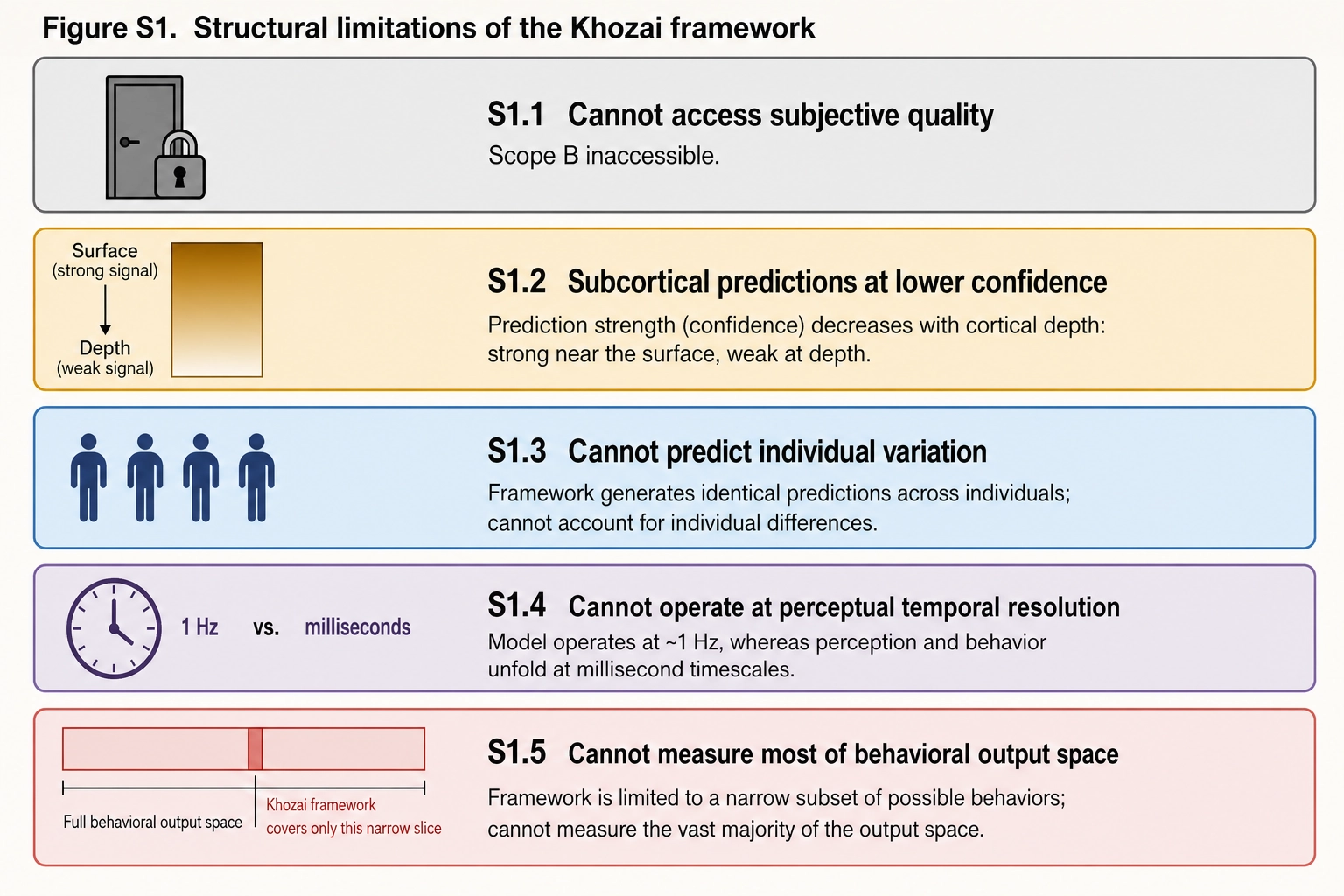
Five structural limitations define the boundary of what Khozai v1 can reach. None of them is a surprise: each has been stated in the chapter where it first matters. Collecting them here is an application of Tool 13 (Consistency): the can-do claims from Chapters 5 through 10 must reconcile with this cannot-do list, and any tension between them must be resolved explicitly rather than left for the reader to notice.
| # | Limitation | Core constraint | Affected layers | Source chapter |
|---|---|---|---|---|
| S1.1 | Cannot access subjective quality | Scope B of Experience Space is inaccessible; framework operates on Scope A only | All inference | Ch 2 |
| S1.2 | Predicts subcortical activation at lower confidence | fMRI SNR is weaker for subcortical structures; reward, arousal, threat predictions carry lower confidence | Vₙ | Ch 3 |
| S1.3 | Cannot predict individual variation | TRIBE v2 outputs population-average predictions, not person-specific ones | Vₙ | Ch 3 |
| S1.4 | Cannot operate at perceptual temporal resolution | 1 Hz Vₙ output is three orders of magnitude coarser than the brain’s fastest processing | Vₙ | Ch 5 |
| S1.5 | Cannot measure most of Behavioral Output Space | Vₚ captures voluntary digital motor actions only; autonomic, endocrine, immune, and offline responses are invisible | Vₚ | Ch 2, Ch 6 |
1.1. Cannot Access Subjective Quality
Khozai can infer which aspects of the viewer’s perception and emotion are involved, how strongly, and how independently from each other. It cannot infer what any of it feels like. Chapter 2 formalized this as the distinction between Scope A of Experience Space - the structural axes, their independence, their hierarchy - and Scope B - the qualitative character of experience, what red looks like, what nostalgia feels like from the inside. Scope A is accessible through Structural Inference (Mapping 3): from the architecture of Neural State Space, Khozai derives which experiential dimensions exist and how they relate. Scope B is not accessible through any method the framework employs. The Production mapping (Mapping 2) - from neural state to experience - is observed, specific, and graded (Premise 5), but its mechanism is unknown. This is the hard problem of consciousness, and the framework does not solve it, address it, or route around it. It acknowledges it and works within the territory that remains.
What this means in practice: Khozai can report that a content file predicts strong fusiform face area activation and infer that social processing is strongly engaged. It cannot report what the viewer felt about the face - whether it triggered warmth, recognition, discomfort, or indifference. It can report that the default mode network - the regions active when a person is relating what they see to their own life, imagining what might happen next, or reflecting inward - is predicted to activate, and infer that self-referential processing is engaged. It cannot report what the viewer was actually thinking about. The which-and-how-strongly is accessible. The what-it-feels-like is not.
This is not a limitation that better engineering can fix. It is a boundary condition on any framework that works from the outside - from physical measurement, predicted neural activation, and behavioral observation - rather than from inside the viewer’s subjective experience. Self-report (Chapter 6) provides partial, noisy, language-filtered access to Scope B, and the framework uses it wherever it can. But self-report is sparse, voluntary, biased, and limited by introspective access. The boundary is real.
1.2. Predicts Subcortical Activation at Lower Confidence
TRIBE v2 itself emits whole-brain predictions - approximately 20,484 cortical surface vertices on the fsaverage5 mesh plus approximately 8,802 subcortical voxels. Khozai consumes both. Cortical predictions enter at higher initial confidence (stronger fMRI SNR, better encoding-model reconstruction quality in published benchmarks). Subcortical predictions enter at lower initial confidence (weaker fMRI SNR, less validated reconstruction - Keuken et al., 2018, review the signal-quality challenges of imaging subcortical structures even at ultra-high field strengths) but are included because the structures they represent are among the most relevant for content engagement.
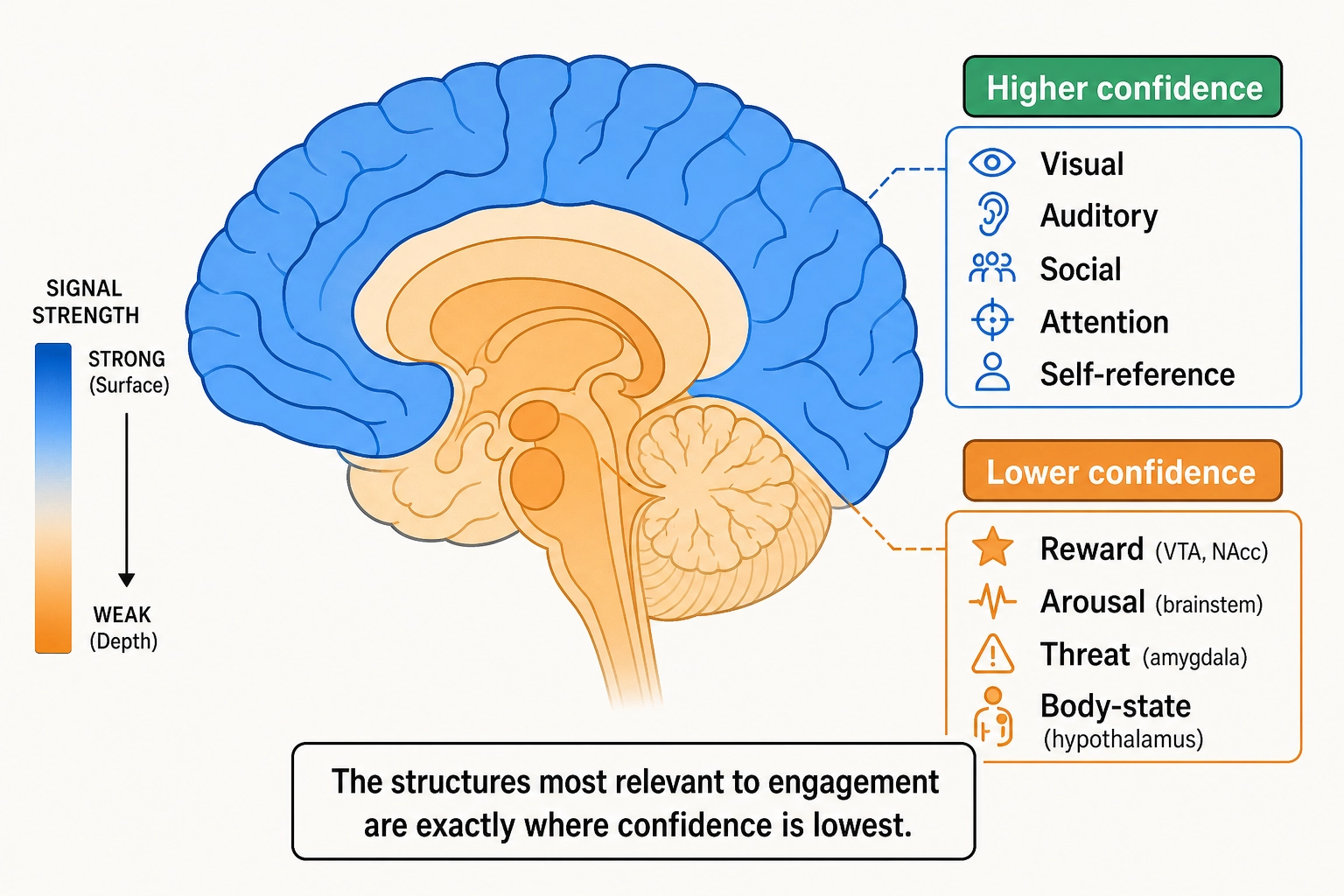
The practical consequence is that several categories of neural processing are predicted with lower confidence than cortical predictions:
- Reward processing - the ventral tegmental area (VTA), nucleus accumbens, and dopamine pathways that drive wanting and incentive salience. Khozai predicts these at lower confidence due to fMRI SNR limitations. The prediction is included because reward processing is among the most relevant signals for content engagement.
- Arousal regulation - the brainstem reticular activating system (RAS - the ascending network that sets the brain’s global activation level), locus coeruleus (the brain’s primary source of noradrenaline, the neurotransmitter that modulates alertness and attention), and raphe nuclei (the brain’s primary source of serotonin, the neurotransmitter involved in mood and wakefulness regulation). Predicted at lower confidence. Included because arousal regulation is among the most relevant signals for content engagement.
- Body-state monitoring - the hypothalamus and periaqueductal gray (the midbrain region involved in pain modulation and defensive behavior), which monitor temperature, hunger, thirst, and pain regulation. Predicted at lower confidence. Included because body-state is among the most relevant signals for content engagement.
- Threat detection - the amygdala, which processes threat-relevant stimuli. Predicted at lower confidence. Included because threat/salience detection is among the most relevant signals for content engagement.
The confidence differential is consequential. Reward processing is central to content engagement: the marketing neuroscientist Vinod Venkatraman and colleagues (Journal of Marketing Research, 2015) found that ventral striatum activity during ad viewing outperformed all other neurophysiological measures in predicting real-world market success. The neuroscientist Frederic Tong and colleagues (Knutson lab, Stanford, PNAS 2020) found that nucleus accumbens and medial prefrontal cortex activity during video viewing predicted aggregate YouTube engagement. The subcortical component of those findings - nucleus accumbens, ventral striatum - is exactly the territory where Khozai’s predictions carry lower confidence. Whether the lower-confidence subcortical predictions preserve enough of that signal is an empirical question the calibration governance framework (Chapter 10) tracks.
The cortical regions Khozai predicts at higher confidence include cortical components of reward, arousal, and threat circuits: the medial prefrontal cortex, the anterior insula (the cortical site of interoceptive awareness, per the neuroanatomist A.D. Craig 2002), and the anterior cingulate cortex. These cortical regions participate in the same functional circuits as their subcortical partners. The combination of higher-confidence cortical predictions and lower-confidence subcortical predictions provides broader coverage than cortical predictions alone. The confidence gap is an empirical starting point, not a permanent verdict: future encoding models with better subcortical reconstruction may narrow the gap.
A cross-chapter pattern deserves explicit statement: the framework’s blind spots are systematic, not random, and they cover the dimensions most associated with content engagement and retention. Reward processing (Drive, Hedonic), arousal regulation, and threat detection (Fear) are exactly the neural systems that published neuromarketing studies identify as the strongest predictors of real-world content performance - and they are exactly the systems that sit at lower confidence in Khozai’s architecture. This is not a coincidence: the subcortical structures that evolution optimized for fast, high-stakes survival responses are the same structures that drive repeated content consumption, and they are the same structures that sit deepest in the brain where fMRI signal quality is weakest. The framework’s strongest predictions are about what content engages (cognitive, social, visual - all cortical) rather than how much the viewer wants more of it (reward, arousal - subcortical). The compensation mechanisms - cortical correlates of subcortical circuits, Vₚ behavioral signals, self-report extraction - are designed precisely for this asymmetry.
1.3. Cannot Predict Individual Variation
TRIBE v2 predicts the activation pattern an average viewer would produce. It does not predict variation across individual viewers, demographic strata, or psychological states. The model was trained on fMRI data from approximately 25 subjects (Meta AI Blog, 2025); its output is a population-average prediction, not a person-specific one. Twenty-five subjects is actually on the large end for encoding models: most published encoding models use 3-8 subjects, and scaling laws for language encoding models in fMRI suggest that performance improves log-linearly with subject count (the computational neuroscientists Richard Antonello, Aditya Vaidya, and Alexander Huth, 2023).
This means Khozai’s neural-level predictions are the same for every viewer who watches a given content file. A teenager and a sixty-year-old, a first-time viewer and someone watching for the fifth time, a person in a good mood and a person grieving: all receive the same Vₙ prediction. The framework compensates on the behavioral side: persona-based segmentation of Vₚ (platform metrics) and self-report data captures population-level variation in how different groups respond to the same content. But the neural prediction layer does not differentiate. When Chapter 8 reports that a mutation produced a retention shift of +12% for one persona and -3% for another, the Vₙ prediction is the same for both groups. The behavioral difference comes from the Vₚ side, not the Vₙ side.
This is inherent to fMRI-based brain encoding models as a class. Individual-specific brain encoding models exist in the research literature - the neuroscientist Emily Allen and colleagues (2022) collected a massive 7T fMRI dataset from individual subjects that enables person-specific encoding - but they require individual-specific fMRI training data, exactly the scanner-and-subject dependency the framework uses TRIBE v2 to avoid. The average-subject limitation is the price of scalability.
1.4. Cannot Operate at Perceptual Temporal Resolution
The brain processes visual input at millisecond resolution. A viewer detects a scene change in roughly 100 milliseconds (the neuroscientists Simon Thorpe, Denis Fize, and Catherine Marlot, 1996; the vision researcher Sébastien Crouzet and colleagues, 2010). Threat-relevant stimuli reach the amygdala in approximately 100 milliseconds via a fast subcortical pathway (the neuroscientist Joseph LeDoux, 1996), though the simple “low road” model has been challenged: the neuroscientists Luiz Pessoa and Ralph Adolphs (2010) argue that in humans, evaluating biological significance involves multiple parallel pathways rather than a single subcortical route. Saccadic eye movements take 20-200 milliseconds. TRIBE v2’s native output rate is 1 Hz - one prediction per second, decimated from a 2 Hz model frequency, with a 5-second past offset compensating for the hemodynamic lag of the BOLD fMRI signal. The fMRI hemodynamic response resolves at roughly 1-2 seconds; sub-second activation cannot be recovered from BOLD-based models.
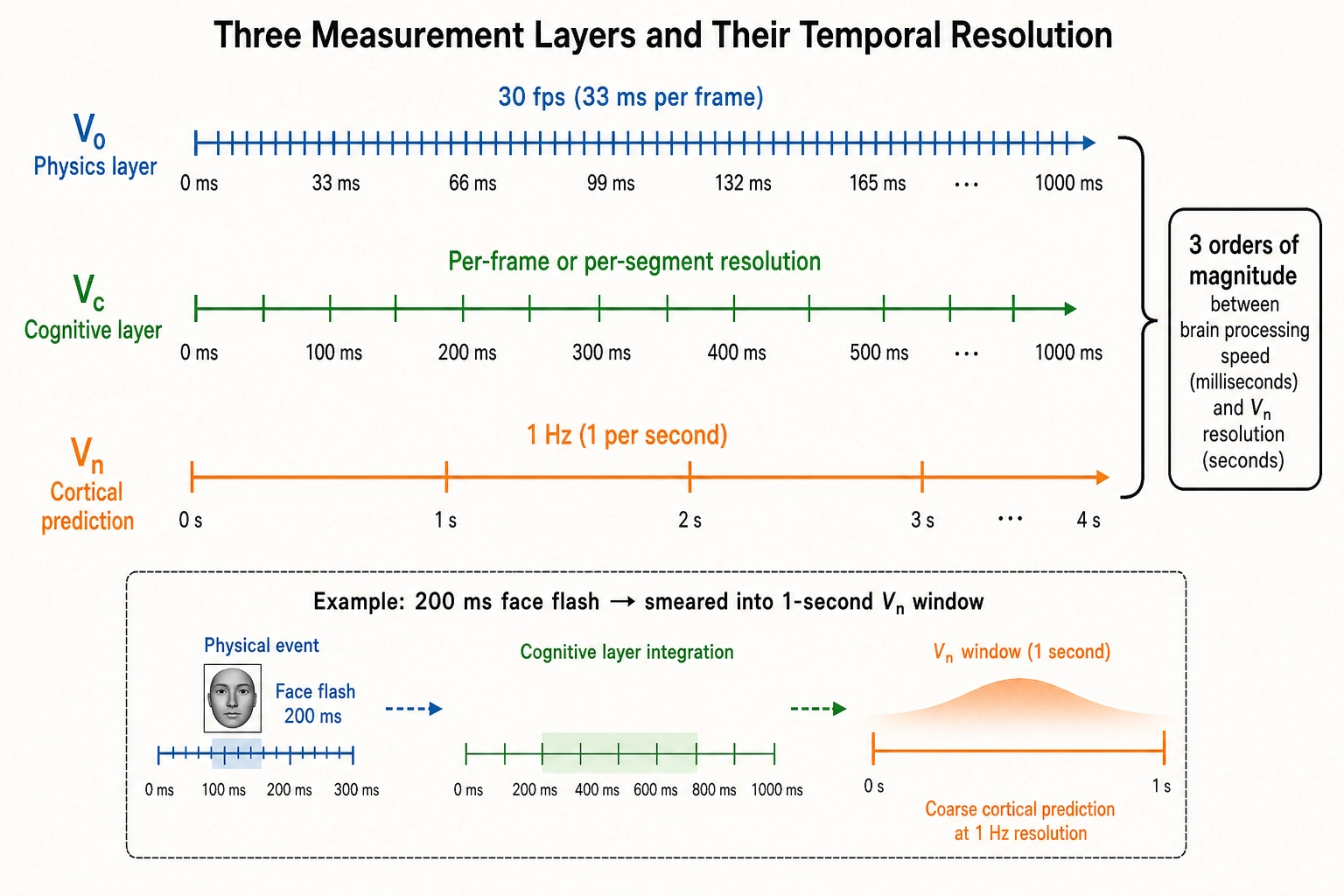
This means Khozai operates at a temporal resolution roughly three orders of magnitude coarser than the brain’s fastest processing. A 30-second video produces 30 Vₙ frames. Each frame is a 1-second average of cortical activation, smoothing over everything that happened within that second. If a face appears for 200 milliseconds and produces a burst of fusiform face area activation, the 1 Hz output smears that burst into a one-second window that also includes whatever preceded and followed it. Rapid temporal dynamics - the precise moment a viewer’s attention shifts, the sub-second sequence of cortical activation that distinguishes surprise from expectation - are below the resolution floor.
The V₀ layer does not share this limitation. V₀ operates at frame rate (typically 30 frames per second for video, or about 33 milliseconds per frame) and at audio sample rate (48 kHz, about 21 microseconds per sample). Vc operates at whatever temporal granularity the vision-language model supports - currently per-frame or per-segment. The temporal bottleneck is specific to Vₙ, the cortical prediction layer, and it is a property of the fMRI-based encoding approach, not a Khozai design choice.
1.5. Cannot Measure Most of Behavioral Output Space
Chapter 2 defined Behavioral Output Space as having four major output systems: motor (skeletal muscle contractions, including eye movements, facial expression, and speech), autonomic (heart rate, breathing, pupil dilation, skin conductance), endocrine (cortisol, adrenaline, oxytocin), and immune (cytokines, immune cell mobilization). Khozai’s Vₚ vector - the 22 platform metrics captured after content is published - measures a narrow slice of motor output only: the viewer’s clicks, scrolls, watch duration, likes, shares, saves, comments, and follows. These are voluntary digital actions, a subset of a subset.
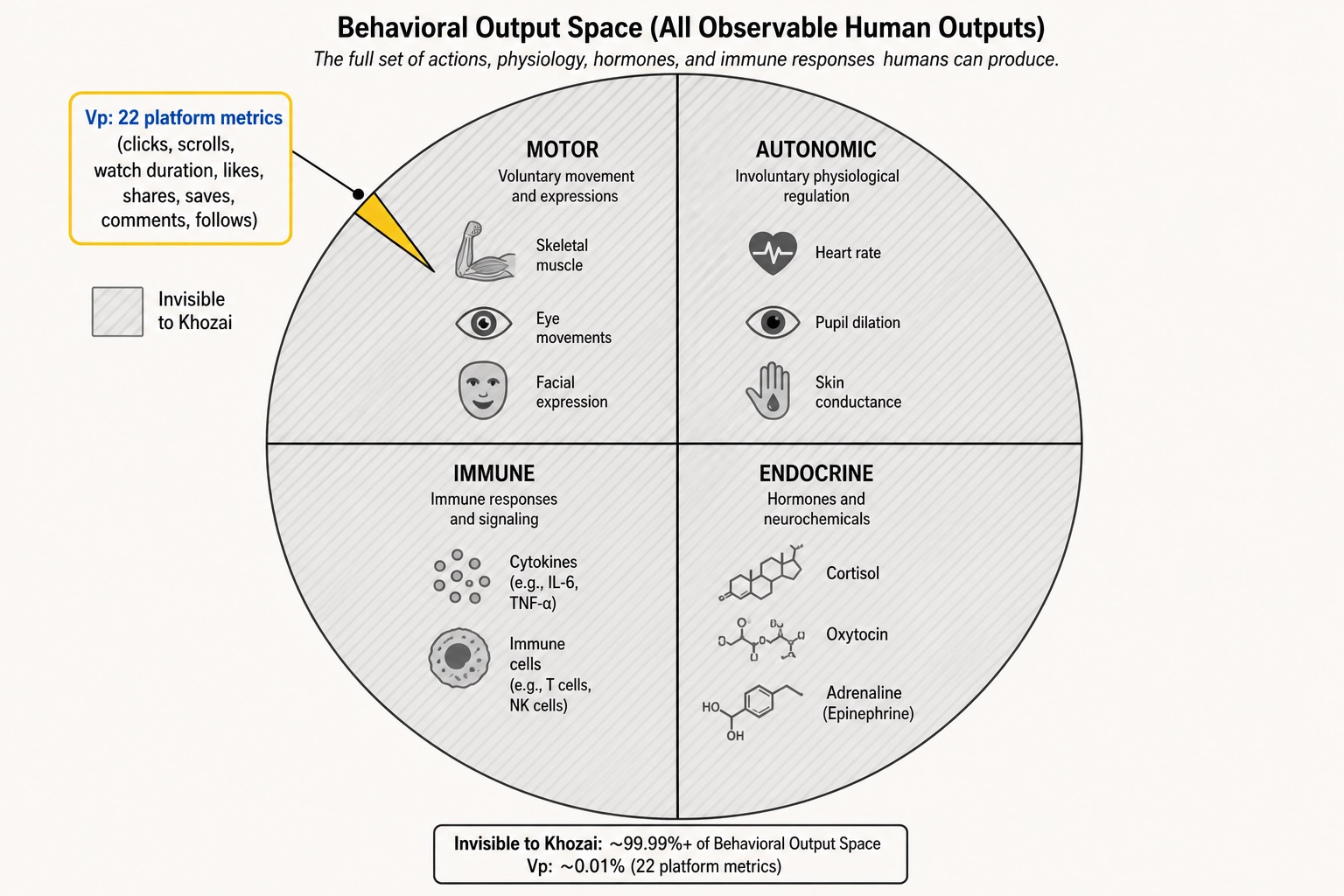
Everything else in Behavioral Output Space is invisible to Khozai:
- Autonomic responses - whether the viewer’s heart rate increased, whether their pupils dilated, whether their skin conductance spiked. All measurable with biometric equipment; none captured by platform metrics.
- Endocrine responses - whether the content triggered cortisol release, oxytocin release, or any hormonal change. Measurable with blood or saliva assays; not captured by platform metrics.
- Immune responses - whether acute emotional content triggered immune cell mobilization. Measurable in laboratory settings; not captured by platform metrics.
- Offline behavioral consequences - whether the viewer purchased a product after seeing an ad, tried a recipe after watching a cooking video, changed an opinion after watching a documentary, discussed the content with a friend. Some of these are partially captured by platform conversion tracking; most are not.
This is not a limitation unique to Khozai. Every creative intelligence platform, every neuromarketing tool, every ad analytics system operates within the same measurement horizon: the digital behavioral traces the viewer leaves on the platform. Khozai’s contribution is not expanding this measurement horizon; it is deepening the analysis of the content that precedes the behavioral response. The behavioral measurement itself remains limited to what platforms expose.
2. The Three Bets Restated
Khozai rests on three central bets. These are not hopes or assumptions: they are testable hypotheses with clear success and failure criteria. The entire project is designed to answer them. The wording below is locked from Chapter 1 section 9, reproduced verbatim. No paraphrase, no drift.
Bet 1
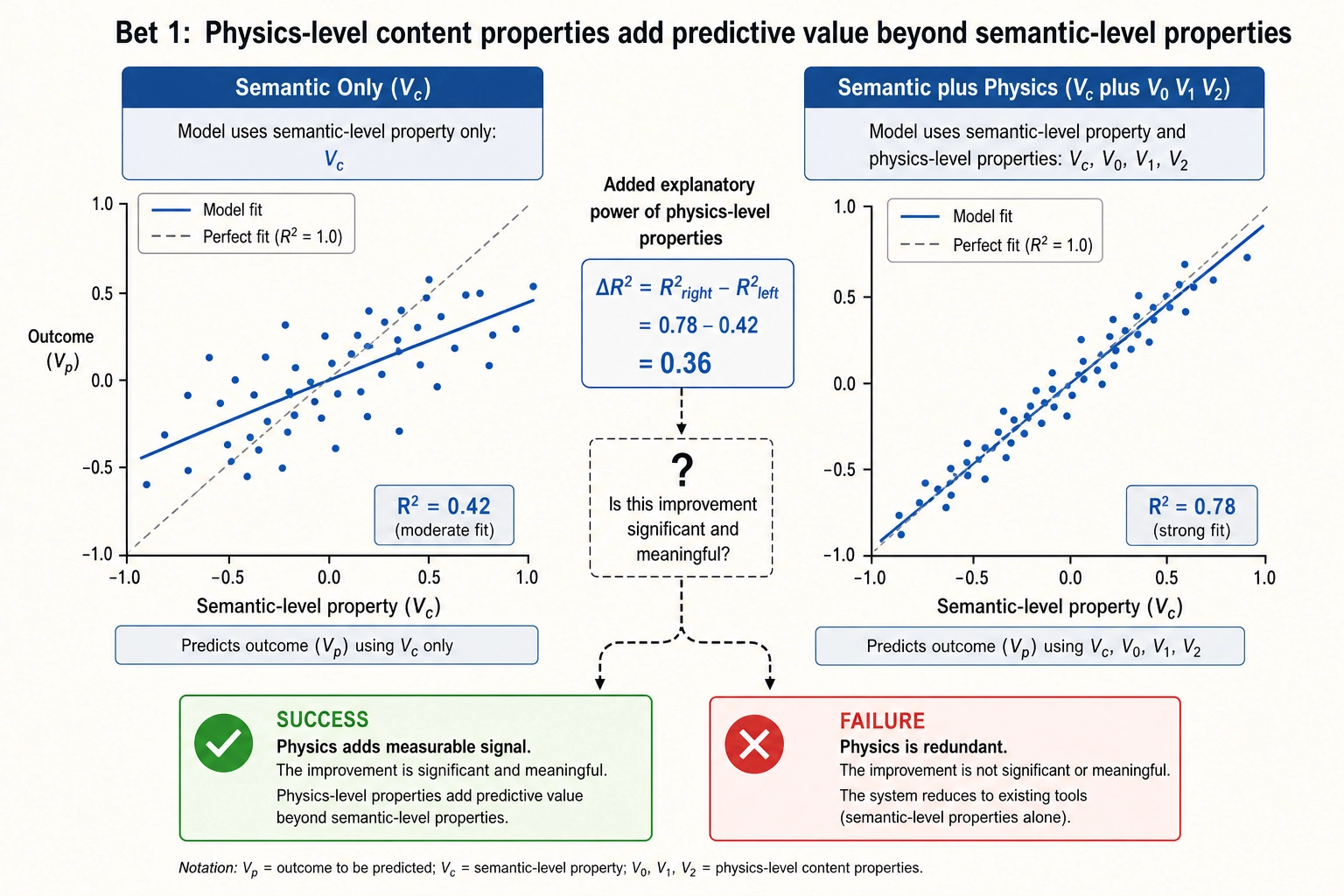
Bet 1: Physics-level content properties add predictive value beyond semantic-level properties.
All 50+ creative intelligence companies work at the semantic level - hooks, CTAs, colors, faces, visual styles. They have built businesses on it. The bet is that going deeper - to spectral power distributions, spatial frequency energy, luminance statistics, audio spectral features, motion energy distributions, temporal acceleration patterns - captures additional signal that semantic tagging misses. If this bet is wrong, Khozai’s physics-level decomposition adds noise rather than value, and the semantic-level tools already capture what matters. Khozai’s experiments will answer this.
Success criteria for Bet 1. In controlled experiments, adding V₀/V₁/V₂ features to a regression model that already includes Vc features produces a statistically significant improvement in predicting Vₚ outcomes. The improvement must be robust across multiple content categories and persona segments - not an artifact of a single domain or a single audience. The effect size must be practically meaningful: a measurable improvement in prediction accuracy that translates to actionable differences in content decisions, not merely a p-value below a threshold.
Failure criteria for Bet 1. In controlled experiments, V₀/V₁/V₂ features add no statistically significant predictive value once Vc features are already in the model. Semantic-level analysis captures 100% of the actionable signal; physics-level decomposition is redundant. If this is the result, Khozai’s physics layers (V₀, V₁, V₂) are an unnecessary complication, and the framework reduces to a Vc-Vₙ-Vₚ system: cognitive approximation, cortical prediction, and behavioral measurement, without the physics substrate.
Bet 1 is an empirical question. The answer comes from testing, not from argument.
Bet 2
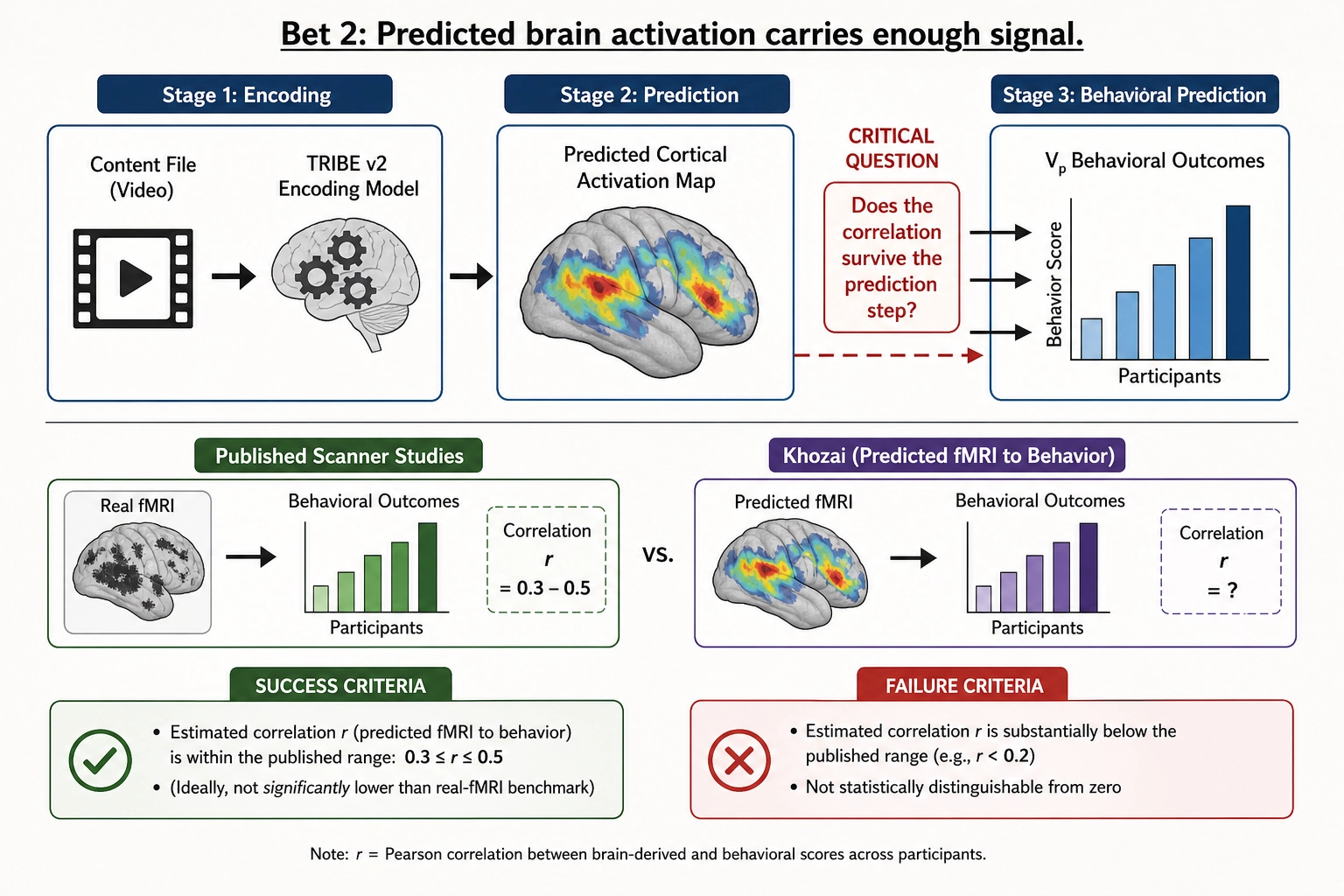
Bet 2: Predicted brain activation from an encoding model carries enough signal to predict content performance.
The academic studies cited in Chapter 1 section 4.2 proved that real brain activation - measured with fMRI scanners - predicts content performance better than self-report. TRIBE v2 can predict brain activation from the content file alone, with no scanner and no subjects. The bet is that the prediction is accurate enough that the brain-to-performance correlation survives the prediction step. If this bet is wrong, the prediction is too noisy and the signal washes out. Khozai’s experiments will answer this.
Success criteria for Bet 2. Vₙ-derived features (predicted cortical activation patterns) show statistically significant correlations with Vₚ outcomes (platform performance metrics), and those correlations are consistent with the published literature on real-fMRI-to-performance relationships: the same cortical regions that predicted performance in scanner studies (Venkatraman et al. 2015; the social neuroscientist Emily Falk and colleagues 2012; Tong et al. 2020; the neuroscientist Christin Scholz and colleagues 2025) also predict performance when their activation is estimated rather than measured. The correlation coefficients need not match the scanner-study magnitudes - prediction introduces noise - but the direction and regional specificity must survive.
Failure criteria for Bet 2. Vₙ-derived features show zero or negligible correlation with Vₚ outcomes across content categories and persona segments. The predicted cortical activation pattern carries too little signal to be useful: the encoding model’s prediction noise drowns out the brain-to-performance relationship that the scanner studies found. If this is the result, the bridge described in Chapter 1 section 4.2 - using predicted brain activation instead of real scans - does not hold, and Khozai’s Vₙ layer is an expensive null.
Bet 2 is an empirical question. The answer comes from testing, not from argument.
Bet 3
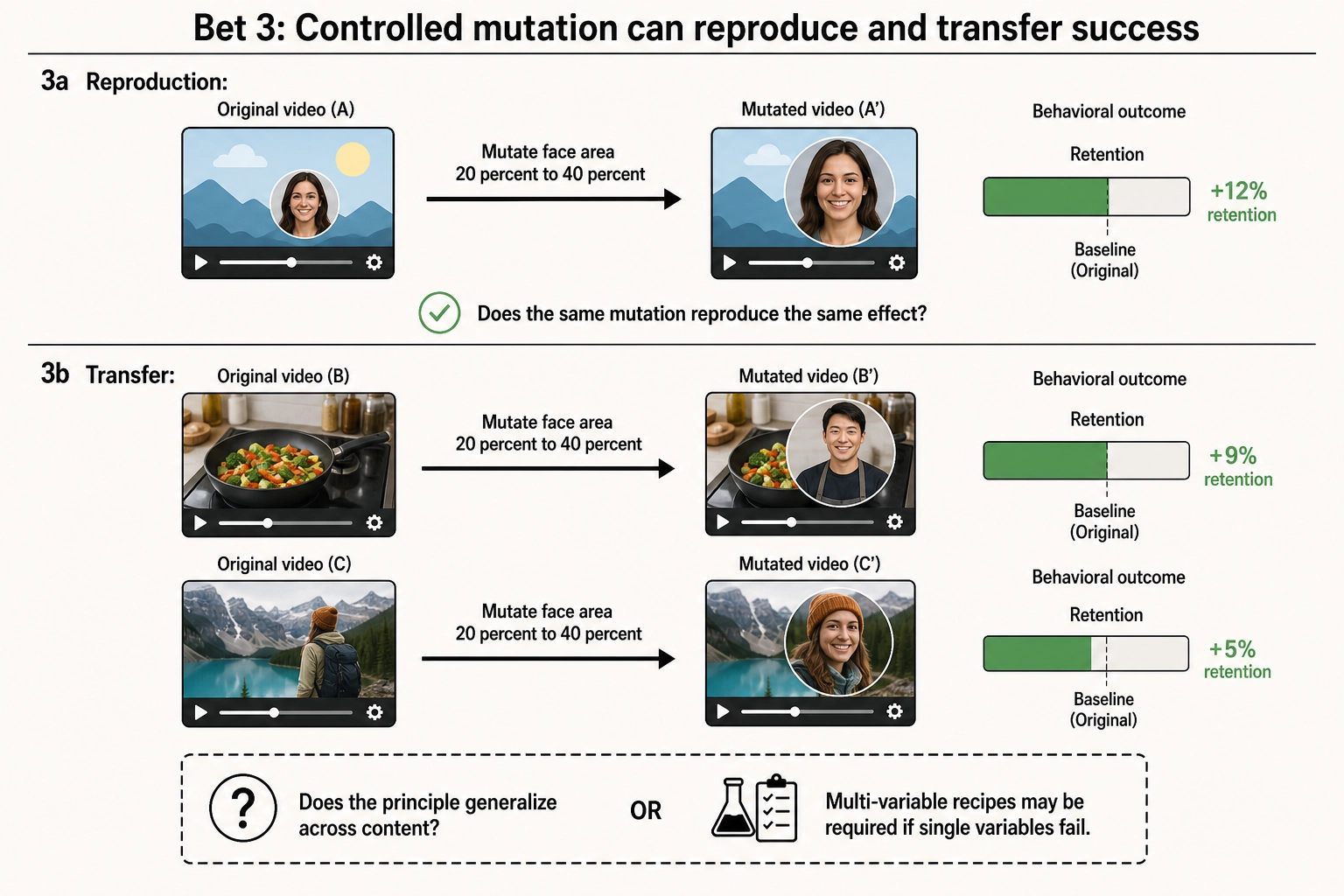
Bet 3: Controlled single-variable mutation can reproduce and transfer success.
The first two bets ask whether Khozai can measure and predict. This bet asks whether it can act. It has two distinct sub-hypotheses with different failure implications:
Bet 3a - Reproduction: If Khozai identifies that a specific physical property - face area, cut rate, spectral power - correlates with higher retention for a given persona, mutating that property in the same content will reproduce the effect. If 3a fails, the correlations are real but the physics-level control is too coarse - other unmeasured properties co-vary with the target property in ways that cannot be isolated.
Bet 3b - Transfer: A mutation principle learned on one piece of content (e.g., “increasing face area from 20% to 40% raises fusiform activation and correlates with +12% retention for persona X”) transfers to other content with similar structure. If 3b fails but 3a succeeds, Khozai becomes a per-content optimization tool - it can improve a specific video through iterative mutation, but cannot generalize principles across content. This is still valuable but falls short of a general knowledge system.
A third possibility exists between full success and full failure: individual variables may have no reliable effect alone, but specific combinations of variables - a coordinated shift in face area, luminance, and cut rate together - reproduce and transfer as a set. If this is what the experiments reveal, actionability requires multi-variable “recipes” rather than single-variable principles, and the experimental design must evolve from single-variable mutation to systematic combinatorial testing. This is harder (the search space grows exponentially) but still tractable if the brain encoding model can predict which combinations are likely to interact: the experiential space provides a basis for hypothesizing which variables should co-move (e.g., variables that converge on the same network activation).
Success criteria for Bet 3. In controlled experiments, mutating a single physical property (or a defined combination) that the correlation engine identified as predictive produces a statistically significant shift in Vₚ outcomes in the predicted direction. The effect replicates across at least two distinct content pieces with similar structural properties (transfer), and the effect size is practically meaningful - large enough to inform content decisions, not merely statistically detectable. For multi-variable recipes: the combination produces effects that the individual variables do not produce alone.
Failure criteria for Bet 3. Mutations produce no reliable behavioral effects - neither single-variable nor multi-variable combinations reproduce the correlations the engine identified. The correlations are observational artifacts that do not survive intervention. If this is the result, Khozai can explain past performance but cannot engineer future performance. The system becomes diagnostic (why did this work?) rather than prescriptive (what should I change?).
Bet 3 is an empirical question. The answer comes from testing, not from argument. Reproduction (3a) is tested before transfer (3b), and single-variable effects are tested before combinations.
All three bets together
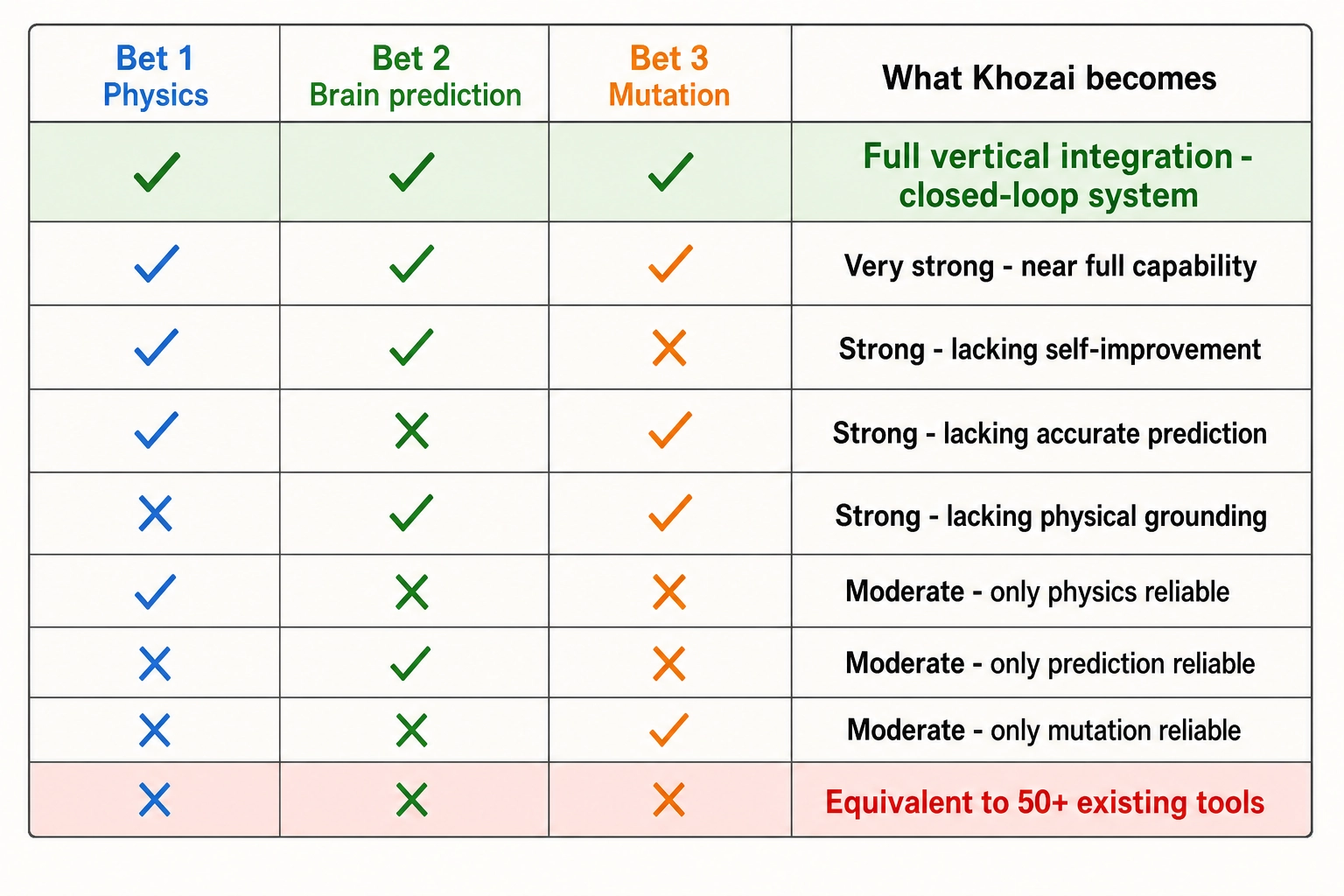
The following table maps every combination of bet success and failure to the system Khozai becomes in each scenario.
| Bet 1 (Physics) | Bet 2 (Brain prediction) | Bet 3 (Mutation) | What Khozai becomes |
|---|---|---|---|
| Fail | Fail | Fail | Semantic creative intelligence platform (Vc-Vₚ only) - equivalent to the 50+ existing tools, with a different architecture |
| Succeed | Fail | Fail | Physics-level creative analysis tool: V₀/V₁/V₂ capture signal semantic tagging misses, but no neuroscience grounding and no actionable mutation |
| Fail | Succeed | Fail | Neural-grounded creative analysis tool: Vc-Vₙ-Vₚ explains why content works, but physics adds no value and mutations are not actionable |
| Fail | Fail | Succeed | Not meaningful: mutation without measurement signal has no basis for selecting what to mutate |
| Succeed | Succeed | Fail | Comprehensive diagnostic system: physics measurement + cortical prediction + behavioral correlation explains why content worked, but cannot prescribe what to change |
| Succeed | Fail | Succeed | Physics-based mutation tool: physics features predict outcomes and mutations reproduce effects, but without neuroscience grounding for interpretation |
| Fail | Succeed | Succeed | Neural-grounded mutation tool: cortical predictions guide mutations that work, but physics layer adds no incremental value |
| Succeed | Succeed | Succeed | Full vertical integration (Chapter 1 section 9): physics measurement, brain prediction, controlled mutation, behavioral correlation, neuroscience interpretation - a closed-loop system that predicts and prescribes |
The table above maps every combination. The key takeaway: partial success still produces a usable system. Total failure reduces Khozai to what 50+ companies already offer. Full success delivers the closed-loop vertical integration described in Chapter 1 section 9, where the system predicts and prescribes. The framework’s architecture ensures that each bet is independently testable and that any combination of outcomes leaves a coherent, if reduced, system.
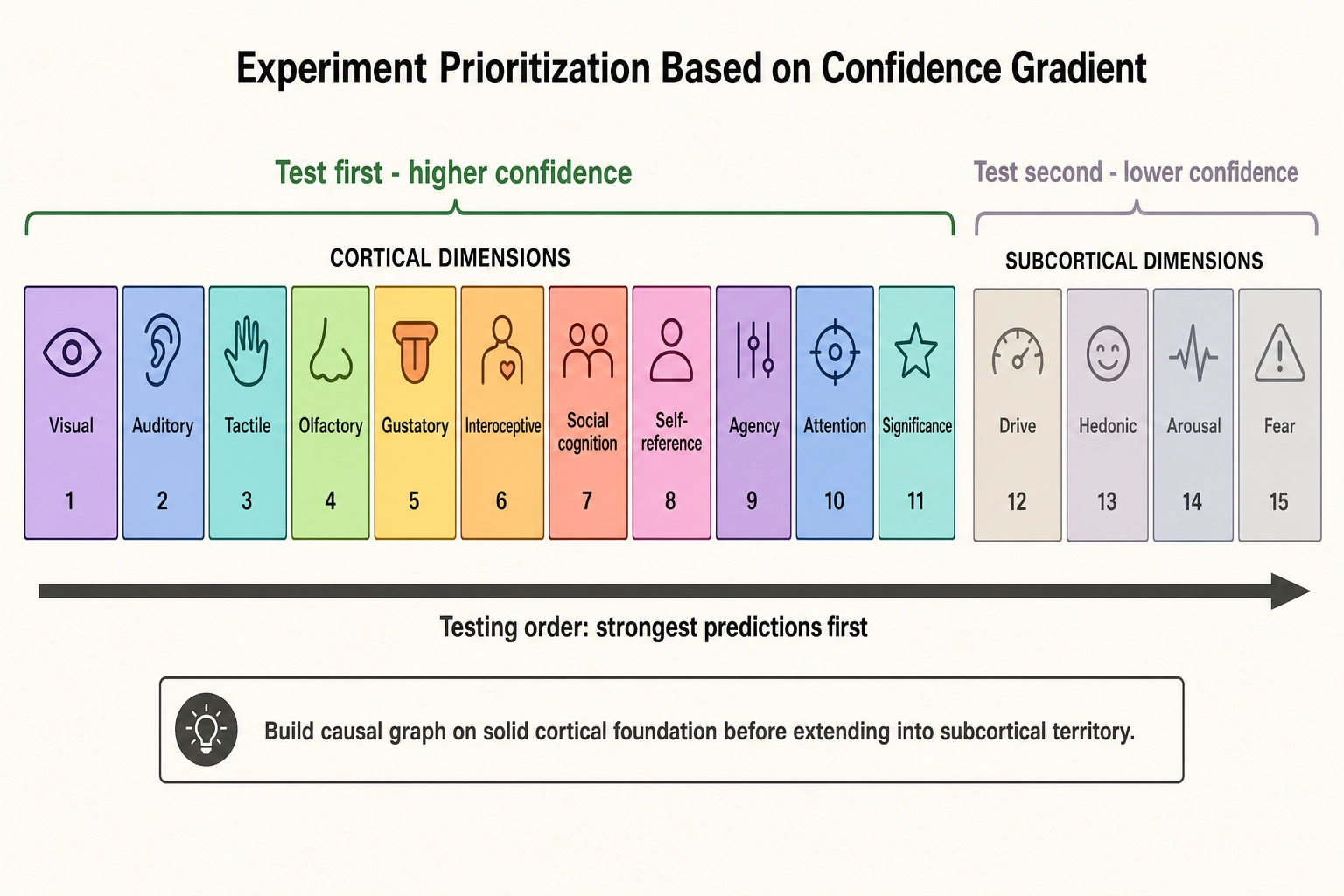
The confidence gradient from Chapter 4 creates a natural experiment-prioritization order. Eleven of the eighteen Resolution Level 2 dimensions sit at higher confidence (cortical surface, directly readable by TRIBE v2): Visual, Auditory, Tactile, Olfactory, Gustatory, Interoceptive, Social cognition, Self-reference, Agency, Attention, and Significance. These should be tested first because the framework’s predictions are strongest there. If Bet 2 succeeds for cortical dimensions - if predicted cortical activation in visual, auditory, social, and attention areas tracks behavioral outcomes - that establishes the basic architecture on solid ground. The subcortical dimensions (Drive, Hedonic, Arousal, Fear) can then be approached with behavioral proxies, cortical correlates, and self-report as targeted supplements, knowing that the cortical core holds. Testing in this order means that early experiments operate where measurement confidence is highest, building the causal graph on its strongest possible foundation before extending into lower-confidence territory.
3. Risks Separate from Bets
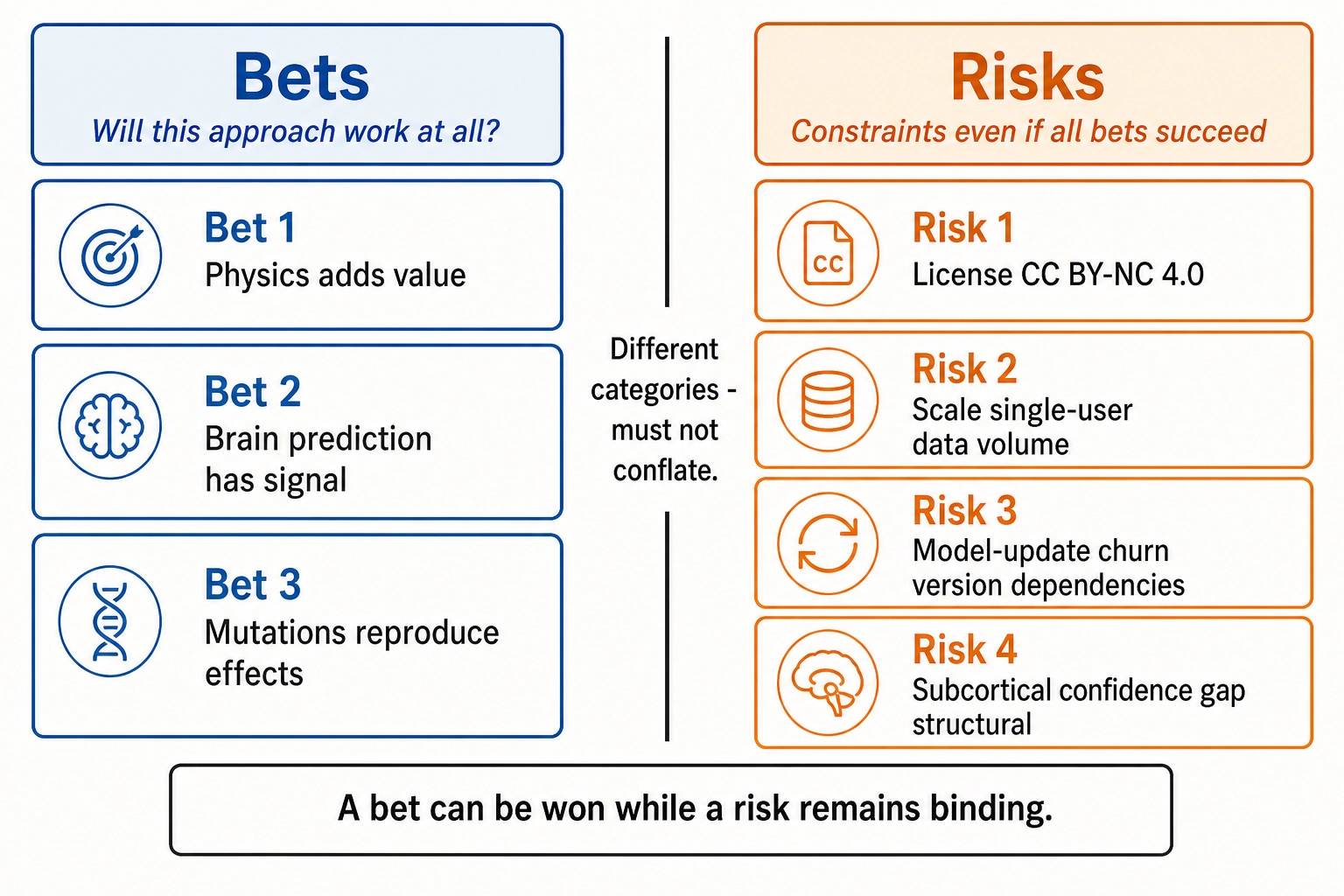
Bets ask “will this approach work at all?” Risks describe constraints that apply even if all three bets succeed. These are different categories and must not be conflated (per book writing rules section 3). A bet can be won while a risk remains binding.
3.1 License constraint
TRIBE v2 is released under CC BY-NC 4.0. The license defines NonCommercial as “not primarily intended for or directed towards commercial advantage or monetary compensation.” If Khozai is used to produce content that generates revenue - through marketing, monetized content, or any revenue-generating activity - that use is directed towards commercial advantage, even if Khozai is never sold as a product and has only one user. This constraint applies whether or not the bets succeed.
Three options exist for commercial deployment, and all three are always stated together: (1) obtain a commercial license from Meta; (2) rebuild the equivalent capability on an open dataset such as CNeuroMod (~200 hours per subject, CC0 processed data); (3) use TRIBE v2 only for non-commercial research phases while building a clean-room alternative for commercial deployment. Option 2 is technically feasible but requires substantial engineering and training compute. Option 1 depends on Meta’s willingness to license; as of April 2026, no commercial licensing program for TRIBE v2 has been published or announced. Option 3 is the conservative path that delays commercial deployment until the licensing question is resolved.
The license is not a minor issue. It is a structural constraint on Khozai’s path from research tool to operational system.
3.2 Scale
Platform ad engines learn from billions of impressions. Creative intelligence tools like Segwise process data from 15+ ad networks simultaneously. Khozai operates at individual scale - one author, one content pipeline. Its correlations will be based on hundreds to thousands of experiments, not billions of data points. Whether meaningful signal can be extracted at this scale is an empirical question that differs from all three bets. Even if physics-level features add value (Bet 1 succeeds), predicted cortical activation predicts performance (Bet 2 succeeds), and mutations reproduce effects (Bet 3 succeeds), the correlations may require more data than a single-user operation can generate. The controlled-mutation methodology (Chapter 7) and the hybrid workflow (historical video as reference, forward mutations as experiments) are designed to maximize the information yield per experiment, but the scale constraint is real.
3.3 Model-update churn
TRIBE v2 is a v2. There will be a v3. When the underlying brain encoding model is updated, every Vₙ value computed from the previous version becomes stale: the cortical activation predictions change, and every downstream analysis built on those predictions must be re-evaluated. The same applies to the Vc layer: when the vision-language model is updated (from Gemini 2.5 Pro to a successor), every Vc value computed with the previous model changes. The calibration governance in Chapter 10 addresses this through version tracking and the EMPIRICAL framework’s re-evaluation protocol, but the churn is a cost that compounds with the size of the experiment database. At scale, model updates are expensive not because the computation is expensive, but because the analytical conclusions may shift.
3.4 Subcortical confidence gap as ongoing risk
The subcortical confidence differential (section 1.2 above) is both a limitation and a risk. As a limitation, it means subcortical predictions carry less certainty than cortical predictions. As a risk, it means that even a fully successful framework - all three bets won, meaningful correlations established - relies on lower-confidence predictions for the subcortical processing that multiple published studies have identified as predictive of content performance. Reward processing, arousal regulation, and threat detection are predicted, but the confidence gap means those predictions may not preserve enough signal to be actionable. A competitor or successor system with better subcortical reconstruction quality would achieve higher-confidence coverage of this territory. Future encoding models may narrow the gap; until they do, the confidence differential is a structural risk.
4. What Would Falsify the Framework
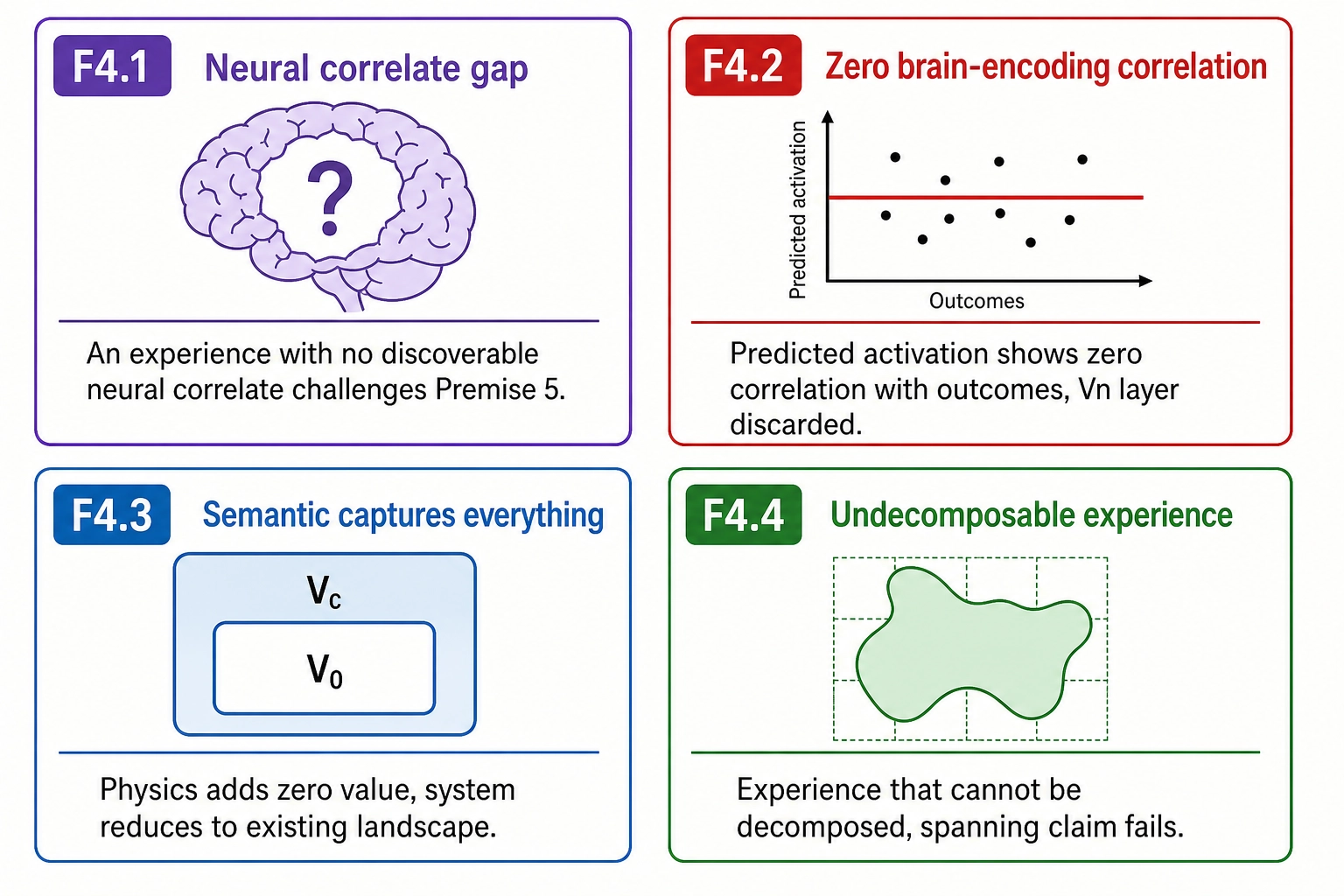
A framework that cannot be falsified is not a scientific framework. Khozai’s formal structure - premises, spaces, mappings, vectors, reasoning tools - makes specific claims that are testable, and each testable claim has a failure mode that would require revising or abandoning part of the framework. Four falsification scenarios are stated explicitly.
| # | Falsification scenario | What it challenges | Consequence if confirmed |
|---|---|---|---|
| F4.1 | Neural correlate gap: an aspect of experience with no discoverable neural correlate | Premise 5 (structure-experience mapping is specific and graded) | Experience Space may be incomplete in ways the framework cannot complete by its own methods |
| F4.2 | Zero brain-encoding correlation: predicted cortical activation shows zero correlation with behavioral outcomes | Bet 2 (brain prediction carries enough signal) | Vₙ layer is discarded; V₀, Vc, and Vₚ remain |
| F4.3 | Semantic captures everything: Vc features capture 100% of actionable signal; V₀/V₁/V₂ add zero incremental value | Bet 1 (physics adds value beyond semantics) | Physics layer is dropped; system reduces to existing landscape depth |
| F4.4 | Undecomposable experience: a reliably identified experience that cannot be decomposed into the dimension set | Spanning claim (Tool 3) | Experience Space must be expanded or acknowledged as approximate |
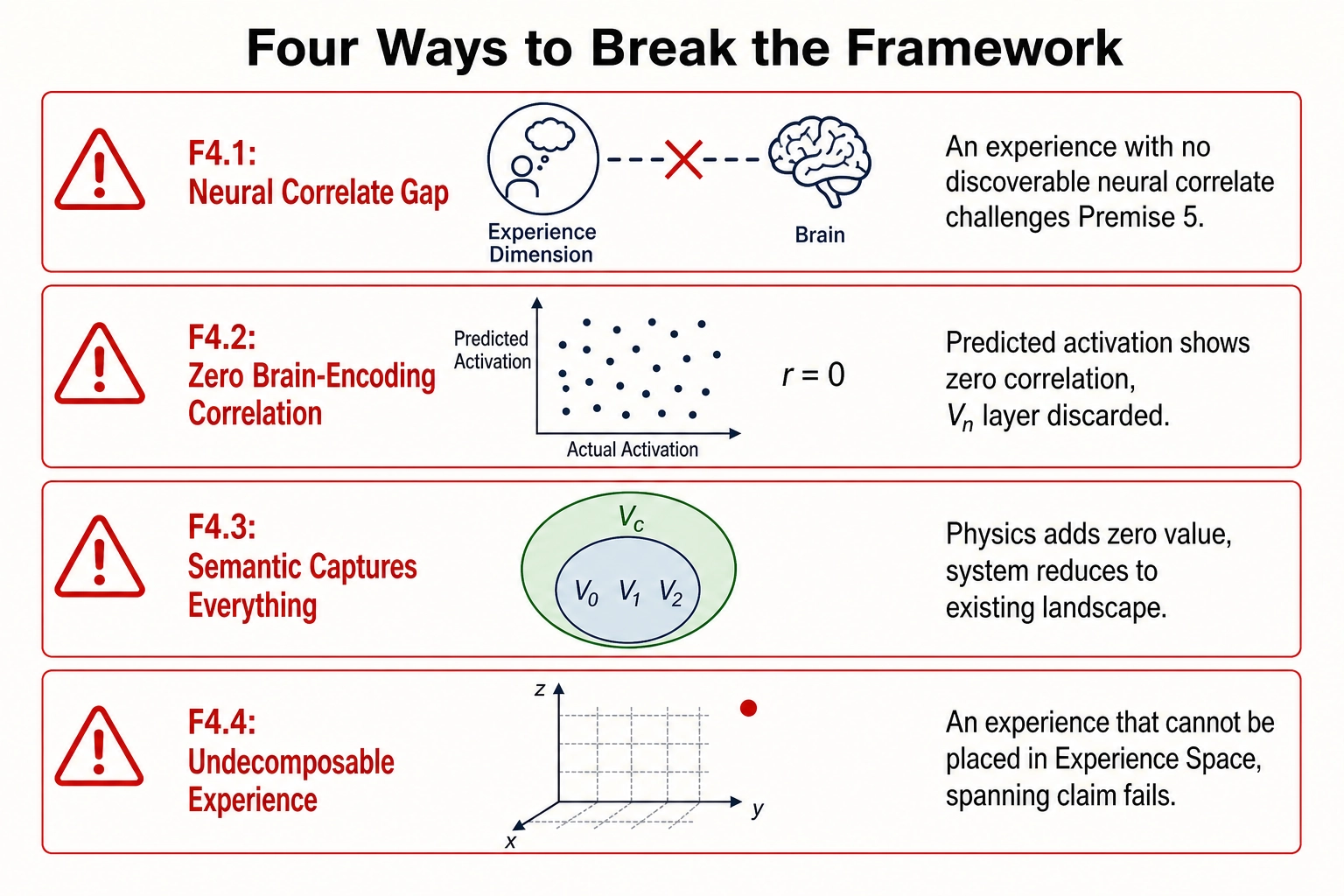
4.1 Neural correlate gap
If an aspect of human experience is identified that has no discoverable neural correlate - no brain structure whose alteration or elimination changes that specific aspect - then Premise 5 (the structure-experience mapping is specific and graded) is challenged. Premise 5 is the premise that makes Experience Space decomposable and makes the entire project of finding independent experiential dimensions possible. A genuine neural-correlate gap would mean either that the framework’s dimension list is incomplete in a way that cannot be completed by the framework’s own methods, or that the relationship between neural structure and experience is less systematic than Premise 5 claims.
The defense is partial: the absence of a known neural correlate is not the same as the absence of a neural correlate. Neuroscience may not yet have identified the relevant structure. But a persistent, well-studied failure to find any neural substrate for a reliably reported experiential phenomenon would accumulate as evidence against Premise 5’s claim of completeness.
4.2 Zero brain-encoding correlation
If TRIBE v2’s predicted cortical activation patterns show zero correlation with behavioral outcomes - across all content categories, all persona segments, all Vₚ metrics - then Bet 2 fails. The brain-to-performance bridge described in Chapter 1 section 4.2 does not survive the prediction step. The predicted signal is too noisy to be useful.
This would not invalidate the published scanner studies. Venkatraman et al. (2015), Falk, Berkman & Lieberman (2012), Tong et al. (2020), and Scholz, Chan, Falk et al. (2025) used real fMRI data and found real correlations. The falsification would be specific to the prediction step: the encoding model’s approximation of cortical activation does not preserve the signal that the real measurements captured. The framework’s Vₙ layer would be discarded; V₀, Vc, and Vₚ would remain.
4.3 Semantic captures everything
If semantic-level analysis (Vc features) captures 100% of the actionable signal in predicting behavioral outcomes, and physics-level features (V₀/V₁/V₂) add zero incremental value, then Bet 1 fails. The 50+ creative intelligence companies working at the semantic level are already operating at the right depth. Going deeper adds cost without benefit.
This would not invalidate the framework’s architecture - the four spaces, the five mappings, the reasoning tools would remain coherent descriptions of how information flows from stimulus to brain to behavior. But the practical system would lose its physics layer, reducing to the same operational depth as the existing landscape, with a different analytical architecture.
4.4 Undecomposable experience
If a moment of human experience is reliably identified that cannot be decomposed into the dimension set - an experience that survives all attempts to locate it as a point in Experience Space using the current dimensions, with a genuine residual that no additional dimension captures - then the spanning claim (Tool 3) fails. Experience Space, as characterized, does not span all of experience.
The spanning claim is, by design, falsifiable but never provable (Chapter 2 section 2.3). Confidence in spanning increases with the diversity and number of failed falsification attempts. A single, well-documented counter-example would require either adding new dimensions (expanding the framework) or acknowledging that Experience Space as characterized is an approximation rather than a complete description. The framework is designed to accommodate the first response - adding dimensions is extension, not destruction. The second response - acknowledging incompleteness - is a version of what the framework already says about Scope B.
5. Ethical Limitations
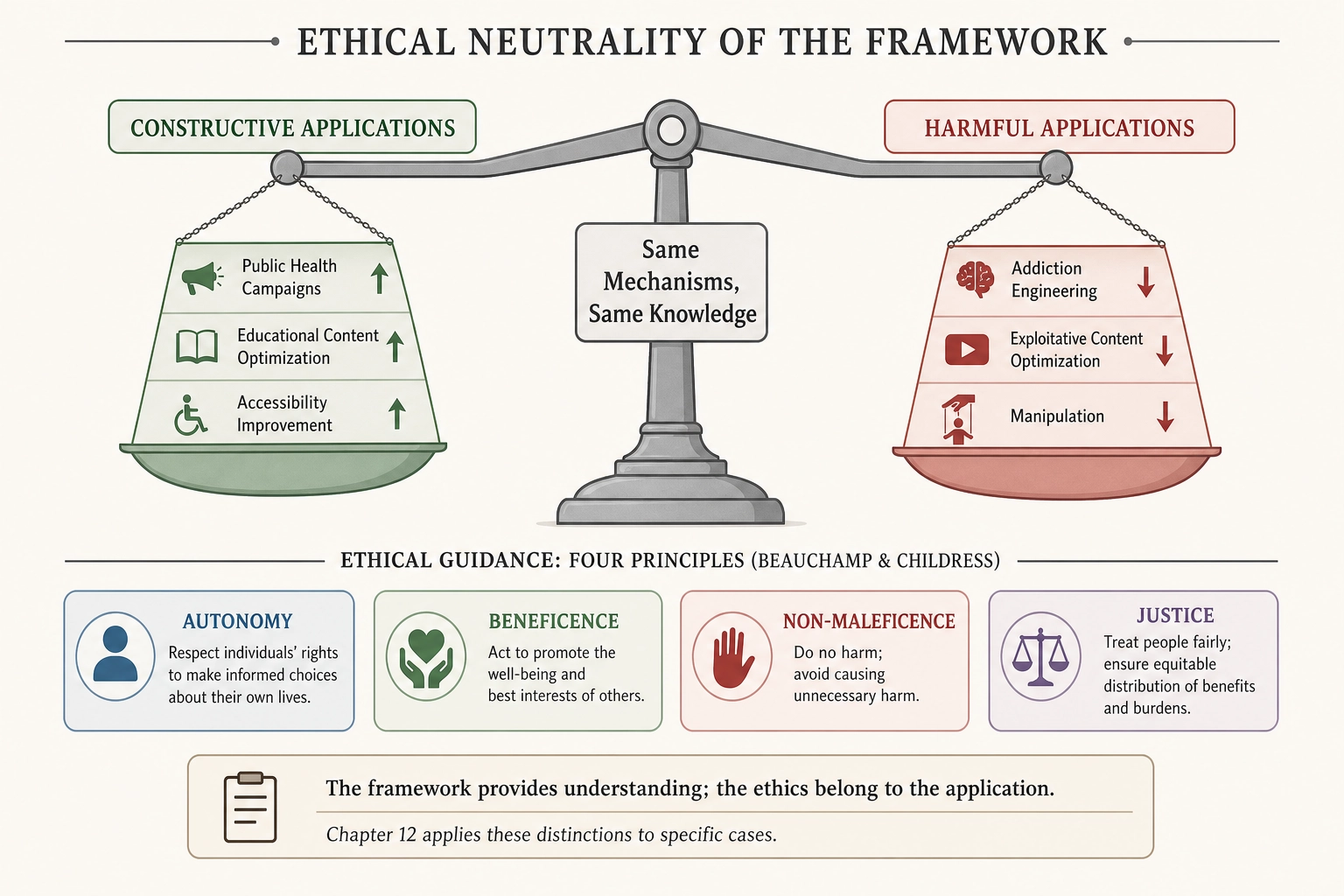
The framework is ethically neutral in the abstract. It describes mechanisms: how physical stimulus properties map to neural activation, how neural activation maps to behavioral output, how controlled mutations of stimulus properties produce measurable changes in behavior. The mechanisms themselves are neither good nor bad. They are properties of the physical world and the biological systems that process it.
This neutrality is not evasiveness. The framework does not pretend that its outputs cannot be used harmfully. The same knowledge that helps a public health communicator design a more effective anti-smoking campaign helps an addiction engineer design a more compelling gambling interface. The same mutation that increases retention for educational content increases retention for exploitative content. The mechanisms are the same mechanisms. The knowledge is the same knowledge.
Chapter 12 enumerates concrete dual-use applications - good-intention uses and bad-intention uses, with the same specificity applied to both. This section frames only the abstraction: the framework itself does not prescribe what content should be optimized, for whom, toward what end, or under what constraints. Those are decisions the user makes. The framework provides the understanding; the ethics belong to the application.
The dual-use ethics literature provides frameworks for evaluating these risks. Beauchamp and Childress’s (2019) four principles - autonomy, beneficence, non-maleficence, and justice - apply directly: the constructive applications serve beneficence and autonomy, while the destructive applications violate non-maleficence. Chapter 12 applies these distinctions to specific use cases.
6. What Comes Next
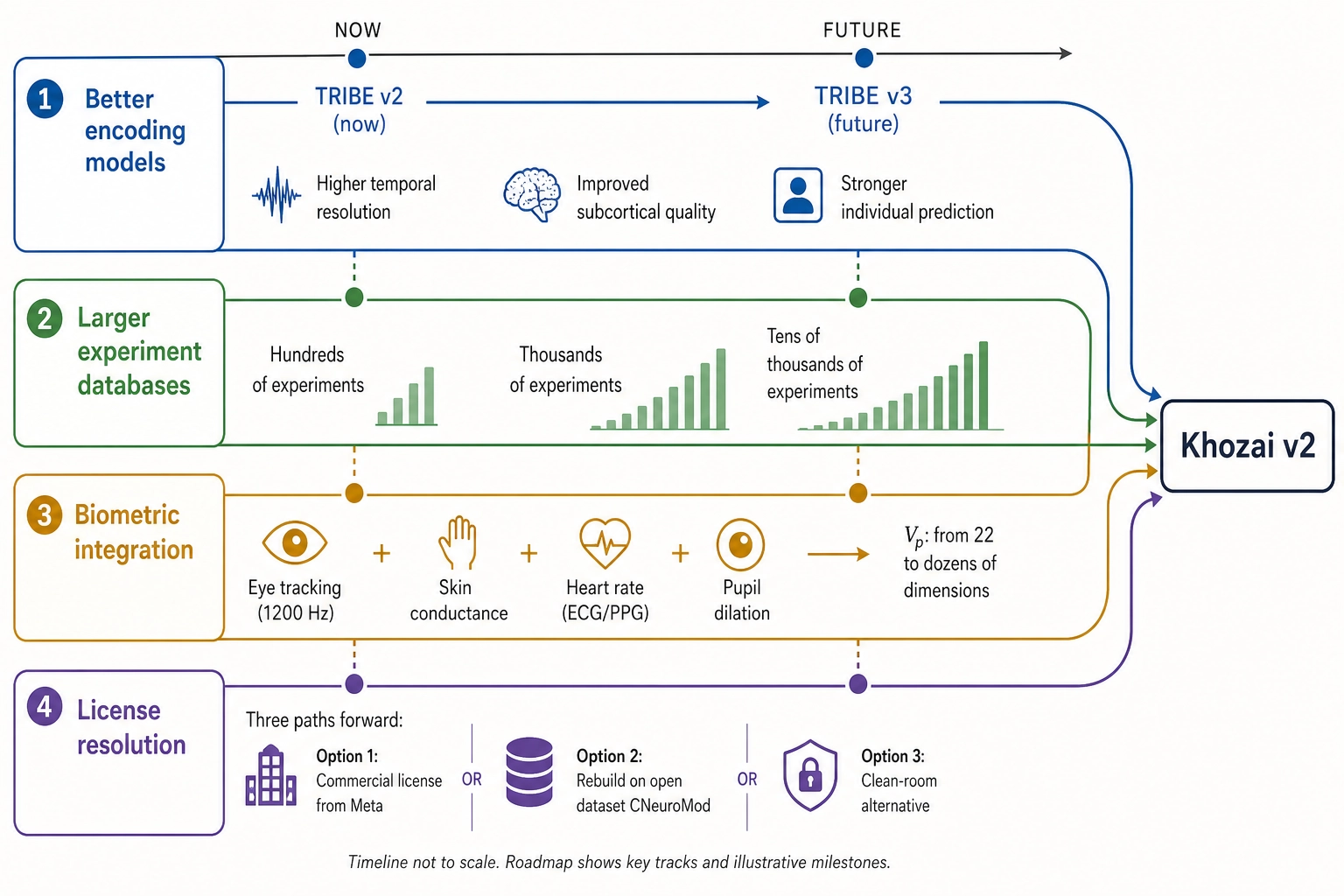
The limitations in section 1 are real, but none of them are permanent. Each one traces to a specific technical boundary - a model’s resolution, a dataset’s scope, a licensing constraint, a measurement channel not yet connected - and each boundary is, in principle, movable.
Better encoding models
TRIBE v2 is the state of the art as of April 2026. TRIBE v1 won the Algonauts 2025 Challenge against more than 260 teams. TRIBE v2 improved resolution significantly and exhibits log-linear scaling without plateau. There is no reason to expect the scaling to stop. Future brain encoding models may achieve finer temporal resolution, better subcortical reconstruction quality, and individual-specific prediction from population data. Each improvement narrows one of section 1’s limitations without requiring any change to the framework’s architecture: Vₙ is defined by what it represents (an approximation of Neural State Space), not by which model computes it. A better model plugs into the same schema.
Larger experiment databases
The scale constraint (section 3.2) weakens with every experiment. The cumulative causal graph (Chapter 8 section 5) grows richer with each mutation and each observed behavioral outcome. If the framework succeeds, its predictions become more precise over time: each experiment makes the next experiment more informed. Multi-user deployments, if the licensing constraint is resolved, would compound this effect across operators.
Biometric integration
The Vₚ measurement horizon (section 1.5) is narrow by design: platform metrics are what a single-user operation can access without biometric equipment. But the framework’s architecture does not prohibit richer behavioral measurement. Eye tracking (Tobii at 1200 Hz), skin conductance, heart rate, pupil dilation - all are biometric signals that map to specific dimensions of Behavioral Output Space. Integrating them would expand Vₚ from 22 platform-metric dimensions to dozens of physiological dimensions, connecting the framework to the biometric measurement tradition that the neuromarketing tools already use. The integration is engineering, not architecture: the four spaces, the five mappings, and the reasoning tools accommodate it without modification.
Future versions of this book
This book is a v1 snapshot. The framework it describes is the author’s current best formulation: the result of integrating published neuroscience, mathematics, engineering tools, and design decisions into a coherent system. It is not a final pronouncement.
The philosophy that governs the framework also governs the book that describes it. Chapter 1 section 12 established two principles: “Hypotheses, not truths” - every calibration value, every threshold, every correlation is a current best estimate subject to empirical refinement - and “Self-correcting” - calibration values that do not match empirical findings get updated, correlations that do not replicate get discarded. These principles apply to the book itself. As empirical findings accumulate, as better models emerge, as the experiment database grows and the predictions sharpen or fail, the framework will change. A future v2 of this book is anticipated, not avoided. Readers should treat what they hold as a starting point for their own thinking, not as a settled doctrine.
This is consistent with the project’s design, not in tension with it. The book writing rules (section 10) describe the rules document as a living document. The calibration governance (Chapter 10) includes a self-correction protocol. The BOOK_PLAN_v3 explicitly anticipates a future v2 and defines “locked” as “committed within v1,” not as “immutable.” The framework is open to optimization as empirical findings accumulate. That openness is a feature of its scientific character, not a weakness.
7. Tool 13 (Consistency) - Operational Note
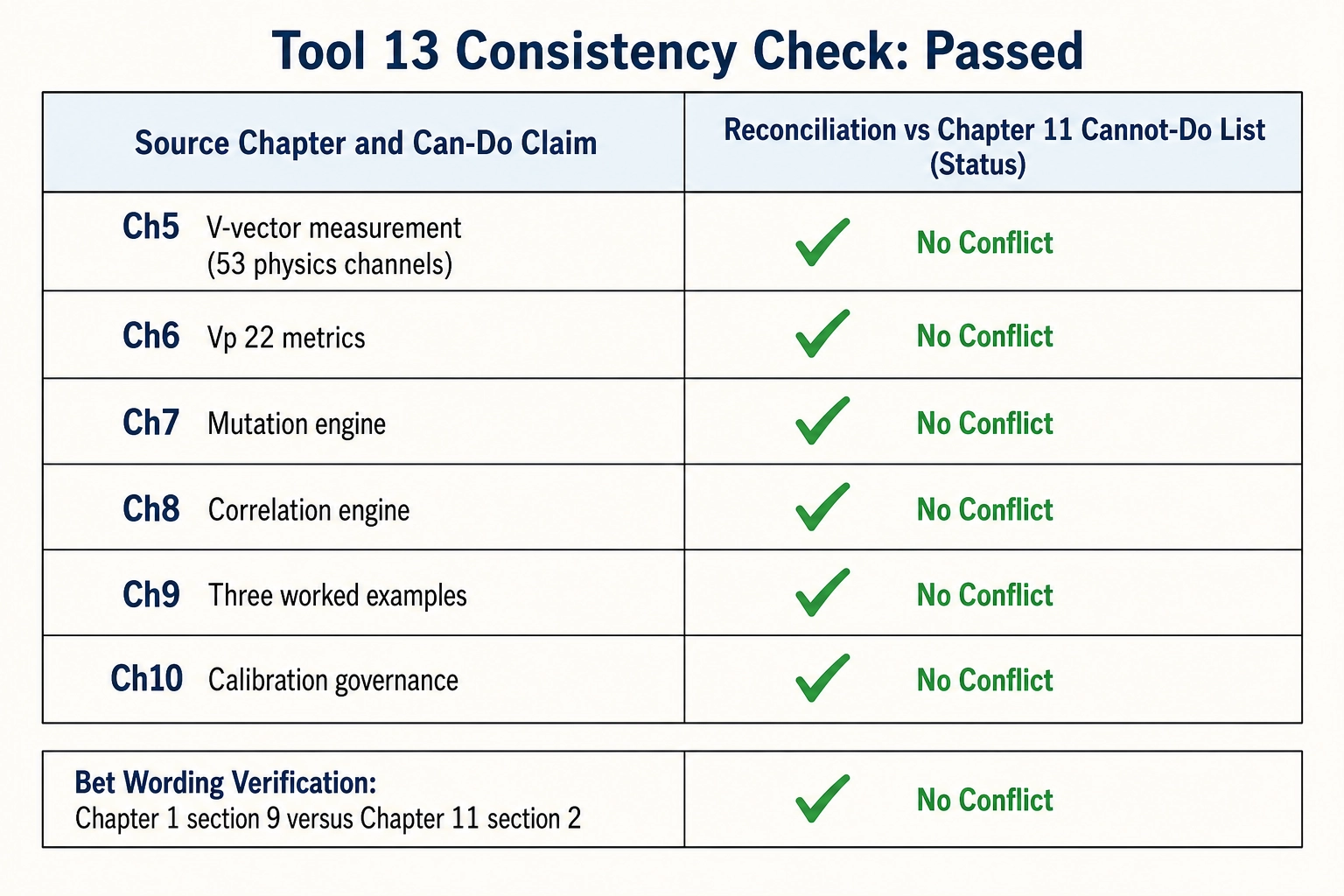
This chapter is itself the strongest internal-consistency check on the book. Every can-do claim from Chapters 5 through 10 must reconcile with section 1’s cannot-do list. Every bet stated in Chapter 1 must match section 2’s wording verbatim. Every limitation must trace to a premise, a measurement boundary, or a design choice. If a claim elsewhere in the book says Khozai can do something that section 1 says it cannot, one of the two is wrong and the inconsistency must be resolved before the book is complete.
The reconciliation, section by section:
Chapter 5 can-do: Khozai measures V₀ (25 channels), V₁ (16 channels), V₂ (12 channels), Vc (32 dimensions across 9 categories), Vc-temporal (24 channels), and Vₙ (360 Glasser areas at 1 Hz plus Yeo 7 coarse tier). Total physics channels: 53 (25 + 16 + 12). Reconciliation with section 1: V₀/V₁/V₂ are physics - no limitation applies to their computation. Vc is model-dependent and subject to model-update churn (section 3.3), but not to the five structural limitations in section 1. Vₙ is subject to all five: it cannot access Scope B (section 1.1), predicts subcortical at lower confidence (section 1.2), is average-subject (section 1.3), operates at 1 Hz (section 1.4), and does not expand the behavioral measurement horizon (section 1.5). No conflict.
Chapter 6 can-do: Khozai measures Vₚ (22 platform metrics) and extracts self-report data. Reconciliation with section 1.5: Vₚ captures a fraction of Behavioral Output Space - motor-output digital actions only. Self-report provides partial, noisy access to Scope B. Both limitations are stated in Chapter 6 section 3 and in section 1.5 above. No conflict.
Chapter 7 can-do: The mutation engine generates controlled single-variable variants via the scene-AST substrate. Reconciliation: the mutation engine changes the content file. It does not change the viewer, the brain, or the measurement limitations. A mutation that changes face area can predict the cortical consequence at higher confidence (FFA shift) and the subcortical consequence at lower confidence (reward processing). Chapter 9’s worked examples are chosen accordingly. No conflict.
Chapter 8 can-do: The correlation engine maps content properties to behavioral outcomes and interprets correlations through neuroscience. Reconciliation: interpretation means identifying which cortical regions are involved and which experiential dimensions (Scope A) are likely engaged. It does not mean accessing Scope B. The “face area +30% leads to retention +12% because of stronger fusiform face area activation and stronger social-processing engagement” chain (Chapter 8 section 8, Chapter 9 section 2) is a Scope A inference - which aspects, how strongly - not a Scope B claim about what the viewer felt. The distinction is maintained. No conflict.
Chapter 9 can-do: Three worked examples trace the inference chain end-to-end. Reconciliation: each example uses cortical predictions at higher confidence. The audio-tempo example (Chapter 9 section 3) explicitly notes that arousal regulation itself is brainstem-mediated and predicted at lower confidence; the cortical-side correlate of arousal modulation enters at higher confidence. Both tiers contribute to the interpretation, with the confidence differential stated. No conflict.
Chapter 10 can-do: Calibration governance provides versioned threshold values and reliability tags. Reconciliation: calibration values are empirical and subject to the self-correction protocol. The EMPIRICAL framework explicitly anticipates that values will change as evidence accumulates. This is consistent with the v1-not-immutable framing in section 6 above. No conflict.
Bet wording verification. The bet wording in section 2 is reproduced verbatim from Chapter 1 section 9. Bet 1: “Physics-level content properties add predictive value beyond semantic-level properties.” Bet 2: “Predicted brain activation from an encoding model carries enough signal to predict content performance.” Bet 3: “Controlled single-variable mutation can reproduce and transfer success.” All three match Chapter 1’s text. No drift.
The consistency check is passed. The can-do claims from Chapters 5 through 10 are compatible with section 1’s cannot-do list, the bets in section 2 match Chapter 1 section 9 verbatim, the risks in section 3 are separated from the bets, and the falsification conditions in section 4 trace to specific premises and measurement boundaries. The framework as described is internally consistent as of this writing: a v1 snapshot, open to revision, but not self-contradictory.
What this does NOT say
This chapter does not claim that the three bets will succeed. It states them as empirical propositions that the framework’s value depends on - and specifies what happens if each one fails. This chapter does not claim that the five structural limitations are permanent: each limitation traces to a specific technical boundary (encoding-model resolution, dataset scope, license constraint, measurement horizon) that is, in principle, movable. And this chapter does not claim that a consistency check proves correctness - only that the framework is not self-contradictory as of this writing.
Khozai implication
For Khozai as a measurement system, Chapter 11 establishes the honest-disclosure layer: the five limitations define what the system cannot measure or predict (subcortical dynamics at high confidence, cross-cultural generalization, real-time feedback loops), the three bets define what must hold empirically for the system to work, and the falsification scenarios define what evidence would break it. Any user of the framework who does not read this chapter is using the system without knowing its boundaries - and any critic who attacks the framework on grounds already acknowledged here is attacking a position the framework does not hold.
Conclusion
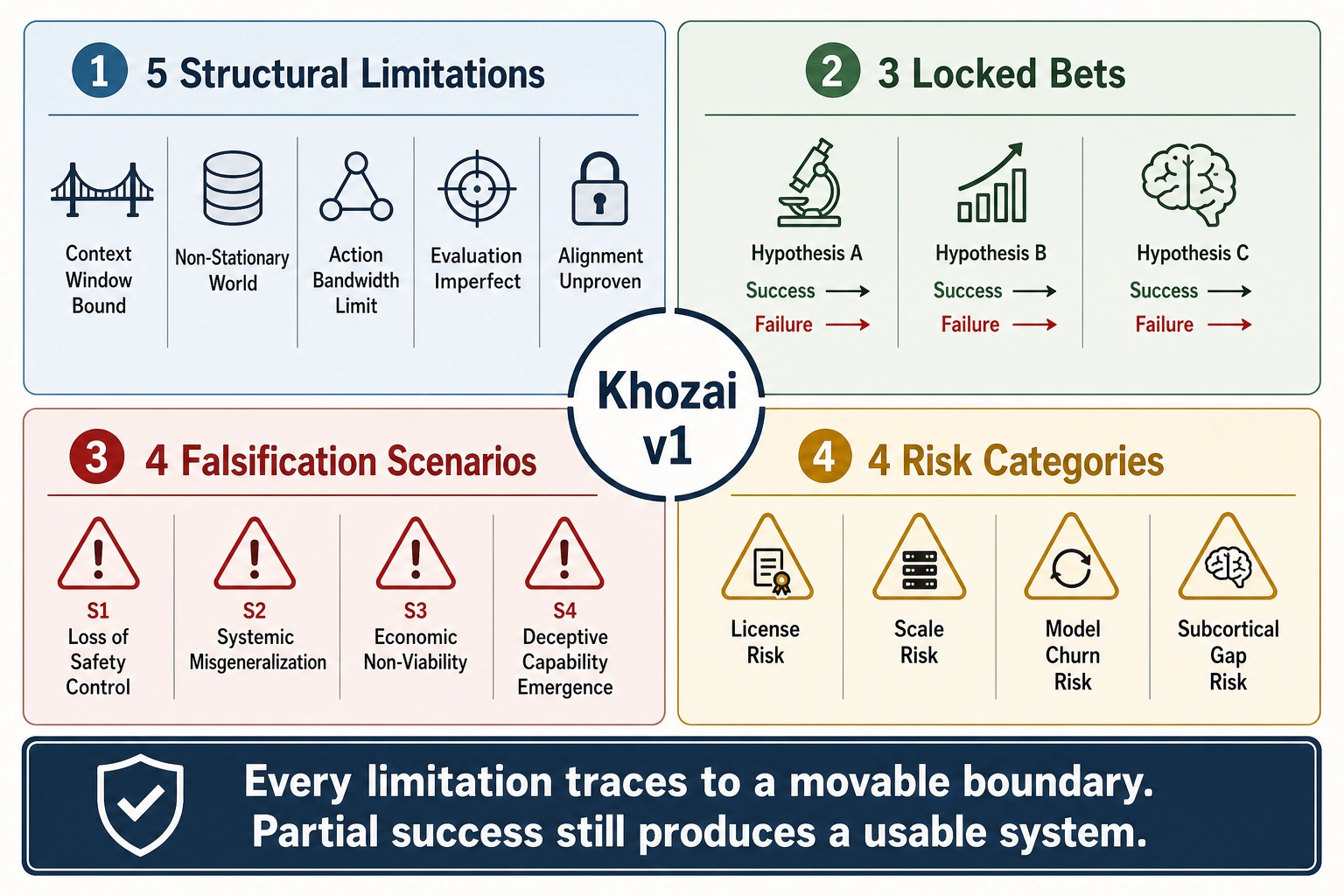
This chapter collected the five structural limitations that bound Khozai v1, restated the three central bets in their locked wording from Chapter 1 section 9, separated risks from bets, and specified four falsification scenarios that would require revising or abandoning parts of the framework. The bet outcomes matrix shows that partial success still produces a usable system, while total failure reduces Khozai to what 50+ companies already offer. Every limitation traces to a specific technical boundary - encoding-model resolution, dataset scope, license constraint, measurement horizon - and each boundary is, in principle, movable as the tools improve. The chapter is itself the book’s strongest internal-consistency check: the can-do claims from Chapters 5 through 10 reconcile with the cannot-do list, the bet wording matches Chapter 1 verbatim, and no self-contradiction was found.
Bibliography
[1] Venkatraman, V., Dimoka, A., Pavlou, P. A., Vo, K., Hampton, W., Bollinger, B., Hershfield, H. E., Ishihara, M., & Winer, R. S. Predicting Advertising Success Beyond Traditional Measures: New Insights from Neurophysiological Methods and Market Response Modeling. Journal of Marketing Research, 52(4), 436-452, 2015. Used in: section 1.2 (subcortical confidence gap), section 2 Bet 2 (success criteria), section 4.2 (falsification).
[2] Tong, L. C., Acikalin, M. Y., Genevsky, A., Shiv, B., & Knutson, B. Brain Activity Forecasts Video Engagement in an Internet Attention Market. Proceedings of the National Academy of Sciences, 117(12), 6936-6941, 2020. Used in: section 1.2 (subcortical confidence gap), section 2 Bet 2 (success criteria), section 4.2 (falsification).
[3] Falk, E. B., Berkman, E. T., & Lieberman, M. D. From Neural Responses to Population Behavior: Neural Focus Group Predicts Population-Level Media Effects. Psychological Science, 23(5), 439-445, 2012. Used in: section 2 Bet 2 (success criteria), section 4.2 (falsification).
[4] Scholz, C., Chan, H.-Y., Falk, E. B., et al. Neural Population-Level Prediction of Real-World Content Engagement. Science Advances, 2025. Used in: section 2 Bet 2 (success criteria), section 4.2 (falsification).
[5] Craig, A. D. How Do You Feel? Interoception: The Sense of the Physiological Condition of the Body. Nature Reviews Neuroscience, 3(8), 655-666, 2002. Used in: section 1.2 (anterior insula as cortical site of interoceptive awareness).
[6] Keuken, M. C., Isaacs, B. R., Trampel, R., van der Zwaag, W., & Forstmann, B. U. Visualizing the Human Subcortex Using Ultra-high Field Magnetic Resonance Imaging. Brain Topography, 31, 513-545, 2018. [REVIEW] Used in: section 1.2 (fMRI SNR challenges for subcortical structures).
[7] Meta AI Blog. Introducing TRIBE v2: A Predictive Foundation Model. https://ai.meta.com/blog/tribe-v2-brain-predictive-foundation-model/, 2025. [BLOG] Used in: section 1.3 (source for approximately 25 training subjects).
[8] Antonello, R. J., Vaidya, A. R., & Huth, A. G. Scaling Laws for Language Encoding Models in fMRI. NeurIPS, 36, 2023. [CONFERENCE] Used in: section 1.3 (scaling laws for encoding models, context for 25-subject training set size).
[9] Thorpe, S., Fize, D., & Marlot, C. Speed of Processing in the Human Visual System. Nature, 381, 520-522, 1996. [JOURNAL] Used in: section 1.4 (scene-change detection at approximately 100 milliseconds).
[10] Crouzet, S. M., Kirchner, H., & Thorpe, S. J. Fast Saccades Toward Faces: Face Detection in Just 100 ms. Journal of Vision, 10(4), 16, 2010. [JOURNAL] Used in: section 1.4 (face detection at approximately 100 milliseconds).
[11] LeDoux, J. E. The Emotional Brain. Simon & Schuster, 1996. [BOOK] Used in: section 1.4 (fast subcortical pathway for threat-relevant stimuli to amygdala).
[12] Pessoa, L. & Adolphs, R. Emotion Processing and the Amygdala: From a ‘Low Road’ to ‘Many Roads’ of Evaluating Biological Significance. Nature Reviews Neuroscience, 11, 773-782, 2010. [REVIEW] Used in: section 1.4 (counterpoint to simple “low road” model, proposing multiple parallel pathways).
[13] Allen, E. J. et al. A Massive 7T fMRI Dataset to Bridge Cognitive Neuroscience and Artificial Intelligence. Nature Neuroscience, 25, 116-126, 2022. [JOURNAL] Used in: section 1.3 (individual-specific brain encoding models requiring individual-specific fMRI data).