Introduction
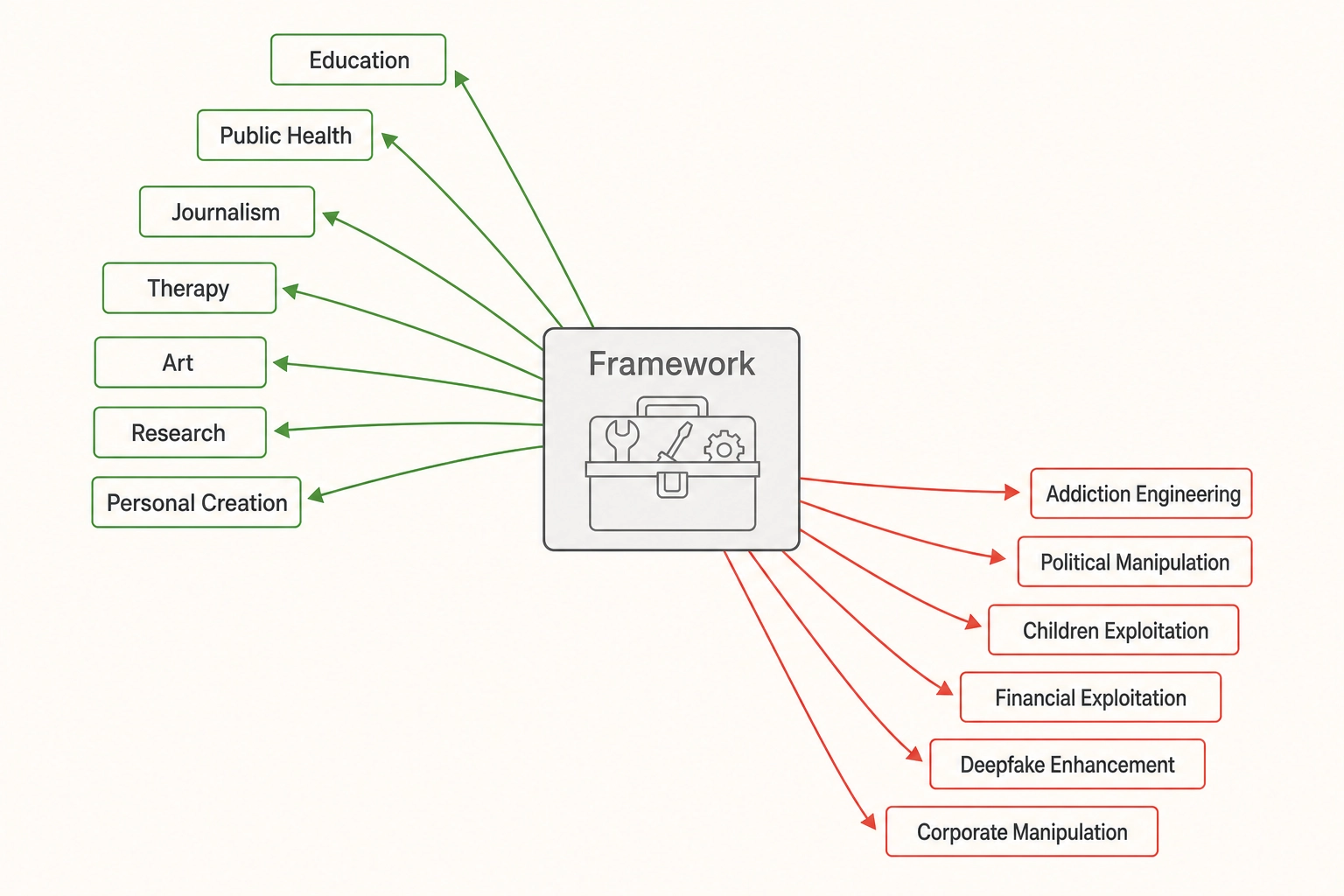
A tool that helps a public health communicator design a more effective anti-smoking campaign helps an addiction engineer design a more compelling gambling interface. The knowledge is the same knowledge. The mechanisms are the same mechanisms. This chapter names both sides with equal specificity, because a framework that describes its beneficial applications in concrete detail while hand-waving its harmful ones is not being honest - it is doing marketing.
Chapter 11 established what the framework cannot do: access subjective experience, predict individual cortical responses, resolve sub-second temporal dynamics. This chapter asks what the framework could do within those limits - by anyone who has access to it, with any intention.
What this chapter covers: Seven constructive applications (personal content creation, education, public health, journalism, therapy, art, research), six destructive applications (addiction engineering, political manipulation, children’s content exploitation, financial exploitation, deepfake enhancement, corporate manipulation), the dual-use comparison, persona dependency, and the ethical-neutrality boundary.
What this chapter does not cover: Implementation timelines, technical deployment details, or regulatory responses to dual-use risk (Chapter 13 addresses the trajectory of these capabilities over time).
1. Conditional Framing
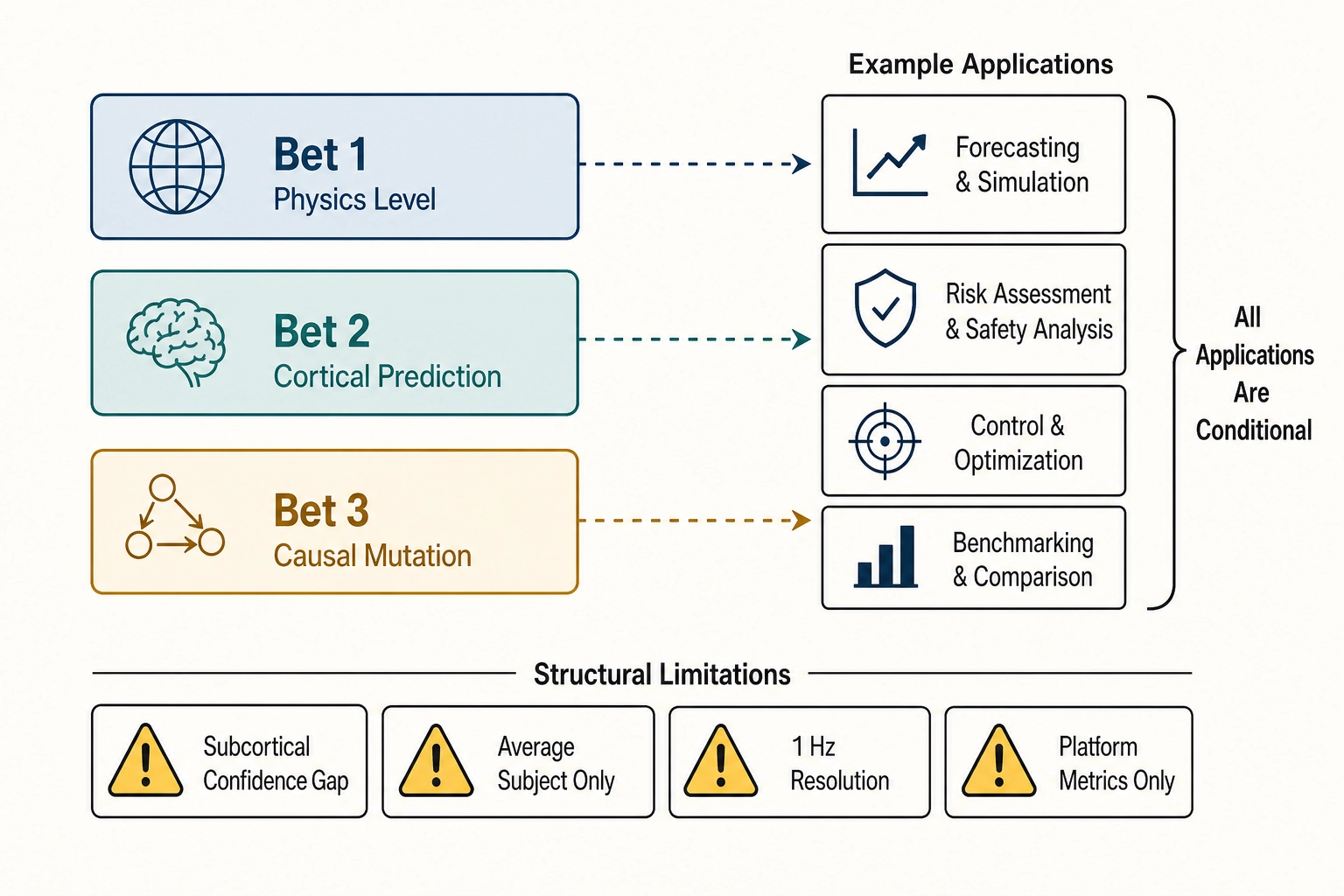
Every application described in this chapter depends on the framework’s bets and limitations as stated in Chapter 11. Where an application requires Bet 1 to hold (physics-level content properties add predictive value beyond semantic-level), it is hedged accordingly. Where it requires Bet 2 to hold (predicted brain activation from an encoding model carries enough signal to predict content performance), that dependency is stated. Where an application runs into a structural limitation - the subcortical confidence differential, the average-subject constraint, the 1 Hz temporal resolution - the limitation is noted. Nothing in this chapter is a promise. Everything is a conditional projection: if the framework works as designed, these are the things it would make possible.
Many of the applications described below ride on persona-specific effect sizes - the Phase 9 persona specification’s core contribution. A content property that increases retention for one behavioral cluster and decreases it for another is useful only when the operator knows which persona they are addressing. Without persona resolution, several of these applications collapse into population-average claims that mask the heterogeneity the framework is designed to reveal.
As of April 2026, none of these applications has been deployed. The framework exists as a specification and a partially implemented pipeline. The applications are what the specification implies, not what has been demonstrated.
2. Good-Intention Applications
The applications in this section assume an operator whose goal is to inform, educate, heal, create, or improve the viewer’s situation. The operator uses the framework’s outputs - which aspects of the viewer’s perception and emotion are involved, how strongly, and how independently - to make content that serves the viewer’s interests alongside the operator’s.
2.1 Personal content creation
A solo content creator - the target reader of this book - publishes short-form video across TikTok, YouTube Shorts, and Instagram Reels. Their content is their livelihood. They currently iterate by intuition: change the hook, try a different thumbnail, adjust the pacing, hope the algorithm responds. When a video underperforms, they scrub to the retention drop-off point and guess what went wrong.
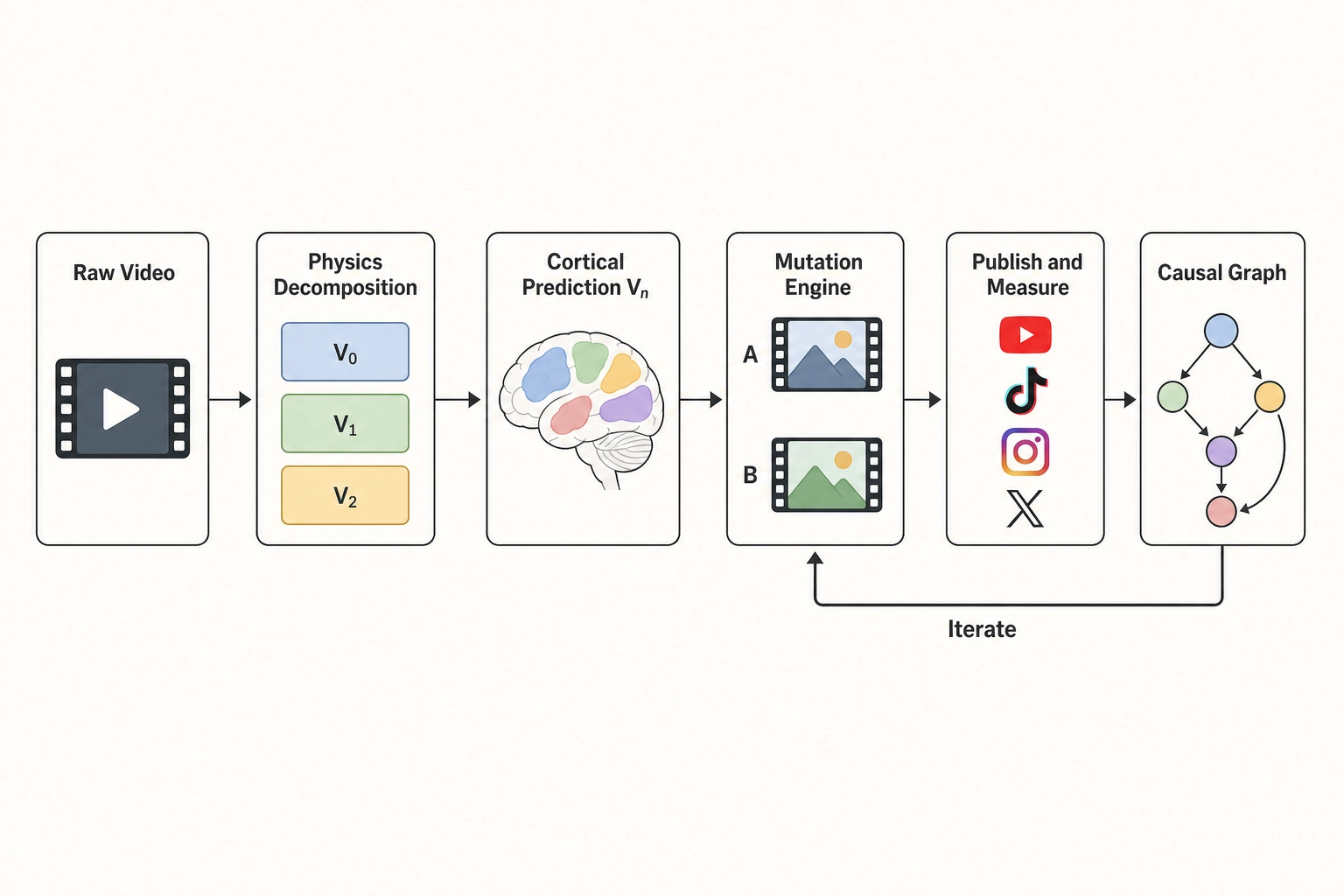
If all three bets hold, the framework would give this creator a different workflow. Before publishing, they would decompose the video into its physical properties (V₀: luminance statistics, spectral power, spatial frequency energy; V₁: cut rate, audio energy envelope; V₂: temporal acceleration patterns) and predict which cortical regions it would activate (Vₙ: predicted activation across the neuroanatomist Matthew Glasser’s 360 cortical areas). They would see, for example, that a specific segment predicts weak fusiform face area activation despite a face being on screen - perhaps because the face occupies only 8% of the frame with low skin-luminance contrast against the background. The mutation engine would generate a controlled variant with face area increased to 30% of frame, and the framework would predict the cortical consequence: stronger FFA activation, stronger predicted social-processing engagement.
After publishing both variants with equal distribution, the creator would observe the behavioral difference: did the face-area mutation produce a retention shift? For which personas? The correlation engine would store the result - face area from 8% to 30%, retention change of +X% for persona A, -Y% for persona B, effect size E with confidence interval C - and the causal graph would grow by one edge.
Concrete measurable example: after 200 experiments over six months, the creator would have a persona-specific causal graph mapping approximately 15-20 content properties to behavioral outcomes. Each edge would carry an effect size, a confidence interval, a replication count, and a neuroscience interpretation (which cortical regions mediate the effect). The creator would know, empirically, that for their audience’s dominant persona, increasing cut rate from 1.5 to 2.5 cuts per second produces a retention increase of approximately N%, while for their secondary persona the same mutation produces no measurable change. This is qualitatively different from the current state of “try things and hope.”
Evidence grading for this application. The claim that face area affects fusiform face area activation rests on peer-reviewed replication: dozens of studies since the cognitive neuroscientist Nancy Kanwisher and colleagues (1997) have established FFA’s face-selectivity. Evidence: Strong - peer-reviewed, extensively replicated. The claim that stronger FFA activation predicts stronger social-processing engagement in a content-performance context rests on fewer studies, primarily the neuroscientist Christin Scholz and colleagues (2025) and Tong et al. (2020). Evidence: Moderate - peer-reviewed but limited to a small number of studies linking specific cortical regions to content performance metrics. The FFA-size scaling link is grounded by lower-level stimulus research: Yue, Vessel & Biederman (2011) demonstrated that lower-level stimulus features strongly influence FFA responses, supporting the inference that increasing face area shifts FFA activation. However, the behavioral link from FFA activation to content retention remains an inference from the established role of face processing in social engagement, not a directly demonstrated causal pathway. The claim that controlled mutation of one physical property isolates causal effects is a methodological assumption, not an empirical finding - confounds from platform distribution, audience timing, and algorithmic interaction could corrupt the causal inference even with single-variable mutation.
The license constraint applies. If the creator monetizes their content - through ads, sponsorships, or product sales - the CC BY-NC 4.0 license on TRIBE v2 means this workflow requires one of the three options stated throughout this book: (1) obtain a commercial license from Meta, (2) rebuild the brain encoding capability on an open dataset such as CNeuroMod (~200 hours per subject, CC0 processed data), or (3) use TRIBE v2 only for non-commercial research and development phases. This is not a footnote. It is a structural constraint on the application.
2.2 Education
An educational content designer creates explainer videos for a biology course. Their goal is comprehension and retention of factual material. Engagement metrics matter - students must watch the content to learn from it - but the designer’s objective is learning outcomes, not watch time for its own sake.
If Bet 2 holds, the framework would allow the designer to predict which cortical regions activate during each segment of the video. A segment explaining cellular mitosis might predict strong activation in the default mode network - the regions active when a person is relating what they see to their own life, imagining what might happen next, or reflecting inward. This would suggest the segment engages self-referential processing, which published research associates with better memory encoding (Scholz, Chan, the social neuroscientist Emily Falk et al., PNAS Nexus, 2025 - brain activity in mentalizing regions predicted message effectiveness across multiple content domains). Evidence: Strong - peer-reviewed mega-analysis, though the link is to message effectiveness broadly, not to educational comprehension specifically. Alternatively, a segment with dense on-screen text and rapid narration might predict strong activation in Broca’s area (language production and processing) without corresponding default mode network engagement - the student is processing language but not integrating the information with their own understanding.
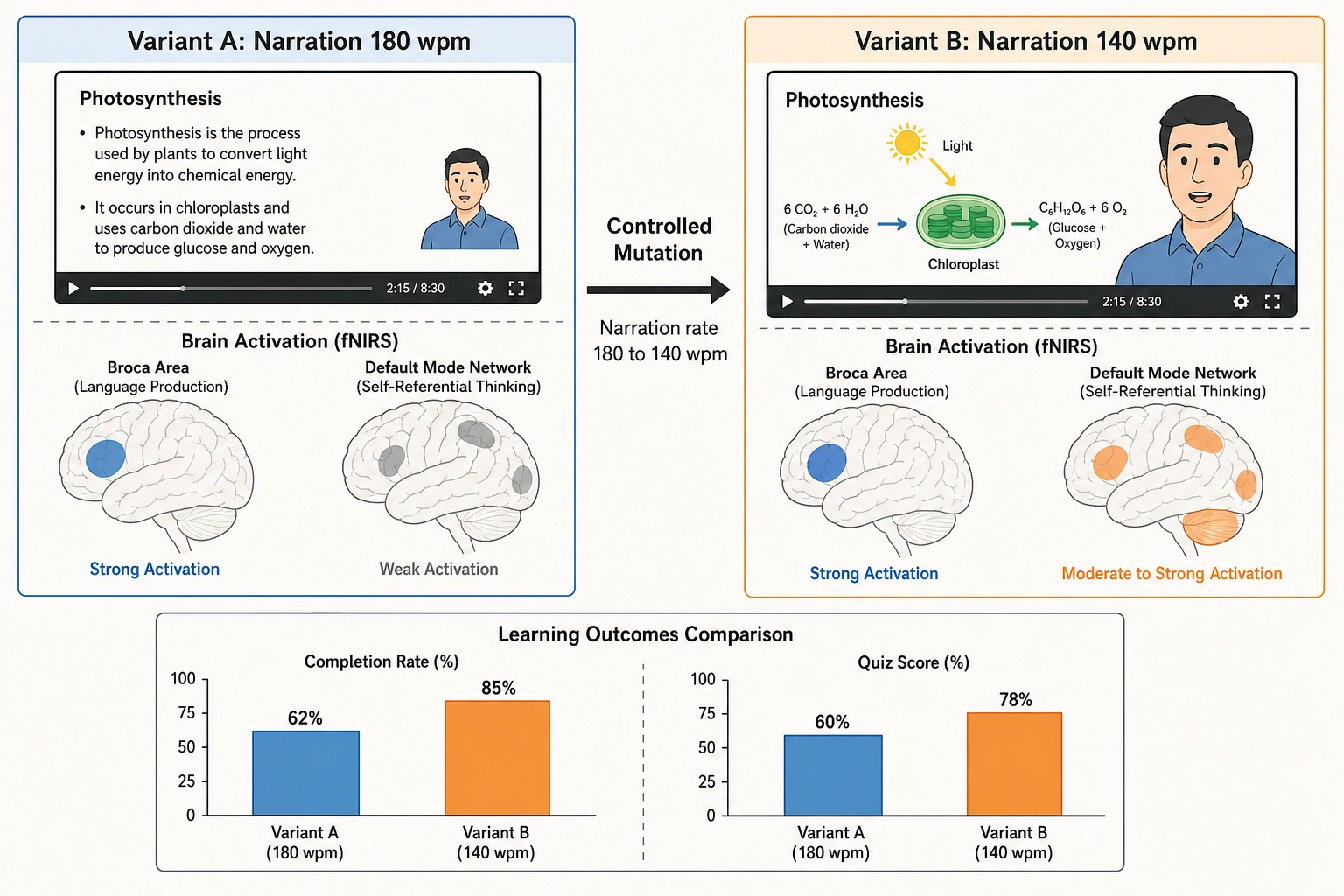
If all three bets hold, the designer could use controlled mutations to test specific hypotheses. Does slowing narration rate from 180 to 140 words per minute change the predicted activation pattern from language-processing-dominant to language-plus-self-referential? Does replacing a static diagram with a 3-second animation shift predicted activation in the superior temporal sulcus - the region involved in processing biological motion? Each mutation would isolate one physical property and measure both the cortical-prediction shift and the behavioral outcome (completion rate, quiz performance if available).
Concrete measurable example: over a semester of producing 30 educational videos with 2-3 controlled variants each (approximately 80 experiments), the designer would accumulate a subject-specific causal graph. They might discover that for their student population, the combination of moderate narration rate (140-150 words per minute), face-to-content area ratio above 20%, and an audio energy envelope that peaks during key concept delivery produces a measurable increase in completion rate and quiz scores compared to variants that lack one or more of these properties. The effect sizes would be modest - educational content optimization operates in a narrow band - but they would compound across a curriculum.
Counter-evidence and limitations. The relationship between engagement (completion rate, watch time) and learning outcomes (comprehension, retention) is not straightforward. the cognitive scientist Kenneth Koedinger and colleagues (2015) found that time-on-task in educational software was a weak predictor of learning gains when motivation and prior knowledge were controlled. Evidence: Strong - peer-reviewed, large-scale study. The framework can optimize for behavioral engagement metrics, but whether engagement-optimized educational content produces better learning outcomes is a separate empirical question the framework does not answer.
2.3 Public health communication
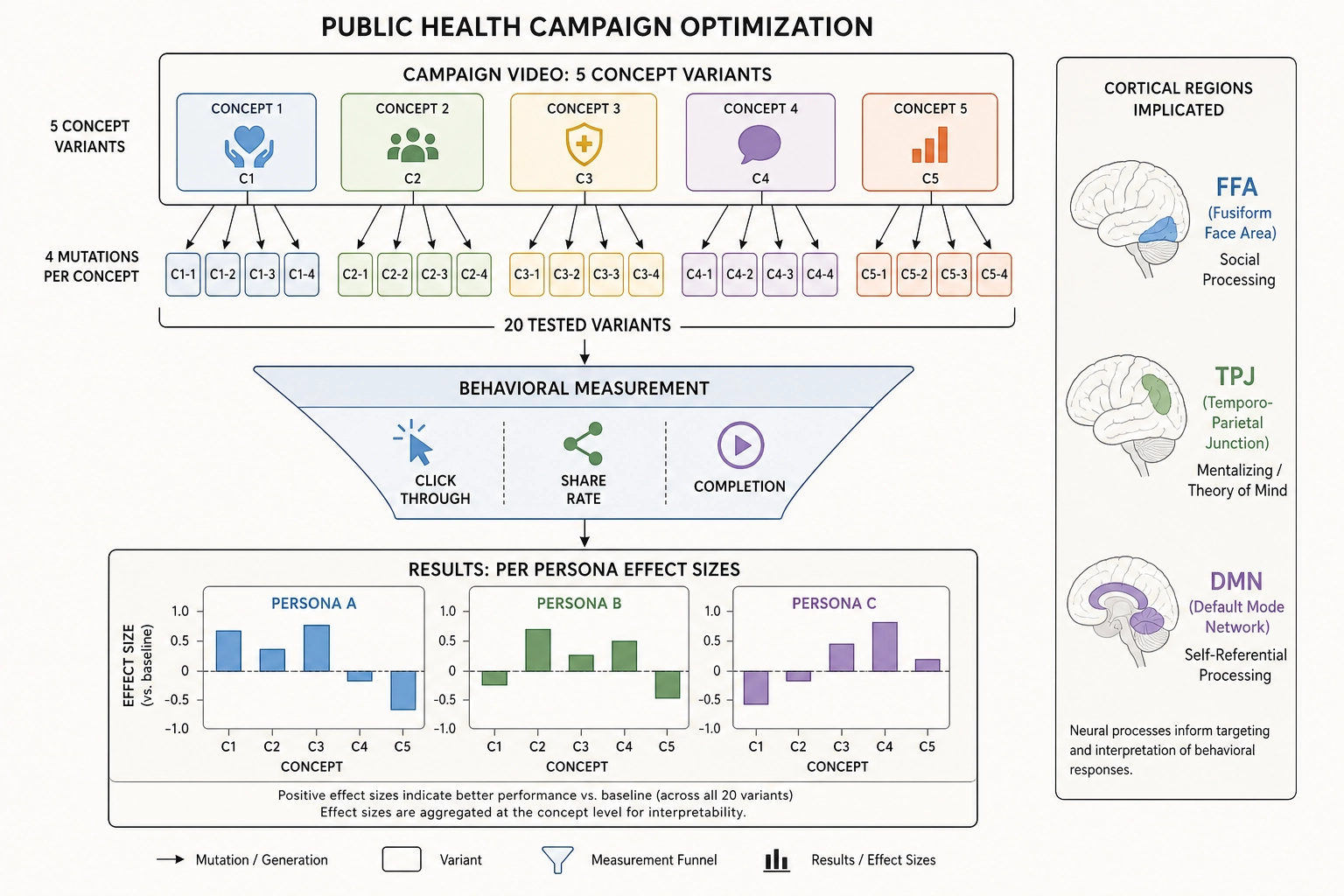
A public health agency designs video campaigns for smoking cessation, vaccination promotion, or mental health awareness. The stakes are high: the audience may encounter the message once, and whether it shifts behavior can have life-or-death consequences.
The published evidence is directly relevant here. Falk, the psychologist Elliot Berkman & Lieberman (2012) found that medial prefrontal cortex activity during anti-smoking ad viewing predicted population-level ad effectiveness better than the participants’ own ratings of the ads. Evidence: Strong - peer-reviewed, replicated across multiple follow-up studies. Scholz, Chan, Falk et al. (PNAS Nexus, 2025) pooled 16 fMRI datasets from 572 participants and found that brain activity in reward and mentalizing regions predicted message effectiveness across public health campaigns, movie trailers, crowdfunding, and YouTube content. Evidence: Strong - peer-reviewed mega-analysis across 16 independent datasets, the largest of its kind as of 2025. These studies used real fMRI scans. If Bet 2 holds - if predicted cortical activation preserves enough of the signal that real scans captured - the framework would bring this predictive capability to public health communicators without scanners, labs, or subjects.
Counter-evidence and limitations. The brain-to-behavior prediction studies cited above measured real fMRI activation, not predicted activation from encoding models. The gap between measured and predicted cortical activation is the gap Bet 2 exists to test. Berkman and Falk (2013) also noted that the neural predictors worked at the population level but showed limited individual-level predictive power - the same limitation the framework inherits through the average-subject constraint (Chapter 11 section 1.3). Additionally, the public health studies focused on North American populations; cross-cultural generalizability of the neural-prediction advantage over self-report has not been established.
If all three bets hold, the framework would allow pre-testing of campaign variants before expensive media buys. A vaccination campaign video might be decomposed, predicted, mutated, and optimized through 10-20 controlled variants, each changing one property: the narrator’s face area, the pacing of testimonial segments, the audio energy profile during the call-to-action, the luminance contrast of the vaccination site imagery. The framework could not predict the subjective emotional response - whether the viewer felt reassured, afraid, or motivated - but it could predict which aspects of perception and emotion the cortical pattern implicates (social processing via FFA, mentalizing via TPJ, self-referential processing via default mode network) and correlate those activations with the behavioral outcome (did the viewer click the scheduling link, share the video, or watch to completion).
Concrete measurable example: a health agency testing 5 campaign concepts with 4 mutations each across 3 audience personas would generate 60 data points in the causal graph within one campaign cycle. If the framework identifies that increasing the testimonial speaker’s face area from 15% to 35% of frame shifts predicted FFA activation by a measurable amount and correlates with a 6-10% increase in click-through to the scheduling page for the primary persona - that finding, if replicated across campaigns, would constitute actionable evidence for public health content design. The agency would know not just that “larger faces work” (semantic-level insight available from any creative intelligence platform) but which cortical mechanism mediates the effect and for which behavioral cluster it holds.
2.4 Journalism
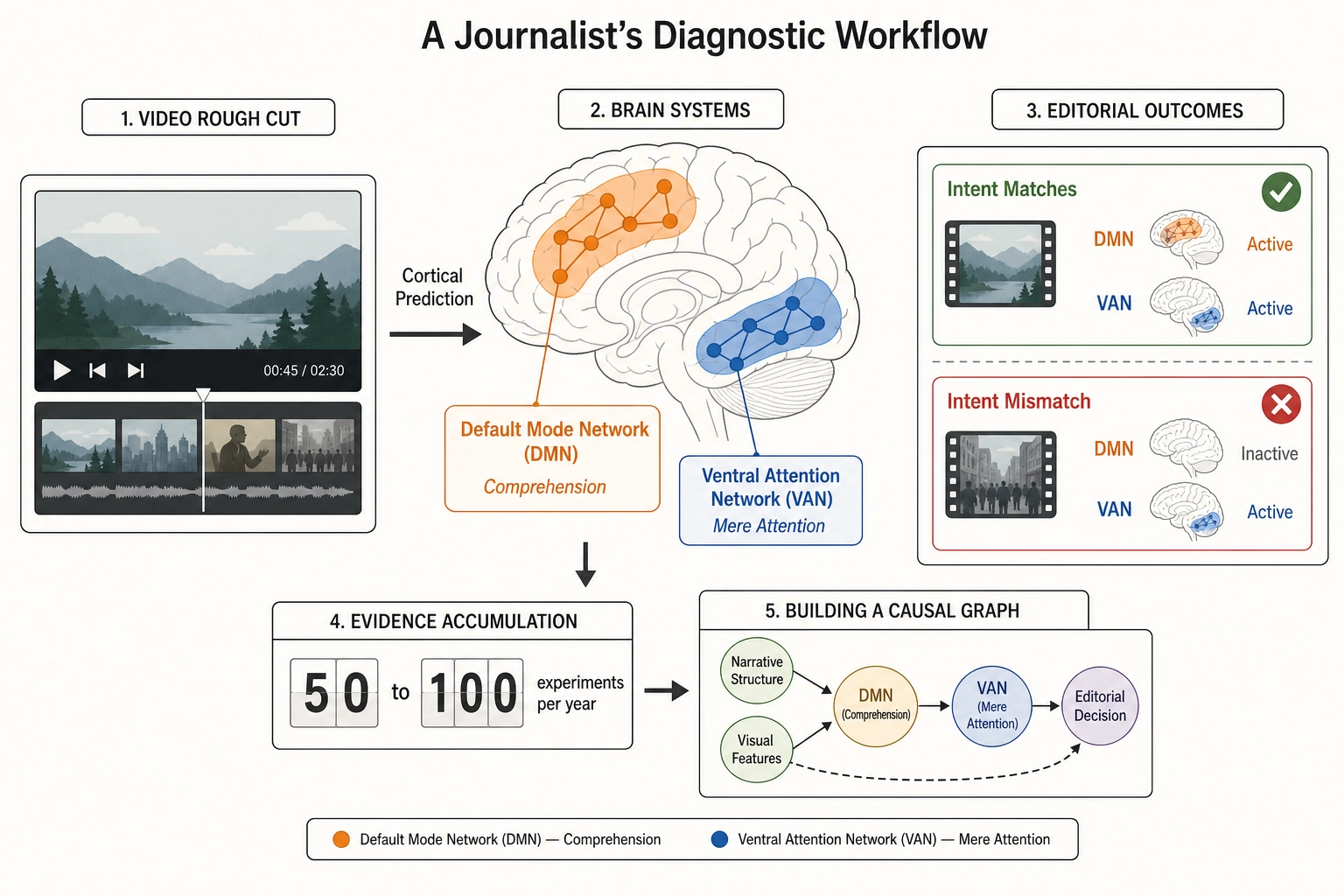
A video journalist produces investigative or explanatory content. Their goal is comprehension, trust, and informed decision-making. They want the viewer to understand a complex issue, not merely to watch longer.
If all three bets hold, the framework would give the journalist a diagnostic tool. After producing a rough cut, they could predict which cortical regions activate during each segment and compare the predicted activation pattern against their editorial intent. A segment designed to present evidence might predict strong default mode network engagement (self-referential processing, integrating new information with existing beliefs) - a good sign for comprehension. The same segment might predict weak temporal parietal junction activation (mentalizing - modeling what other people think and feel) - which might matter if the segment is about the experience of affected individuals and the journalist intended to engage the viewer’s empathy.
The framework could not tell the journalist whether the viewer trusts the content, whether the viewer changed their mind, or whether the viewer felt the issue was presented fairly. These are Scope B phenomena - subjective qualities of the viewer’s experience that the framework cannot access (Chapter 11 section 1.1). But it could tell the journalist which cortical systems the content engages and how strongly, which is diagnostic information the journalist currently lacks entirely.
Concrete measurable example: a journalist producing a weekly 8-minute segment could run 1-2 mutations per episode - adjusting, say, the B-roll cut rate during a statistical explanation or the narrator’s face presence during a witness interview - and accumulate approximately 50-100 experiments per year. Over time, the journalist would discover which physical properties of their content correlate with the behavioral outcomes they care about (completion rate, share rate, comment sentiment) for their specific audience personas.
2.5 Therapy and wellbeing content
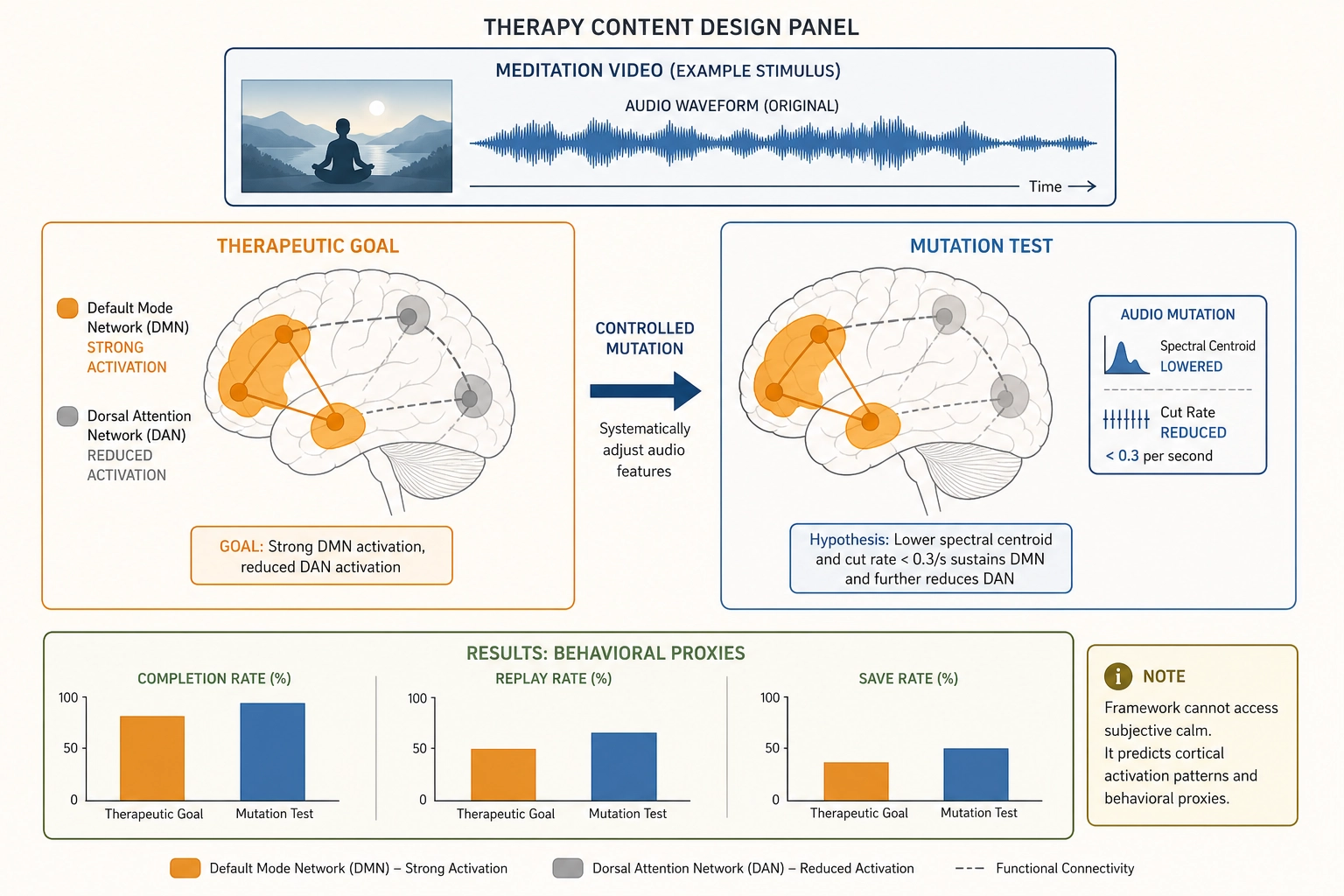
A therapist or wellbeing content creator produces guided meditation, breathing exercises, psychoeducation videos, or therapeutic storytelling. Their goal is to facilitate specific psychological states: calm, safety, emotional regulation, insight.
If Bet 2 holds, the framework’s cortical predictions would be directly relevant. A guided meditation video might predict strong activation in the default mode network during self-reflection prompts and reduced activation in the dorsal attention network - the regions involved in externally directed, goal-oriented attention - during the body-scan segment. This pattern would be consistent with the psychological intent of the exercise (inward-directed attention, reduced external vigilance). A breathing exercise might predict periodic changes in primary auditory cortex activation synchronized with the audio guide’s rhythm.
If all three bets hold, controlled mutations could test whether specific physical properties of the content measurably shift the predicted cortical pattern toward the therapeutic goal. Does lowering audio spectral centroid (shifting the sound toward warmer, lower frequencies) change the predicted activation pattern in a direction consistent with reduced alerting-network engagement? Does slowing the visual cut rate below 0.3 cuts per second sustain the predicted default mode network activation longer than a version with 0.8 cuts per second?
The framework cannot access whether the viewer felt calmer, safer, or more regulated - these are subjective qualities in Scope B. But it can predict which cortical systems are engaged and compare the predicted pattern against published neuroscience on the neural correlates of the target state. A wellbeing content creator with 100 experiments and a growing causal graph would have empirically grounded, persona-specific knowledge about which physical properties of their content correlate with the behavioral outcomes they measure (completion rate, replay rate, save rate - the behavioral proxies for “the viewer found this useful enough to return to”).
2.6 Art
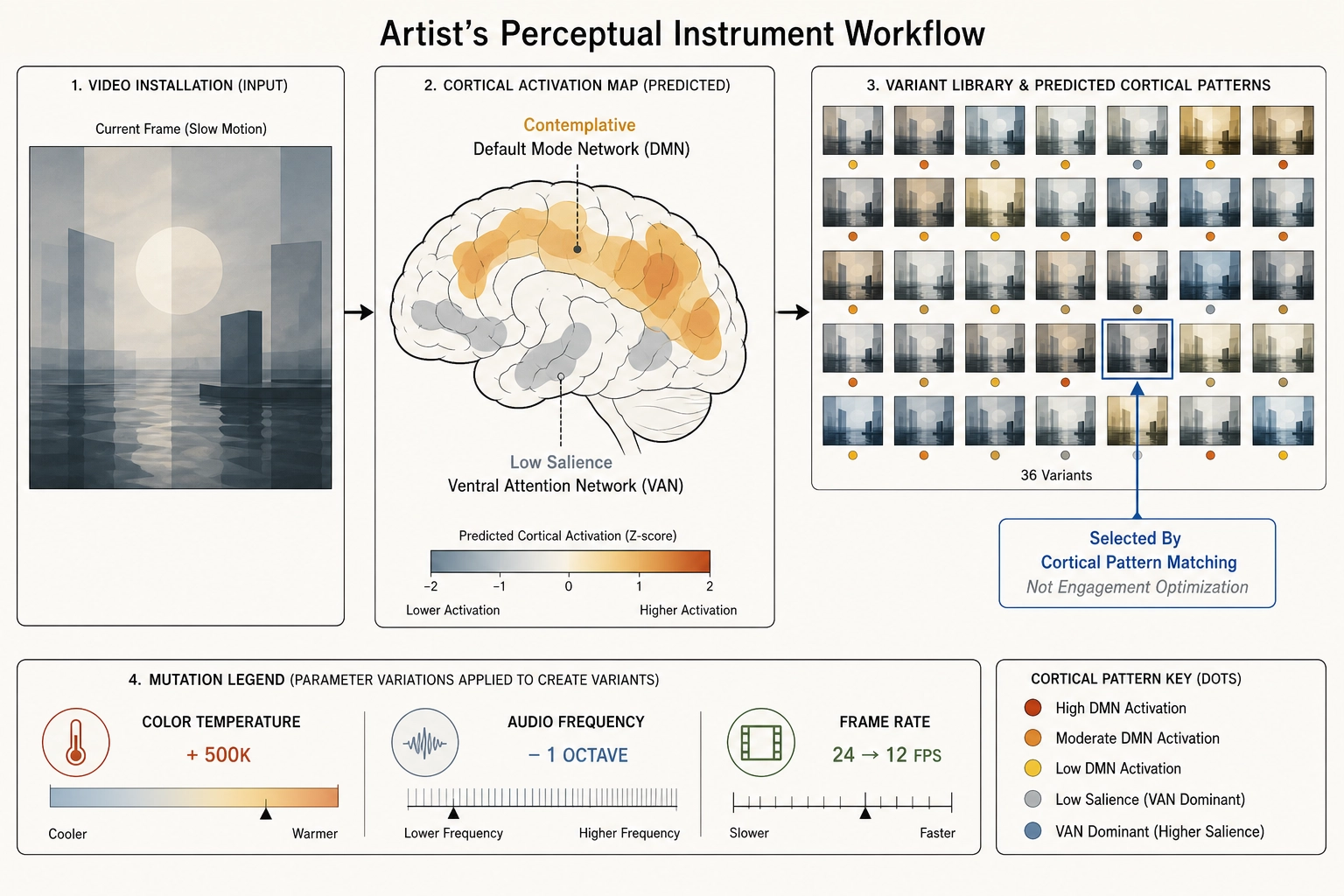
An artist creates video installations, short films, music videos, or experimental visual art. Their goal is aesthetic - they want to create a specific perceptual and emotional experience for the viewer. They are not optimizing for engagement metrics; they are exploring the relationship between physical stimulus properties and the viewer’s response.
If all three bets hold, the framework would give the artist a perceptual instrument - a way to see what their content does at the cortical level. A video installation that uses extreme slow motion, desaturated color, and low-frequency ambient sound might predict a cortical activation pattern dominated by the default mode network and reduced activation in the ventral attention network - the salience system, the regions that flag unexpected stimuli for attention. The artist could see this prediction and decide whether it matches their intent. If they want the viewer to enter a contemplative state, the pattern is consistent. If they want the viewer to experience disorientation, the prediction suggests the content is not achieving that goal at the cortical level, and they could mutate toward it.
The framework makes no aesthetic judgments. It reports which cortical systems the content is predicted to engage and how strongly. Whether the resulting perceptual state is beautiful, disturbing, profound, or boring is a subjective quality the framework cannot access. The artist interprets the cortical map through their own aesthetic framework - the Khozai framework provides the map, not the meaning.
Concrete measurable example: an artist preparing a gallery installation could test 30-40 variants of a 3-minute video loop, each mutating one physical property (color temperature shift by 500K, audio fundamental frequency lowered by one octave, frame rate halved from 24 to 12 fps). Each variant would produce a different predicted cortical activation pattern. The artist would select variants not by engagement optimization but by cortical-pattern matching - choosing the variant whose predicted activation pattern most closely matches the experiential state they intend to create, as interpreted through published neuroscience on the cortical correlates of that state.
2.7 Research
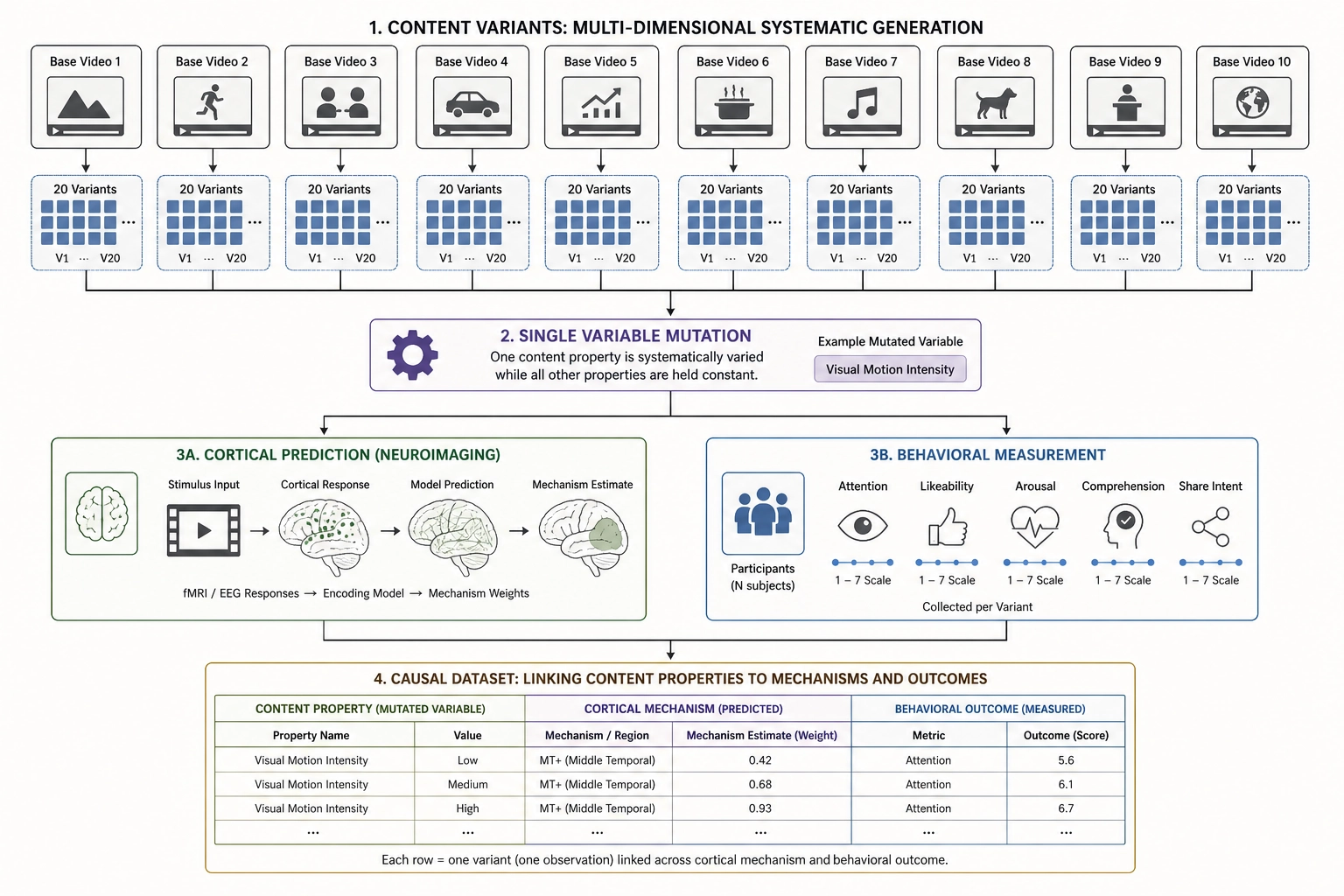
A researcher in media psychology, communication science, or consumer neuroscience studies how content properties affect viewer response. Their goal is to produce publishable, reproducible findings.
If Bet 2 holds, the framework would provide a research tool that substitutes for expensive fMRI studies in the hypothesis-generation phase. A researcher could test 50 content variants against TRIBE v2’s cortical predictions in a day - work that would require months of scanner time with human subjects. The predicted activation patterns would generate hypotheses about which content properties drive which neural responses, and those hypotheses could then be confirmed with targeted fMRI studies using far fewer variants.
If all three bets hold, the full pipeline - physics-level decomposition, cortical prediction, controlled mutation, behavioral measurement, neuroscience-grounded correlation - would constitute a new methodological tool for the field. The controlled-mutation workflow provides causal identification by design (Chapter 8 section 3): if a single content property is changed and a behavioral outcome shifts, the causal inference is straightforward. This is stronger than the observational correlations most media-effects research relies on.
Concrete measurable example: a researcher studying how visual complexity affects narrative comprehension could generate 200 variants of 10 base videos, each with controlled changes to spatial frequency energy, cut rate, on-screen text density, and face area. The mutation engine would ensure each variant differs from its reference on exactly one property. TRIBE v2 would predict the cortical activation pattern for each variant. After publishing the variants as paid ads with equal budget per variant (Chapter 7 section 5), the researcher would have a dataset of 200 content-property-to-behavioral-outcome mappings, each with a clean causal interpretation and a neuroscience-grounded mechanism. The license constraint (CC BY-NC 4.0) is aligned with non-commercial academic research use; this is the application where the license poses the least friction.
3. Bad-Intention Applications
The applications in this section assume an operator whose goal is to exploit, deceive, addict, or harm the viewer. The operator uses the same framework outputs - which aspects of the viewer’s perception and emotion are involved, how strongly, and how independently - to make content that serves the operator’s interests at the viewer’s expense.
Every application below uses the same mechanisms described in section 2. The physics-level decomposition is the same. The cortical prediction is the same. The mutation engine is the same. The correlation engine is the same. The persona specification is the same. The only difference is the operator’s intent and the outcome they optimize for.
3.1 Addiction engineering
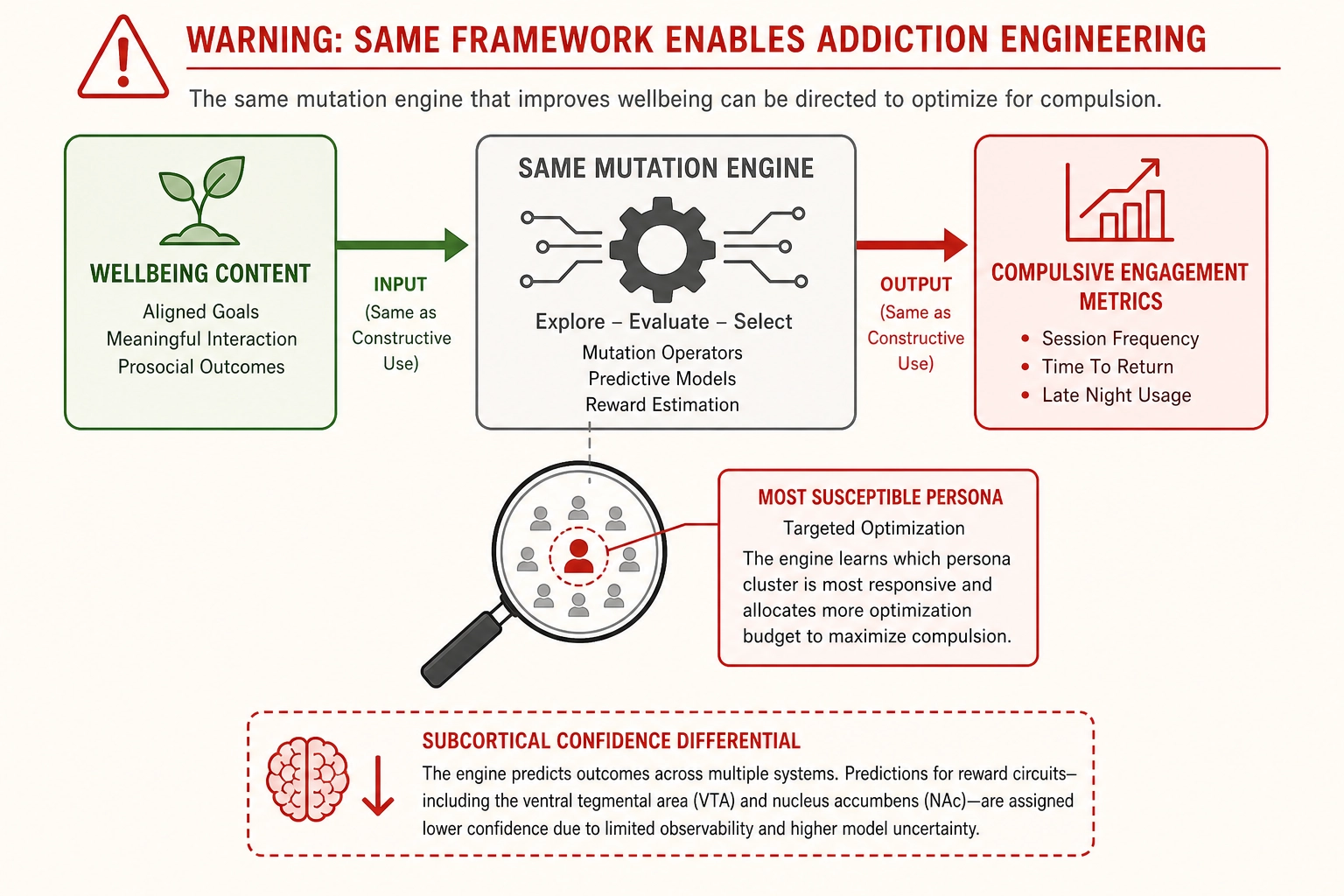
A mobile game company or social media platform designs content to maximize compulsive engagement - not the viewer’s satisfaction, not the viewer’s wellbeing, but the raw frequency and duration of return visits.
If all three bets hold, the framework would provide a systematic method for identifying which physical properties of content stimuli drive compulsive re-engagement for specific behavioral personas. The mutation engine would generate controlled variants of notification visuals, loading screens, reward animations, and in-app video content. The correlation engine would map each physical property to the behavioral outcomes that index compulsive use: session frequency, session duration, time-to-return after closing the app, late-night usage rates.
The persona specification is particularly dangerous here. The never-collapse-across-personas rule (Phase 9 section 4) was designed to prevent opposing effects from masking each other. In a good-intention context, this prevents a public health communicator from missing that their campaign works for one group and backfires for another. In an addiction-engineering context, it enables the operator to identify the persona cluster most susceptible to compulsive engagement and target them specifically. A mutation that increases session frequency by 20% for the most susceptible persona while having no effect on others is not an ethical outcome - it is selective exploitation of vulnerability.
Concrete measurable example: an operator running 500 mutation experiments across a gaming app’s reward animations could discover that for persona cluster 3 (characterized by high replay rate, late-night session times, and high save-rate engagement), shifting the reward animation’s color temperature by 800K toward warm, increasing the animation’s audio onset sharpness by 12 dB, and extending the visual duration from 1.2 to 2.4 seconds increases time-to-next-session by -15% (the user returns sooner) with a confidence interval narrow enough to act on. The framework would report this as a measurable finding. Whether the operator uses it is not a question the framework answers.
The subcortical confidence differential (Chapter 11 section 1.2) partially constrains this application. Reward processing - the ventral tegmental area, nucleus accumbens, and dopamine pathways that drive wanting and incentive salience - is subcortical and predicted by Khozai at lower confidence than cortical regions, inheriting the fMRI signal-quality limitations assessed in Chapter 3. Evidence: Moderate - the subcortical signal-quality limitation is established in the neuroimaging literature (Murphy et al., 2007; Ojemann et al., 1997), but the degree to which encoding-model predictions degrade for subcortical regions specifically has not been benchmarked. The most direct neural substrate of addiction is not absent from the framework’s predictions but carries a confidence gap that makes those predictions less reliable. The cortical components of the same reward circuits - medial prefrontal cortex, anterior cingulate cortex, anterior insula - are predicted at higher confidence, and the combination of higher-confidence cortical and lower-confidence subcortical predictions provides broader coverage than either alone. The constraint is real but it is a confidence differential, not a blind spot.
Counter-evidence and limitations. The scenario above assumes that the mutation engine can isolate stimulus properties that drive compulsive engagement. However, addiction research suggests that compulsive behavior depends heavily on context, individual vulnerability, and reinforcement schedules - not just stimulus properties (the psychologist Mark Griffiths, 2005; the cyberpsychologist Daria Kuss & Griffiths, 2012). Evidence: Strong - peer-reviewed, replicated across behavioral addiction studies. The framework’s ability to manipulate compulsive engagement through physics-level content properties alone may be substantially more limited than the scenario implies.
3.2 Political manipulation
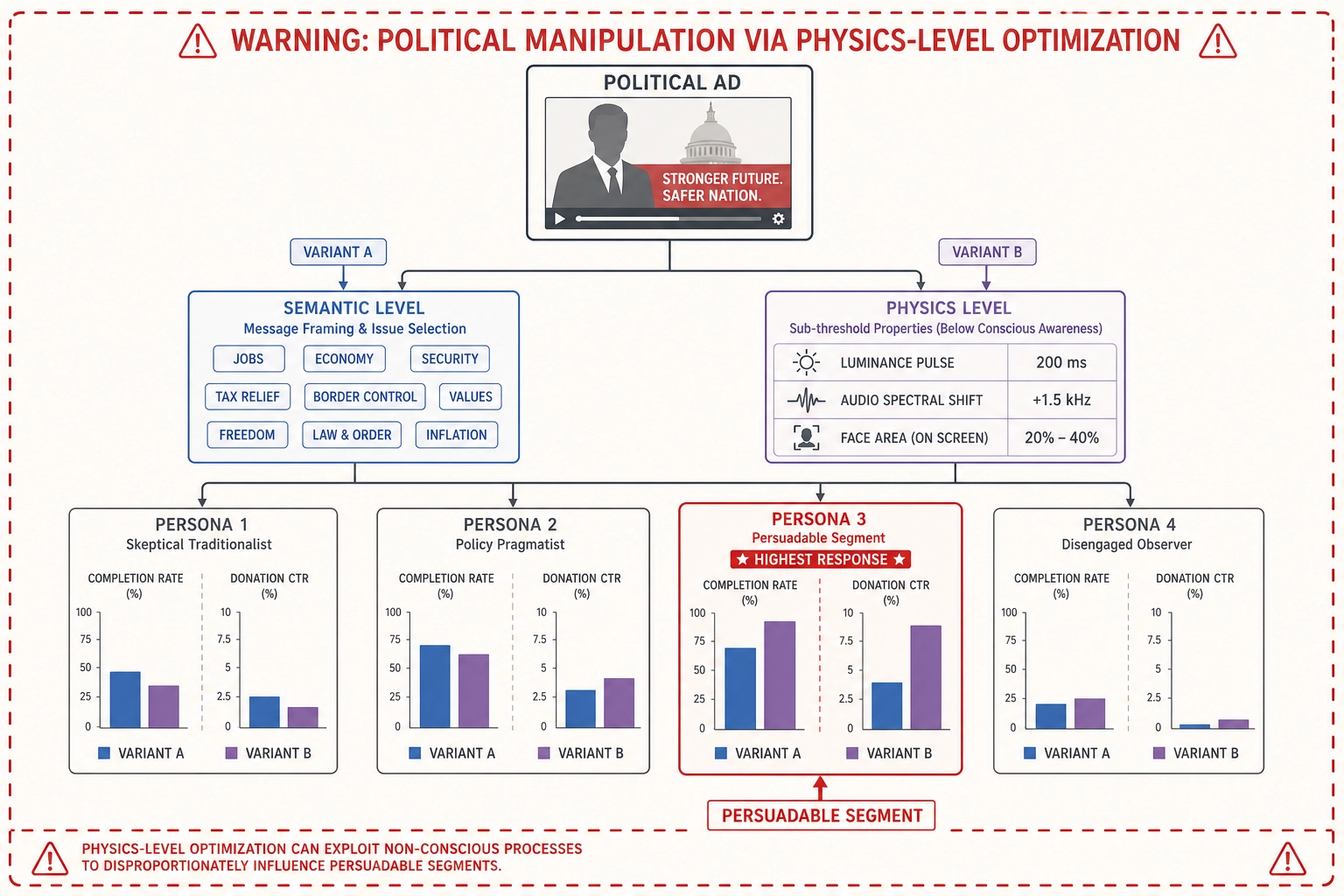
A political campaign or state-sponsored influence operation designs propaganda content optimized for belief change, emotional polarization, or voter suppression.
If all three bets hold, the framework would enable systematic optimization of political content at the physics level - below the threshold of what viewers consciously notice. Current political ad optimization operates at the semantic level: message framing, candidate imagery, issue selection, emotional tone. The framework would go deeper. The framework would hypothesize that a 200-millisecond subliminal luminance increase during the opponent’s name on screen could produce a measurable shift in predicted alerting-network activation. Does shifting the audio spectral balance of a narrator’s voice toward lower frequencies change the predicted activation pattern in regions associated with trust and credibility assessment? Does increasing the face area of “people like you” testimonial subjects from 20% to 40% of frame produce a measurable increase in default mode network engagement (self-referential processing - the viewer relating the testimonial to their own life)?
The persona specification makes this worse. Political audiences are not homogeneous. A message that increases persuasion for one persona may trigger reactance in another. The framework’s per-persona effect sizes would allow a campaign to design different physical variants of the same political message, optimized for different behavioral clusters, and deploy them through the ad platforms’ existing targeting infrastructure. This is not hypothetical capability - the ad platforms already support variant-level targeting. The framework would add the physics-level optimization layer on top of the targeting the platforms already provide.
Concrete measurable example: a campaign running 300 mutation experiments on 15 base political ads across 4 personas could discover that for persona 2 (characterized by high completion rate, low share rate, and high save rate), reducing the cut rate during the opponent-criticism segment from 2.0 to 0.8 cuts per second and increasing the narrator’s face area from 15% to 45% of frame produces a 9% increase in completion rate and a 14% increase in click-through to the donation page. The cortical interpretation: slower pacing sustains default mode network engagement (self-referential processing), and larger face area increases fusiform face area and temporal parietal junction activation (social processing and mentalizing). The campaign would have a neuroscience-grounded explanation for why the manipulation works, not just a statistical correlation.
3.3 Children’s content exploitation
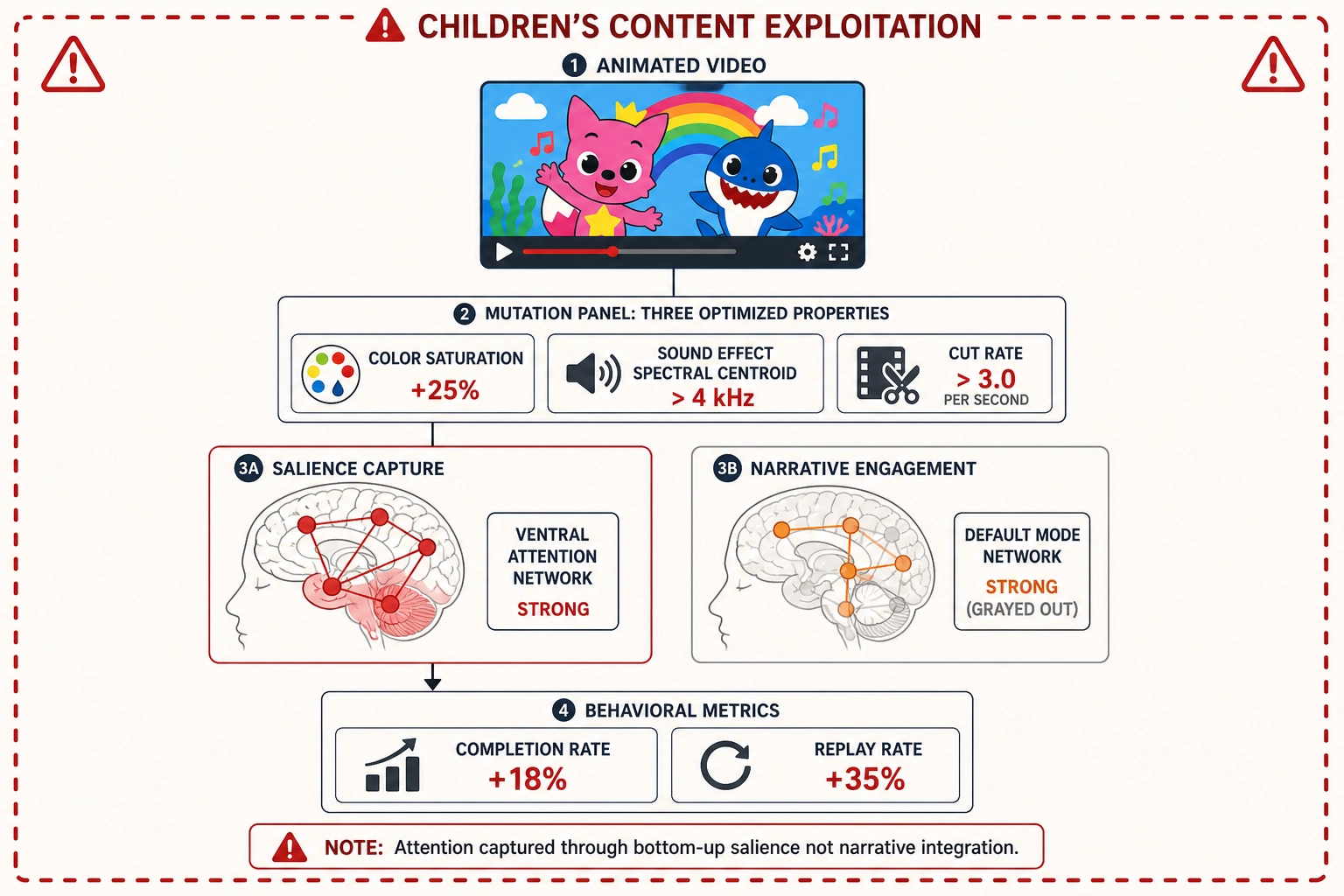
A children’s content producer designs videos optimized to maximize watch time in young viewers - not for educational value, not for developmental benefit, but for ad revenue generated by sustained viewing.
If all three bets hold, the framework would enable physics-level optimization of children’s content for compulsive engagement. The mutation engine would test which specific physical properties - color saturation levels, animation speed, sound effect onset sharpness, face area of animated characters, cut rate during action sequences - produce the highest retention rates in the target audience. The behavioral measurements (Vₚ) would capture watch duration, replay rate, and completion rate. The cortical predictions would identify which processing systems are engaged.
This application is particularly harmful because children’s developing brains are more susceptible to stimulus-driven attention capture, less capable of voluntary disengagement, and more vulnerable to habit formation from repeated exposure. The framework does not model developmental differences - TRIBE v2 predicts the average adult subject’s cortical activation, and Khozai v1 cannot predict individual or developmental variation (Chapter 11 section 1.3). But the behavioral measurements (Vₚ) would capture children’s actual engagement patterns, and the per-persona causal graph would accumulate effect sizes specific to the children’s-content audience, regardless of whether the cortical prediction accurately represents a child’s brain.
Concrete measurable example: an operator running 400 experiments on animated children’s content could discover that for their primary audience persona, increasing color saturation by 25% in the first 3 seconds, adding a high-frequency sound effect (spectral centroid above 4 kHz) at the 0.5-second mark, and maintaining a cut rate above 3.0 cuts per second throughout produces a completion rate 18% higher than baseline and a replay rate 35% higher. The operator would not need to understand the neuroscience - the behavioral measurements alone would guide optimization. But the cortical predictions would add a diagnostic layer: the framework might predict strong activation in the ventral attention network (salience processing - the system that detects and orients to unexpected stimuli) and weak activation in the default mode network (self-referential processing, narrative integration), suggesting the content captures attention through bottom-up salience rather than narrative engagement. A framework that reports this pattern without flagging the ethical implication is doing its job as described - it is ethically neutral. The ethical judgment belongs to the operator, and in this case the operator is exploiting it.
3.4 Financial exploitation

A financial services company or cryptocurrency promoter designs marketing content optimized to drive investment decisions - not informed decisions, but impulsive ones that benefit the promoter at the investor’s expense.
If all three bets hold, the framework would allow physics-level optimization of financial marketing for urgency, social proof, and reduced deliberation. The mutation engine could test whether specific physical properties - accelerating cut rate during the “limited time” segment, increasing the face area and direct-gaze duration of the endorser, shifting the audio energy envelope to create a rising intensity pattern - measurably increase click-through to the investment page.
The persona specification is dangerous in this context for the same reason it is dangerous in addiction engineering: it enables identification of the most susceptible behavioral cluster. A persona characterized by high impulsive engagement (fast click-through, short deliberation time between impression and action) could be targeted with content variants optimized specifically for their response pattern.
Concrete measurable example: a crypto promoter testing 200 variants of a “limited opportunity” video could discover that for their most impulsive persona cluster, reducing the deliberation gap (the silent pause before the call-to-action) from 2.0 seconds to 0.3 seconds, increasing the audio loudness contour by 6 LUFS during the final 5 seconds, and displaying the endorser’s face at 50% of frame during the CTA produces a 22% increase in click-through to the investment page. The cortical interpretation might implicate stronger fusiform face area activation (social trust processing) and stronger Broca’s area engagement (language urgency processing). The framework reports the finding. The framework does not ask whether the investment is legitimate.
3.5 Deepfake enhancement
A bad actor creates deepfake videos - synthetic content designed to be mistaken for authentic footage of real people saying or doing things they never said or did. The deepfake itself is produced by other tools (face-swapping models, voice cloning systems). Khozai’s contribution would be at the optimization layer: making the deepfake more convincing and more engaging.
If all three bets hold, the framework would allow the bad actor to optimize the deepfake’s physical properties for perceived authenticity and engagement simultaneously. The framework would predict that the mutation engine could test variants with adjusted skin luminance consistency (matching the face’s luminance statistics to the body’s), audio-visual synchrony refinement (ensuring the spectral characteristics of the cloned voice match the predicted auditory cortex activation pattern of natural speech), and lighting-direction consistency (adjusting shadow angles to match the scene’s global illuminance). Each mutation would target a specific physical property that human perceptual systems use to detect fakery - and the cortical prediction would indicate whether the adjustment reduces the predicted activation pattern associated with incongruity detection.
Concrete measurable example: a deepfake producer testing 100 variants of a fabricated political speech could use the framework to identify that the current version predicts an anomalous activation pattern in the superior temporal sulcus - the region involved in processing audio-visual speech integration - suggesting perceptual incongruity that might trigger viewer suspicion. Mutations adjusting the audio spectral envelope to match the original speaker’s voice characteristics and adjusting the lip-movement timing by 40 milliseconds might shift the predicted STS activation toward the pattern predicted for authentic speech. The framework would report this as a reduction in predicted perceptual incongruity. Whether this constitutes fraud, election interference, or criminal impersonation depends on the context and jurisdiction - not on the framework.
3.6 Corporate manipulation of employees and consumers
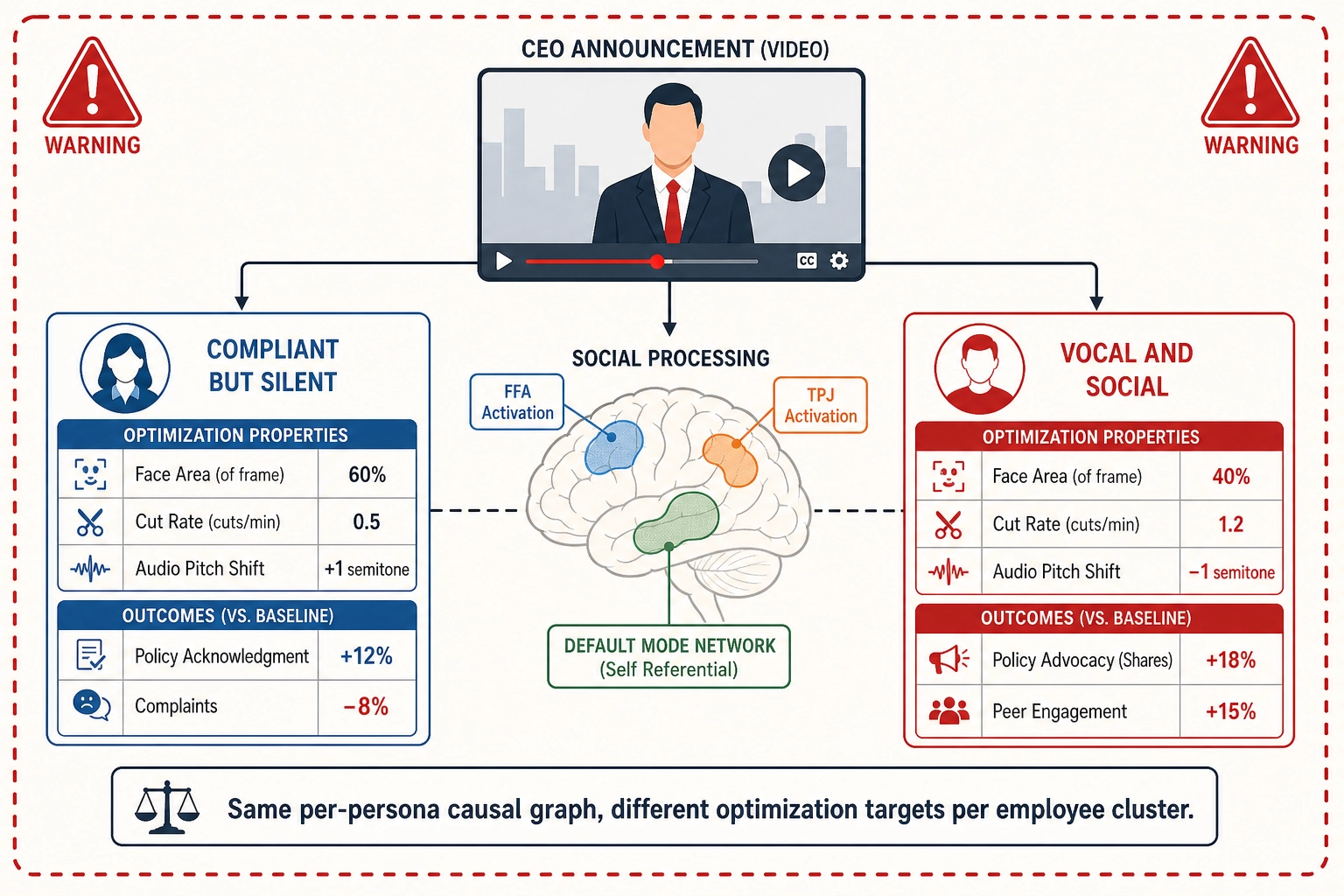
A corporation uses the framework to optimize internal communications, training videos, and consumer marketing - not for clarity or employee wellbeing, but for compliance, reduced dissent, and increased consumption.
If all three bets hold, the framework would allow a corporation to design internal communications that measurably increase compliance with unpopular policies. The framework’s measurement vectors suggest that the mutation engine could test whether specific physical properties of a CEO announcement video - face area, gaze direction, audio pitch, pacing, background luminance - correlate with the behavioral outcomes the corporation cares about: reduced complaint-ticket volume, increased policy-acknowledgment click-through, shorter time-to-compliance.
The persona specification would reveal which employee behavioral clusters respond to which optimization strategies. An employee persona characterized by high engagement with company content but low share rate and low comment rate - the “compliant but silent” cluster - might respond to different physical properties than a persona characterized by high comment rate and high share rate - the “vocal and social” cluster. Optimizing for compliance in the first group and for advocacy in the second group, using different physical variants of the same message, is a straightforward application of the per-persona causal graph.
Concrete measurable example: a corporation testing 150 variants of quarterly earnings communications could discover that for the “compliant but silent” employee persona, increasing the CEO’s face area to 60% of frame, reducing the cut rate to 0.5 cuts per second during the bad-news segment, and raising the audio fundamental frequency by a semitone during the outlook segment produces a 12% increase in policy-acknowledgment click-through and a 8% decrease in complaint-ticket volume within 48 hours. The cortical interpretation might implicate stronger FFA and TPJ activation (social processing and mentalizing - the employee is processing the CEO as a person, not as a source of bad news) and sustained default mode network engagement (self-referential processing - the employee is relating the message to their own situation). The framework reports the finding. The corporation decides whether compliance-optimized communication is ethical.
4. The Dual-Use Comparison
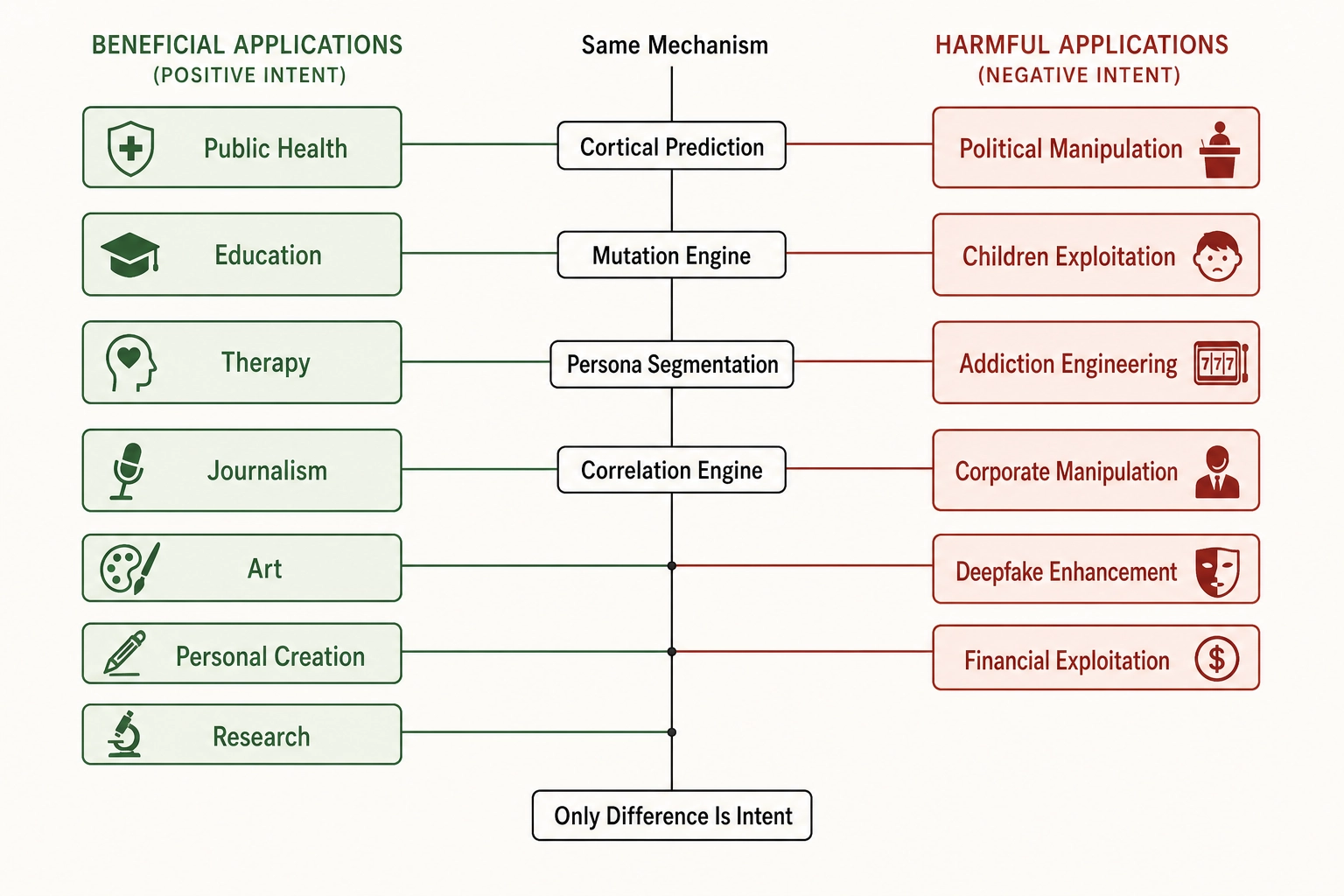
The applications in section 2 and section 3 are not different technologies. They are the same technology applied with different intent. The table below makes the parallel explicit.
| Good-intention application | Bad-intention mirror | Same mechanism | Same framework output |
|---|---|---|---|
| Public health: optimize anti-smoking campaign for message effectiveness | Political manipulation: optimize propaganda for belief change | Cortical prediction of which processing systems the content engages; mutation to shift that pattern | Per-persona effect sizes on behavioral outcomes |
| Education: optimize explainer video for comprehension and retention | Children’s exploitation: optimize children’s content for compulsive watch time | Mutation of pacing, face area, audio properties to shift cortical engagement pattern | Correlation of physical properties with completion rate and replay rate |
| Therapy/wellbeing: design content to facilitate calm and emotional regulation | Addiction engineering: design content to maximize compulsive re-engagement | Prediction of which cortical systems are engaged; optimization of physical properties to shift that pattern | Persona-specific behavioral response mapping |
| Journalism: diagnose whether content engages comprehension vs. mere attention | Corporate manipulation: optimize communications for compliance without comprehension | Default mode network vs. ventral attention network balance in predicted activation | Correlation of cut rate, face area, and audio properties with downstream behavior |
| Art: explore relationship between stimulus properties and perceptual experience | Deepfake enhancement: optimize synthetic content for perceived authenticity | Physics-level measurement of properties that perceptual systems use for authenticity assessment | Predicted cortical activation pattern in speech and face processing regions |
| Personal content creation: build empirical knowledge of what works for your audience | Financial exploitation: optimize marketing for impulsive action | Per-persona causal graph mapping content properties to behavioral outcomes | Mutation engine, correlation engine, persona-specific effect sizes |
| Research: generate hypotheses and causal evidence for media effects | All of the above: weaponize the same causal evidence | Controlled mutation as causal identification; TRIBE v2 cortical prediction as mechanism layer | The entire framework |
The table makes a point that prose obscures: the mechanism column and the framework-output column are identical across every row. The only column that differs is intent.
5. Persona Dependency
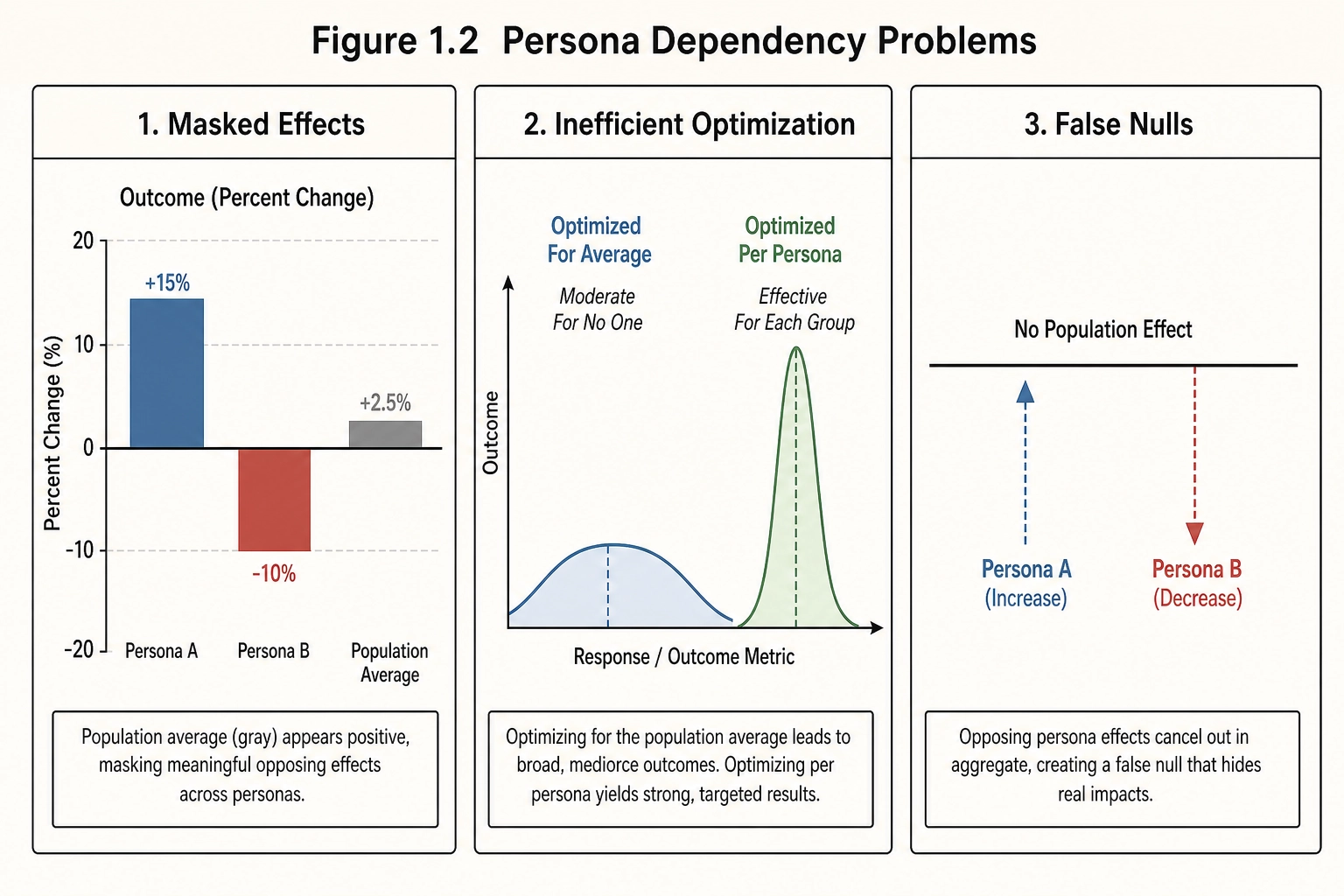
Many of the applications described above - both good and bad - depend on persona-specific effect sizes. Without the persona layer, the framework operates at the population level, which introduces three problems.
Problem 1: Masked effects. A mutation that increases retention by 15% for one persona and decreases it by 10% for another produces a population-average effect of approximately +2-3% (depending on persona sizes). The population average is real but misleading - it understates the effect for the first group and masks the negative effect for the second. The public health communicator misses that their campaign backfires for a subpopulation. The addiction engineer misses that their optimization is even more effective for the vulnerable subgroup than the average suggests.
Problem 2: Inefficient optimization. Optimizing for the population average produces content that is moderately effective for no one rather than highly effective for a specific group. The educational content designer produces videos that are slightly better for all students rather than substantially better for the students who need it most. The political manipulator produces propaganda that shifts opinion slightly across the electorate rather than substantially in the persuadable segment.
Problem 3: False nulls. When opposing effects cancel at the population level, the correlation engine reports no effect. The researcher concludes that cut rate does not affect retention. The actual finding - that cut rate increases retention for one behavioral cluster and decreases it for another - is invisible without persona segmentation. The never-collapse-across-personas rule (Phase 9 section 4) was designed specifically to prevent this.
The persona specification (Phase 9) defines personas as behavioral clusters discovered by Gaussian Mixture Model clustering (a statistical method for finding natural groupings in data) on a PCA-reduced feature space (a compressed representation of the behavioral measurements that preserves the most important variation) of Vₚ metrics and self-report features. Personas are properties of viewer-content response records, not properties of people - the same individual may appear in different persona clusters on different content. This is consistent with Chapter 1 section 12: the hardware is universal, the response is individual, and the response varies across contexts.
For the applications in this chapter, the practical implication is: the framework’s utility scales with persona resolution. A framework that treats all viewers as one population captures only a fraction of the actionable signal. A framework that distinguishes 3-5 behavioral personas captures substantially more. The Phase 9 specification’s BIC-based cluster-count selection, capped at K = 15, balances resolution against the practical constraint that each additional persona multiplies the minimum experiment size (Phase 9 section 5.4).
6. What the Framework Does Not Decide
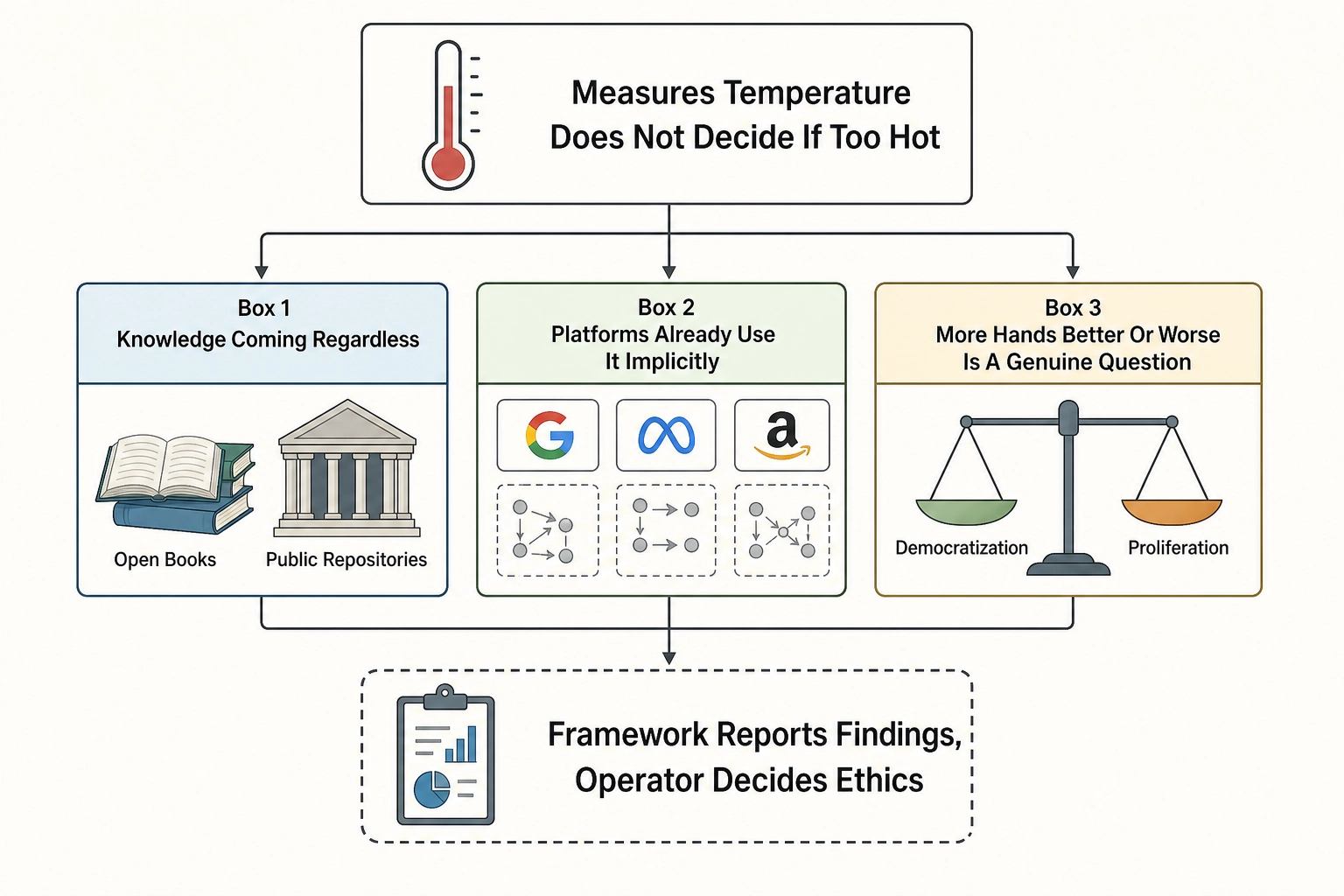
The framework is ethically neutral in the abstract (Chapter 11 section 5). It describes mechanisms - how physical stimulus properties map to cortical activation, how cortical activation maps to behavioral output, how controlled mutations of stimulus properties produce measurable changes in behavior. The mechanisms are properties of the physical world and the biological systems that process it. The neutrality is a design feature, not a design flaw - a thermometer measures temperature without deciding whether the temperature is too high. But the neutrality is also not a shield: the applications in section 3 are concrete workflows that the framework’s specifications would support.
Three observations frame the dual-use reality honestly.
First: the knowledge is coming regardless. The mechanisms described in this book are published neuroscience facts, open-source engineering tools, and publicly available models. TRIBE v2 is on GitHub under CC BY-NC 4.0. The academic studies linking brain activation to content performance are in peer-reviewed journals. Anyone with the technical capacity to integrate them can build a version of what this book describes.
Second: the platforms already use it implicitly. Meta’s Andromeda system, TikTok’s Monolith architecture, and YouTube’s Gemini-based content analysis already decompose content at a level of detail they do not share with creators. Evidence: Moderate - platform architectures are described in published engineering papers (Liu et al., 2022 for Monolith; Meta Engineering Blog, 2024 for Andromeda), but what these systems actually optimize for in production is proprietary and unverifiable. Khozai’s contribution is not inventing the capability but making a version of the understanding explicit and accessible to people outside the platforms.
Third: whether explicit knowledge in more hands is better or worse is a genuine question. The democratization argument says: giving creators and researchers this knowledge levels the playing field and enables informed consent. The proliferation argument says: every additional person with this knowledge is an additional potential bad actor. Both arguments have merit. The author does not resolve the question in this book because the author does not know the answer.
Counter-evidence to the “knowledge is coming regardless” framing. The integration of neuroscience prediction with content optimization at production scale has not been demonstrated by anyone, including the platforms. The claim that platforms “already use it implicitly” conflates algorithmic content matching (demonstrated) with neuroscience-grounded stimulus optimization (not demonstrated). It is possible that the integration this book describes is harder than the components suggest, and that the knowledge remains fragmented across disciplines for longer than the chapter assumes.
7. The Speculation Boundary
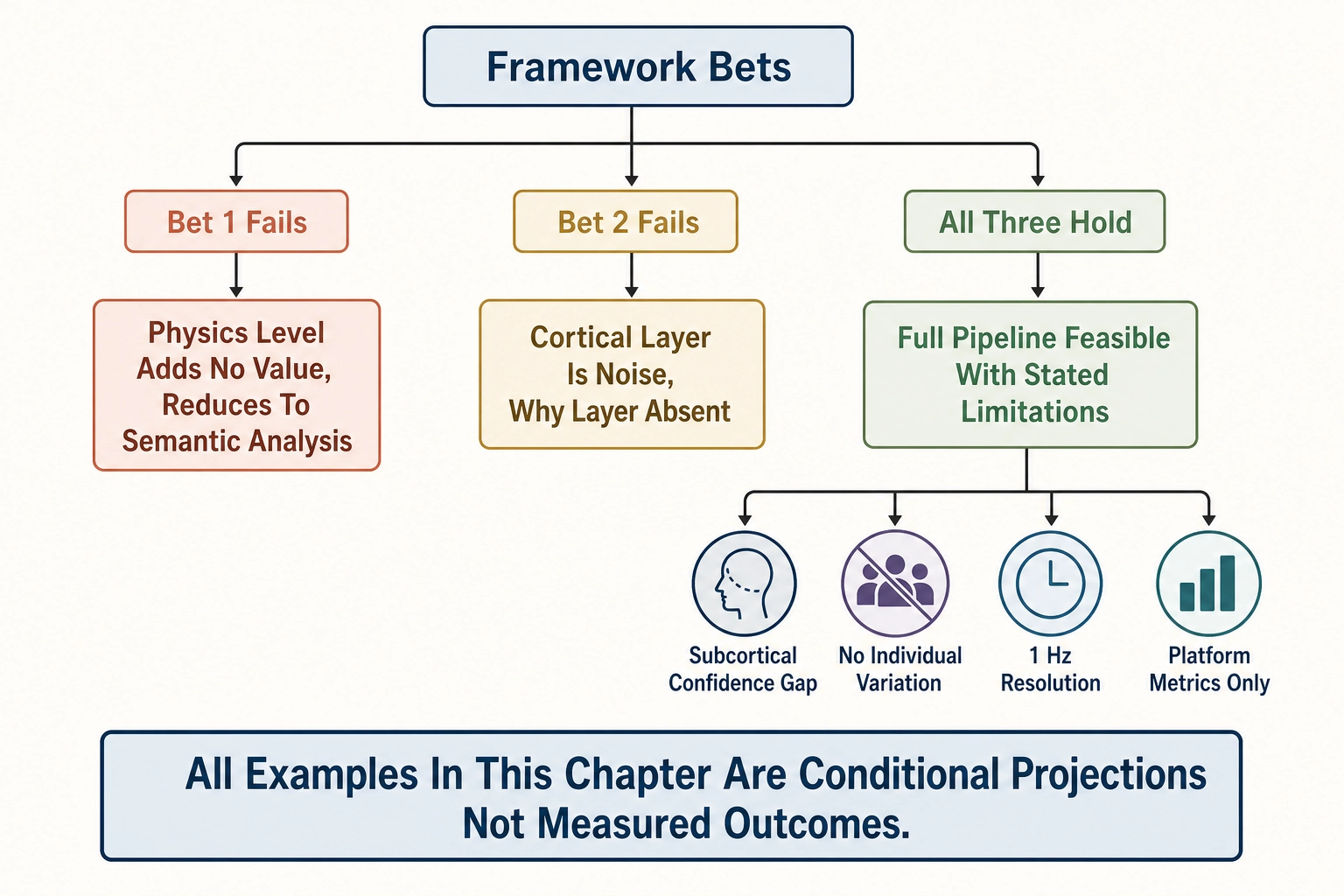
Every application in this chapter is conditional. The conditions are:
If Bet 1 holds - physics-level content properties add predictive value beyond semantic-level. If Bet 1 fails, the physics-level decomposition (V₀, V₁, V₂) adds no value, and most of the concrete examples above reduce to semantic-level creative analysis that the existing 50+ creative intelligence platforms already provide. The cortical prediction layer (Vₙ) may still add value via Bet 2, but the physics-level specificity - “increase face area from 8% to 30% of frame” rather than “add a larger face” - disappears.
If Bet 2 holds - predicted brain activation carries enough signal to predict content performance. If Bet 2 fails, the cortical prediction layer is noise, and the neuroscience-grounded interpretation that distinguishes many of these applications from existing tools - “the cortical mechanism is stronger FFA activation leading to stronger social-processing engagement” - collapses. The framework would still have physics-level measurement (V₀/V₁/V₂), cognitive approximation (Vc), and behavioral measurement (Vₚ), but the “why” layer would be absent.
If all three bets fail, the framework reduces to what 50+ companies already do - semantic-level creative analysis correlated with behavioral outcomes - with a different analytical architecture but no new capability.
If all three bets hold, the applications described in this chapter become feasible as described, subject to the structural limitations stated in Chapter 11: lower-confidence subcortical prediction (the reward, arousal, and threat circuits are predicted but carry a confidence differential inherited from Chapter 3’s fMRI signal-quality assessment), no individual variation in cortical prediction (the persona layer compensates on the behavioral side, not the neural side), 1 Hz temporal resolution (sub-second dynamics are smoothed), and limited behavioral measurement (platform metrics only, no biometric data). These limitations constrain every application in both section 2 and section 3.
The concrete measurable examples throughout this chapter - the effect sizes, the experiment counts, the percentage improvements - are illustrative projections, not measured outcomes. They are calibrated to be plausible given the framework’s design and the published evidence base, but they have not been observed. The framework has not yet run a single experiment. The numbers will be different when real data arrives - possibly better, possibly worse, possibly zero if the bets fail. The reader should treat them as “what the framework’s design implies would be measurable if it works,” not as “what the framework has measured.”
8. Good-Intention Applications Summary
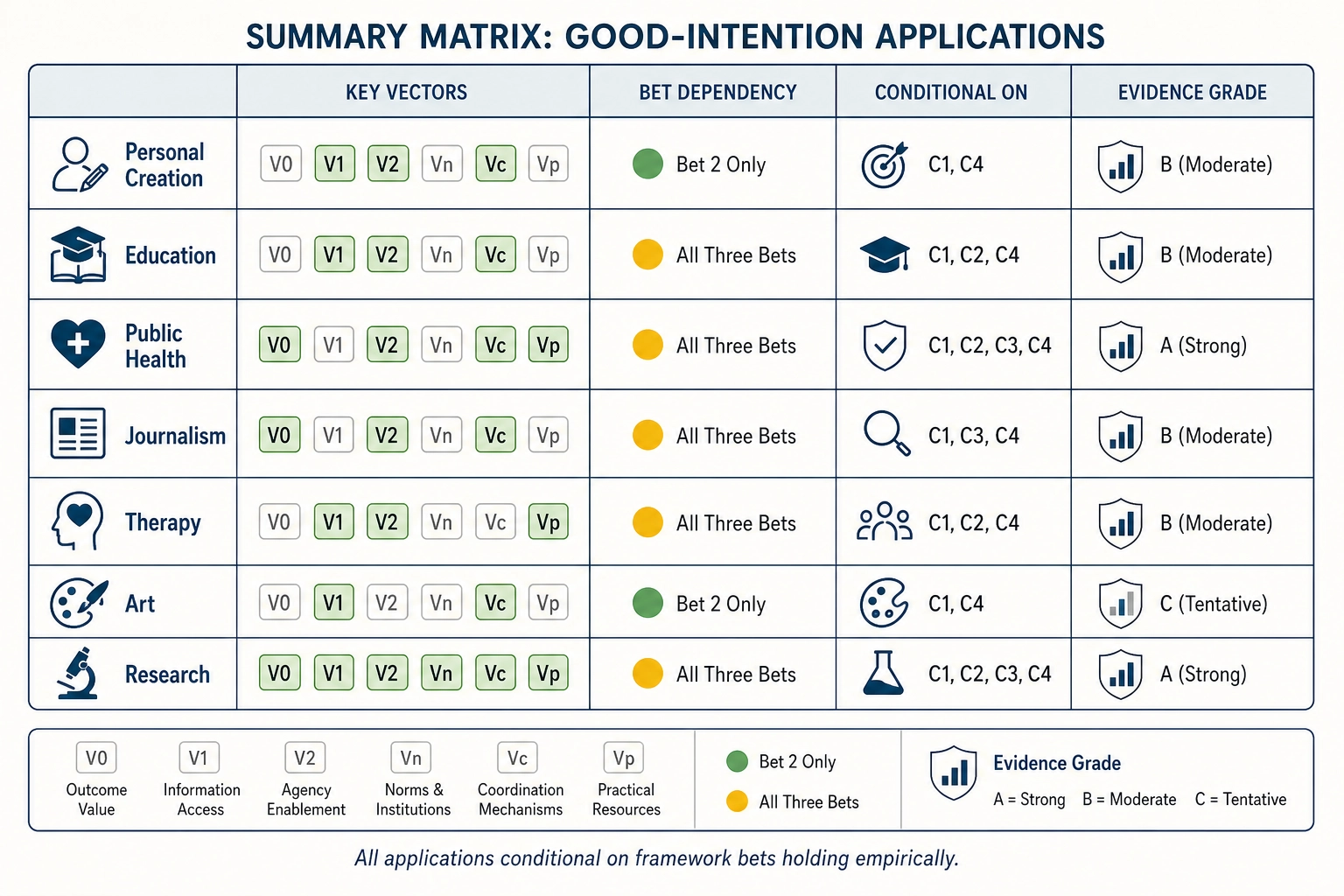
The table below summarizes each good-intention application from section 2, the key measurement vectors it depends on, which of the three bets must hold, and the additional conditions that gate feasibility.
| Application | Key vectors used | Bet dependency | Conditional on |
|---|---|---|---|
| Personal content creation | V₀, V₁, V₂ (physics), Vₙ (cortical), Vₚ (behavioral) | All three bets | CC BY-NC 4.0 license resolution for commercial use; persona resolution for per-audience insight |
| Education | Vₙ (cortical prediction of DMN, Broca’s), Vₚ (completion, quiz scores) | Bet 2 for prediction; all three for mutation testing | Access to behavioral outcome beyond platform metrics (quiz performance); student population persona clustering |
| Public health communication | Vₙ (FFA, TPJ, DMN prediction), Vₚ (click-through, share, completion) | Bet 2 minimum; all three for full optimization | Sufficient campaign budget for 10-20 controlled variants; replication across campaigns for actionable evidence |
| Journalism | Vₙ (DMN vs. ventral attention balance), Vₚ (completion, share, comment sentiment) | All three bets | Journalist willingness to run 1-2 mutations per episode; accumulation of 50-100 experiments for reliable causal graph |
| Therapy and wellbeing | Vₙ (DMN, dorsal attention network), Vₚ (completion, replay, save rate) | Bet 2 for cortical pattern; all three for mutation testing | Published neuroscience on neural correlates of target psychological states; behavioral proxies as indirect measures only |
| Art | Vₙ (full cortical map), V₀/V₁/V₂ (physics properties) | All three bets | Artist’s own aesthetic framework for interpreting cortical maps; no engagement optimization, cortical-pattern matching instead |
| Research | V₀/V₁/V₂, Vₙ, Vc, Vₚ (full pipeline) | All three bets for full pipeline; Bet 2 alone for hypothesis generation | CC BY-NC 4.0 aligned with non-commercial academic use; targeted fMRI confirmation studies for validation |
9. What This Does NOT Say
The applications listed in this chapter are conditional projections, not endorsements. Every application in section 2 depends on one or more of the framework’s three bets succeeding empirically. If the bets fail, the applications collapse to semantic-level creative analysis that already exists in the market. This chapter does not endorse any specific use case - it enumerates what the framework’s design implies would be possible, and it does so for both constructive and destructive intent. The dual-use risk described in section 3 and section 4 is inherent to the knowledge itself. It cannot be prevented by framework design, by licensing, or by good intentions. Any tool that predicts how physical stimulus properties affect cortical activation and behavioral response can be used to help or to exploit. The author states this not as a warning that can be resolved but as a structural fact that honest disclosure requires.
10. Khozai Implication
The applications in sections 2 and 3 share a single hypothesis: that physics-level content properties, mediated by predicted cortical activation, carry signal about behavioral outcomes that semantic-level analysis misses. If this hypothesis is wrong - if semantic tagging captures all the actionable variance - then every application in this chapter reduces to what existing creative intelligence platforms already provide, and Khozai adds no new capability. If the hypothesis is right, the specific implication is not that Khozai creates new capabilities, but that it makes the mechanism layer explicit. The creator learns not just “this works” but “this works because it shifts predicted activation in these cortical regions for this behavioral persona.” Whether that mechanistic transparency changes how people create content, and whether it changes outcomes, is an empirical question the framework is designed to test.
Conclusion

This chapter enumerated what the framework would make possible if it works as designed: seven constructive applications and six destructive applications that share every mechanism except intent. Every application is conditional on the framework’s three bets holding empirically, and none has been demonstrated as of April 2026.
The dual-use comparison in section 4 makes the structural point: the mechanism column and the framework-output column are identical across every row. The only column that differs is intent. This is not a defect the framework could fix by design - it is a property of any tool that measures how stimulus properties affect neural activation and behavioral response.
The question this chapter leaves open is temporal: what happens when this knowledge - currently distributed across published neuroscience, open-source engineering, and proprietary platform systems - becomes widely accessible? The dual-use reality described here is a snapshot of capabilities. Chapter 13 asks what the trajectory looks like across five, ten, and twenty years, and who develops the understanding first.
Bibliography
[1] Falk, E. B., Berkman, E. T., & Lieberman, M. D. From Neural Responses to Population Behavior: Neural Focus Group Predicts Population-Level Media Effects. Psychological Science, 23(5), 439-445, 2012. [EMPIRICAL] Used in: section 2 (brain-based prediction of population-level content outcomes).
[2] Scholz, C., Chan, H.-Y., Falk, E. B., et al. Brain Activity Predicts Persuasive Message Effectiveness Across Multiple Content Domains. PNAS Nexus, 4(11), 2025. [EMPIRICAL] Used in: section 2 (mega-analysis confirming cross-domain neural prediction, 16 fMRI datasets, 572 participants).
[3] Venkatraman, V., Dimoka, A., Pavlou, P. A., et al. Predicting Advertising Success Beyond Traditional Measures: New Insights from Neurophysiological Methods and Market Response Modeling. Journal of Marketing Research, 52(4), 436-452, 2015. [EMPIRICAL] Used in: section 2 (neurophysiological prediction of advertising effectiveness).
[4] Tong, L. C., Acikalin, M. Y., Genevsky, A., Shiv, B., & Knutson, B. Brain Activity Forecasts Video Engagement in an Internet Attention Market. PNAS, 117(12), 6936-6941, 2020. [EMPIRICAL] Used in: section 2 (brain activity predicting real-world video engagement).
[5] Craig, A. D. How Do You Feel? Interoception: The Sense of the Physiological Condition of the Body. Nature Reviews Neuroscience, 3(8), 655-666, 2002. [REVIEW] Used in: section 3 (interoceptive awareness and anterior insula as cortical access point for bodily states).
[6] Yue, X., Vessel, E. A., & Biederman, I. Lower-Level Stimulus Features Strongly Influence Responses in the Fusiform Face Area. Cerebral Cortex, 21(1), 35-47, 2011. [JOURNAL] Used in: section 2.1 (grounding the FFA-size scaling link through lower-level stimulus feature effects).
[7] Berkman, E. T. & Falk, E. B. Beyond Brain Mapping: Using Neural Measures to Predict Real-World Outcomes. Current Directions in Psychological Science, 22(1), 45-50, 2013. [JOURNAL] Used in: section 2.3 (neural predictors at population level with limited individual-level power).
[8] Murphy, K., Bodurka, J., & Bandettini, P. A. How Long to Scan? The Relationship Between fMRI Temporal Signal to Noise Ratio and Necessary Scan Duration. NeuroImage, 34(2), 565-574, 2007. [JOURNAL] Used in: section 3.1 (subcortical fMRI signal-quality limitations).
[9] Ojemann, J. G. et al. Anatomic Localization and Quantitative Analysis of Gradient Refocused Echo-Planar fMRI Susceptibility Artifacts. NeuroImage, 6(3), 156-167, 1997. [JOURNAL] Used in: section 3.1 (subcortical fMRI susceptibility artifacts).
[10] Griffiths, M. D. A ‘Components’ Model of Addiction Within a Biopsychosocial Framework. Journal of Substance Use, 10(4), 191-197, 2005. [JOURNAL] Used in: section 3.1 (addiction depends on context, individual vulnerability, and reinforcement schedules).
[11] Kuss, D. J. & Griffiths, M. D. Online Social Networking and Addiction: A Review of the Psychological Literature. International Journal of Environmental Research and Public Health, 8(9), 3528-3552, 2011. [REVIEW] Used in: section 3.1 (behavioral addiction research on context and vulnerability factors).
[12] Liu, Z. et al. Monolith: Real Time Recommendation System With Collisionless Embedding Table. arXiv:2209.07663, 2022. [PREPRINT] Used in: section 6 (TikTok’s Monolith recommendation architecture).
[13] Meta Engineering. Andromeda: Meta’s Next-Gen Personalized Ads Retrieval Engine. Meta Engineering Blog, 2024. [BLOG] Used in: section 6 (Meta’s Andromeda ads retrieval system).